若您关注过 Apache Iceberg 的最新进展,可能已听闻其引入了类似 Delta Lake 的 Deletion Vector(DV),并在读时合并(MoR)表中弃用定位删除(positional deletes)。Apache Iceberg 格式规范版本 3(format spec 3)对 MoR 表的行级删除处理机制进行了重大调整。在 Iceberg 格式规范版本 2(format spec 2)中,MoR 支持两类删除操作:Positional DeletesEquali w397090770 4个月前 (07-25) 181℃ 0评论0喜欢
0 引言排序是计算机科学中研究最深入的问题之一。高效排序算法的研究主要集中在缓存效率、减少分支预测错误、并行性和最坏情况模式等关键问题上,但主要限于对大型整数数组进行排序。数据库系统研究主要关注许多相同的问题,并且数据库系统具有一些最实用的排序用例:ORDER BY 和 WINDOW 等算子需要明确使用到排序。因此 w397090770 8个月前 (03-28) 310℃ 0评论2喜欢
在C++的智能指针体系中,std::shared_ptr因其自动化的引用计数管理而广为人知,但它并非适用于所有场景。当我们需要更高的性能、更细粒度的控制,或需要与某些已有引用计数机制的对象交互时,boost::intrusive_ptr(侵入式智能指针)便成为更优的选择。本文将深入探讨boost::intrusive_ptr的核心思想、使用场景及具体实现,并通过代码示 w397090770 9个月前 (03-06) 217℃ 0评论2喜欢
当 Presto CPP 接收到新的 Task 时,它会根据以下几个规则创建一个四级层次的 MemoryPool:1、首先,系统会为该 Task 创建一个 Query 级别的 root MemoryPool,由 QueryCtx 维护, 这个内存池的最大容量(capacity)由 query_max_memory_per_node 或 query.max-memory-per-node 参数决定,其默认值为 4GB;如果同一查询下的其他任务被分配到这个 Worker,那么将重复 w397090770 9个月前 (03-02) 273℃ 0评论0喜欢
在大数据处理领域,数据的高效读取和处理至关重要。Gluten作为一个强大的大数据处理优化框架,在Table转换方面有着精妙的设计。其中,主要有三个关键的Transformer,分别是BatchScanExecTransformer、FileSourceScanExecTransformer和HiveTableScanExecTransformer,它们各自对应着不同的应用场景和实现逻辑,下面我们将深入探讨它们的特性和工作原理。 w397090770 9个月前 (02-27) 362℃ 0评论0喜欢
