文章目录
导读:京东OLAP采取ClickHouse为主Doris为辅的策略,有3000台服务器,每天亿次查询万亿条数据写入,广泛服务于各个应用场景,经过历次大促考验,提供了稳定的服务。本文介绍了ClickHouse在京东的高可用实践,包括选型过程、集群部署、高可用架构、问题和规划。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:过往记忆大数据
应用场景和选型
京东数据分析的场景非常多,在交易、流量、大屏、用户分析和算法等多场景中采用到了OLAP技术。那么在应用中有遇到什么样的难点,应对这些问题如何做的技术选型和最终方案呢?
京东OLAP的场景的难点
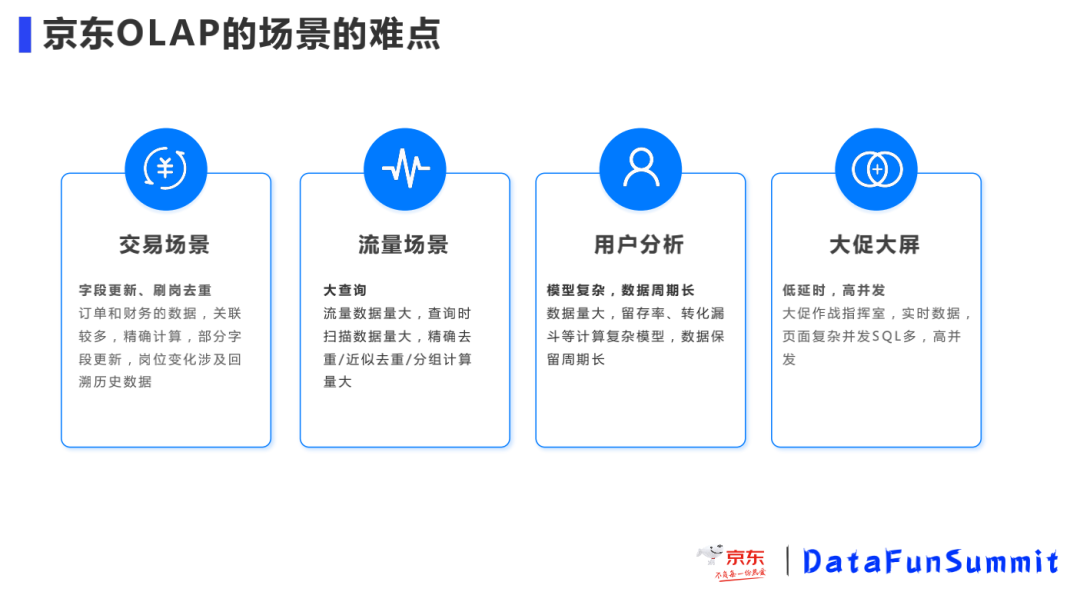
交易数据:零售的订单和财务数据,查询需要多表关联和大量的精确计算,数据字典和组织架构的变化会涉及回溯历史数据,如<岗位,sku,订单>三元组中,岗位会频繁变化,变化之后需要按照最新岗位去查询相关订单的数据,岗位和SKU的量还比较大,如果是大宽表则历史数据都要更新,如果是关联表则关联查询性能是一个较大的问题。
流量数据:流量数据包含浏览和点击,数据量大,查询时扫描数据量大,精确去重/近似去重/分组计算量大,大查询会导致资源消耗比较多,如果并发较大,集群资源会存在瓶颈。
用户分析:在分析场景涉及到像留存率、转化漏斗等计复杂的数据计算模型,分析的维度并不固定因此也无法做预计算,分析覆盖的数据周期较长,明细数据的大查询较多。
大促大屏:每次大促时作战指挥室有大屏轮播展示各类核心指标,一块屏上需要展现很多指标,SQL多并发较大,数据都是亚秒级实时变化,另外大屏对可用性的要求也很高。
多维分析组件选型考察方面
上面我们介绍了OLAP技术在京东一些场景中的难点,基于眼前的这些问题,那么在多维分析中通过哪些考量来做OLAP组件的选型呢?
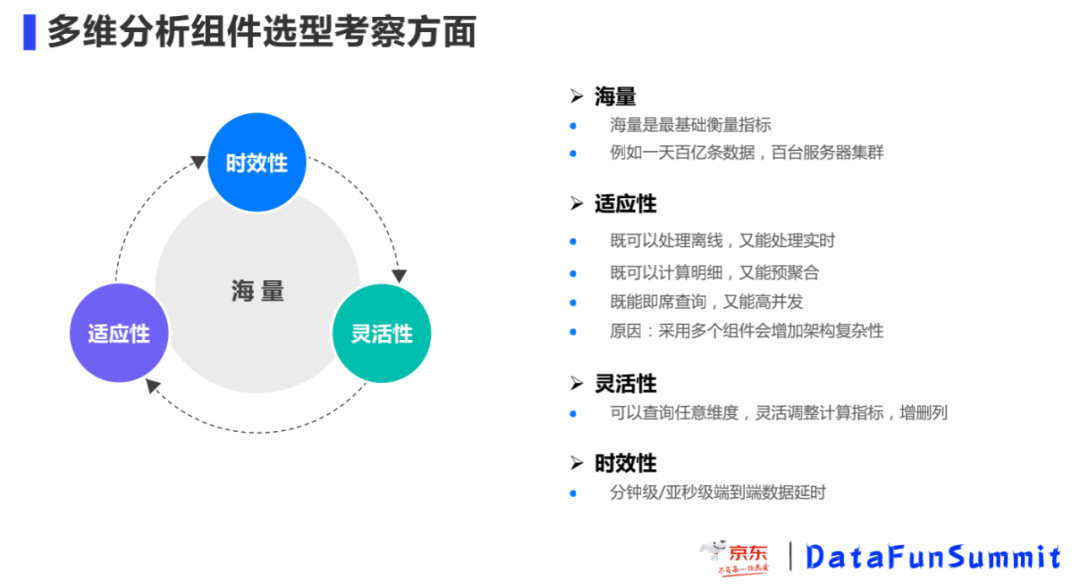
海量:是衡量OLAP最基础的指标,扩展性要好,是否可以支持单集群百台以上服务器,支撑每天百亿+的数据分析计算。
适应性:选择的组件可以覆盖到大部分的分析场景,不需要通过增加其他额外的组件来支持多样化的业务需求,致使架构的复杂性提升。
灵活性:能够在任意维度上进行组合,灵活的调整数据指标,动态增删列,很好的响应业务需求。
时效性:比如做到分钟级/亚秒级端到端数据延时,让相关人员能够即时的看到决策效果,并做响应的调整。
京东OLAP组件实施思路

在对OLAP组件考量和调研之后,和大多数公司一样选用主流的ClickHouse和Doris作为京东内部主要的OLAP引擎,因为ClickHouse性能、扩展性和稳定性较好,而Doris在可维护性和易用性方面更好,所以在生产中选择了以ClickHouse为主Doris为辅的策略,形成高低搭配。同时,针对开源产品后台功能不强的情况,通过自研管控面来进行集群管理,用户自助式操作,降低了运维成本,降低了用户的使用门槛。
集群部署
集群部署方面主要是通过业务隔离、多租户配额、机型适配和灵活部署方案来运维高可用的集群。规划合适的集群规模是第一个需要考虑的问题,我们通过综合对比后选择了小集群多租户的模式。集群部署主要有三大模式:大集群、独立集群和小集群。
大集群,指部署少量几个规模大的集群,集群规模达几百台甚至几千台,各产品模块一起使用,这种情况适合场景一致且数据量巨大的业务,缺点是隔离性差,各模块间容易相互影响,另外ZooKeeper的局限会让大集群的运维和使用较为复杂。
独立集群,针对不同的业务线部署单独的集群,优点是隔离性很好,过渡或错误使用对其他人没有影响,但是增加了运维成本和资源的浪费,比如集群版本管理和升级,集群的扩容和缩容会是很大的工作量,不同集群之间的资源使用并不均衡造成浪费。
小集群,相似业务共享一个集群的模式,每个集群的规模中等,规避了ZooKeeper的瓶颈,同时隔离性较好出现问题风险也比较可控,通过配额来限制业务使用量也可以灵活调整配额以适应业务发展,同时集群数量也不是很多,维护的成本不是很高。
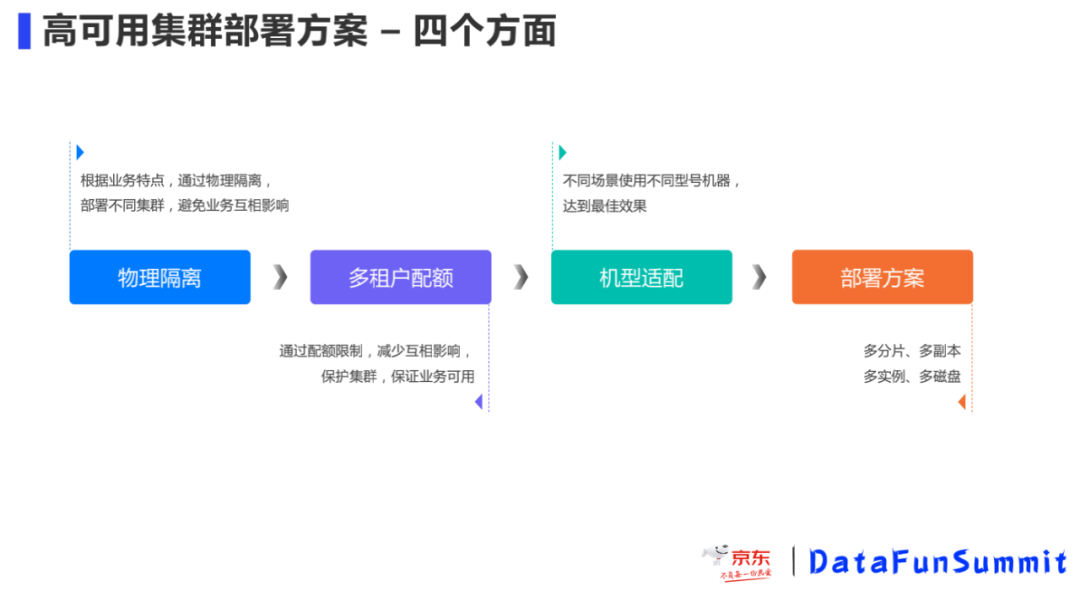
那么在小集群多租户模式中又是怎样实现高可用的呢,在这还是以下面四点展开:
物理隔离:根据不同业务特点、业务场景通过部署多个集群实现物理隔离,避免业务相互影响,同时资源使用上可以互补。