历史背景与演进动因V1 API的诞生与局限性Spark早期版本(1.x)的**V1 API**基于Hadoop生态构建,核心设计目标是兼容HDFS存储系统和传统MapReduce作业。其核心抽象`HadoopFsRelation`和`RDD`为文件型数据源提供了统一的访问接口,但存在以下问题:接口冗余:开发者需要同时实现`RelationProvider`、`FileFormat`、`HadoopFsRelation`等多个接口。优 w397090770 9个月前 (02-27) 415℃ 0评论1喜欢
引言 Java Native Interface(JNI)是Java与C/C++等本地代码交互的核心技术。在传统的JNI开发中,开发者通常通过“静态注册”方式绑定Java方法与本地函数,但这种方式存在命名冗长、灵活性差等问题。而通过JNI_OnLoad实现的动态注册,则能显著提升代码的可维护性和性能。本文将通过一个完整的实例,详细讲解JNI动态注册的实现方法、 w397090770 9个月前 (02-18) 465℃ 0评论0喜欢
Apache Gluten 是一个开源的高性能向量化执行引擎,旨在提升大数据处理框架(如 Apache Spark)的查询性能。其核心目标是通过优化数据处理的底层执行过程,减少 CPU 和内存开销,从而显著加速复杂分析任务。Gluten 通过集成 Velox(Meta 开源的向量化计算库)作为默认后端,利用列式内存格式和 SIMD 指令实现高效计算,同时兼容 Spark 的 w397090770 10个月前 (02-05) 622℃ 0评论1喜欢
花括号初始化是C++11中一种统一的数据初始化方法。因此,它也被称为统一初始化。可以说,这是C++11中开发者应该理解和使用的最重要的特性之一。它消除了之前在初始化基本类型、聚合类型和非聚合类型以及数组和标准容器之间的区别。准备工作要继续本教程,你需要熟悉直接初始化(使用一组显式的构造函数参数来初始化 w397090770 10个月前 (01-25) 256℃ 0评论1喜欢
摘要现代查询优化器的一个重要特性是能够生成一个对底层数据集最优的查询计划。这需要估计中间查询计划节点的基数和计算成本,这高度依赖于查询的写法和底层数据分布。传统方法包括在基础表上收集统计数据并在优化器内部实现基数和计算成本的推导,这对于复杂查询容易出错。本文介绍了 Presto 的新颖基于历史的优化框架 w397090770 10个月前 (01-25) 369℃ 0评论0喜欢

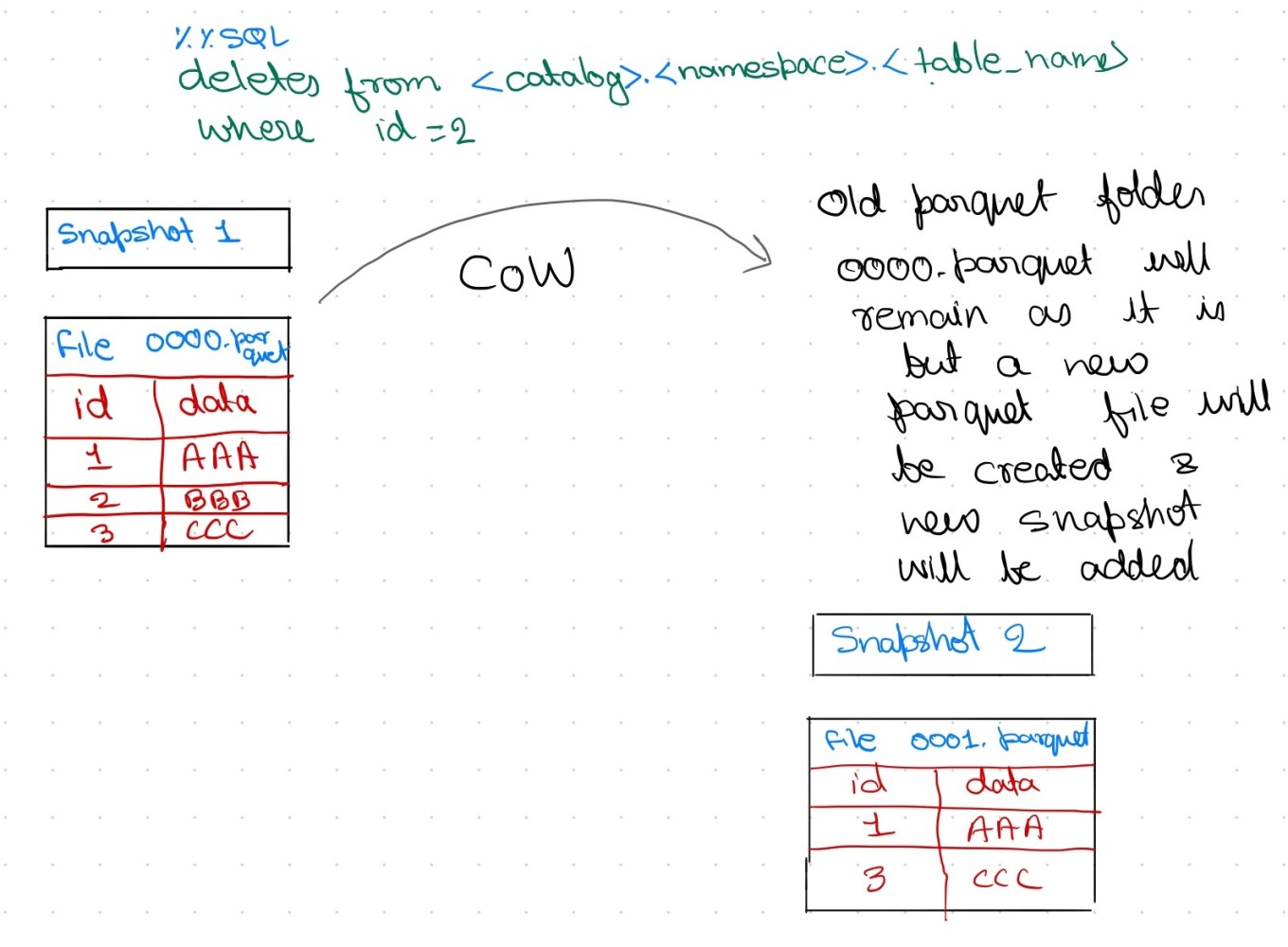


,拿走就用!")