① 分析性查询和日常报表隔离。分析性查询涉及到大查询和时间跨度比较大的查询,占用大量的资源,可能会影响到其他业务,这两部分业务尽量不要放在一个集群中。
② 高并发和低延迟场景隔离。因为高并发会大量占用集群 CPU 和内存,影响其他业务的查询和写入;低延时隔离,低延时指数据需要秒级写入,会有大量小文件写入,在数据合并中压力比较大,影响其他业务的写入。
③ 业务级别隔离。重要业务需要更高的保障确保高可用,避免因为一些低优先级的业务占用资源导致高优业务出现事故,也可以低优和高优搭配,在集群资源不足时,通过对低优降级支援高优业务。
④ 实时和离线隔离。像离线主要是大存储,大数据量写入时耗费磁盘资源和IO性能,而实时往往是大数据的计算CPU使用率比较高,如果实时和离线的使用量并不是很大,也可以混布,这样可以充分利用资源。
多租户配额:为了保证集群的稳健、业务的高可用、提升资源的利用率以及降低业务间的相互影响,我们通过多租户、配额和权限管理进行限制。我们的目标是通过配额来限制非预期的行为,特别是错误的使用导致集群不稳定。
① 系统限制:设置服务最大内存不超过服务器物理内存的80%,集群总的并行的Query数为CPU核数的2-5倍,避免内存资源不足导致OOM和CPU 负载过高。
② 查询大小:从内存占用、所需的线程数和查询耗时上限制,设置单个的查询占用内存资源为系统资源的20%,单个Query的线程数为CPU核数的20%;查询时长10-30s,写入时长60-180s。
③ 查询次数:限制并发查询数,比如5/节点;或者为了保证高峰数据的稳定性,可以限制20个query/节点/10秒。一般是并发数和query数同时限制。
④ 我们针对账号进行了分离,比如同一个业务分为查询账号、导数账号、下载账号,对各种账号分别设置配额,同时,针对配额我们也是严格先压测在设置符合业务实际需要的配额。
⑤ 读写分离和SQL追踪,在每个SQL的前面有一段/*TraceID*/的跟踪ID是上层生成的,TraceID中包含产品、模块、功能、接口等信息,通过TraceID我们很容易找到慢查询、错误查询等SQL的位置。
机型适配:OLAP中既有存储又有计算,是计算和存储都密集型,离线和实时的场景对机型性能的要求不同,所以按需选择不同的机型,做到资源的合理搭配。
① 资源类型配比要合理。不同场景资源类型的需求是不一样的。按照我们的经验,计算量大的业务,选择CPU核数多主频高的,比如分组和去重的计算;数据保留时间长的业务,磁盘空间则需要大;如果使用字典,数据需要加载到内存,则需要考虑大一点内存。一般来说有一个基线的配置如CPU32核内存64-128G磁盘2-10T。
② 离线推荐HDD磁盘。在离线场景中,需要存储数年的数据,存储空间占用大,一般采用普通机械磁盘,数据在外部排序顺序写入,磁盘写入速度和IO都能满足要求。使用HDD磁盘时,需要坚持小批次大批量的原则,尽量降低小文件对系统的负担,采用大容量的磁盘,一个好处就是可以做一些物化视图,来提升查询性能,以空间换时间。而实时场景,我们一般选择SSD或NVME,随机写入能性能好,可以低延时高频写入小文件,能获得更低的数据延时,更低的IO繁忙率。
③ 优先选择单机性能高。分组或去重计算,需要把全部或部分数据汇聚到少量实例中,然后在汇聚实例中计算,依赖单节点的计算性能,集群相同核数的情况下优先选择CPU核数多和主频高的,比如32核的10台和64核的5台,后者在某些场景下计算性能更优。
部署方案:支持多副本、多实例、多磁盘集群部署
① 如何确定分片、副本数。根据业务存储的量级进行预估分片的数量,尽量让每个分片数据大小控制在在1-10G左右(1M-10M/条),每个分片的磁盘空间不要超过60%;为了保证数据的可靠性,通过配置多副本的方式避免单点故障造成数据不可访问,建议副本数是2个以上、一个副本QPS 大概是10-300,如果QPS特别大,则需要更多的副本,我们单集群QPS最高能达到2000。
② 流行的CH部署方是单实例的,比如5分片2副本,需要10台服务器,每台服务器部署一个节点,如果查询并发少CPU和内存会有浪费。因此,我们采用多实例多副本的部署模式,如下图4台服务器,我们部署了4分片和2副本,当然我们天然也支持单实例多副本的模式。

③ 怎么支持横向扩容。通过增加副本的方式提升实现高可用,增加分片的方式提升写入和读取效率,也可以通过挂载的方式扩容磁盘。增加副本可以把新副本放在新的机器上,达到每个分片的副本数量一致即可。增加新的分片,可以增加Node5和Node6,然后类似Node1和Node2的副本间交叉备份的,就可以增加S5和S6。
高可用架构
通过业务侧规避,架构升级,管控面研发和双流,提升OLAP的高可用性,在京东特别是大促可用性要求很高,有些业务要求5个9左右,但是仍然可能遇到有些挑战,那么我们在架构上需要做哪些努力呢?
单集群高可用架构
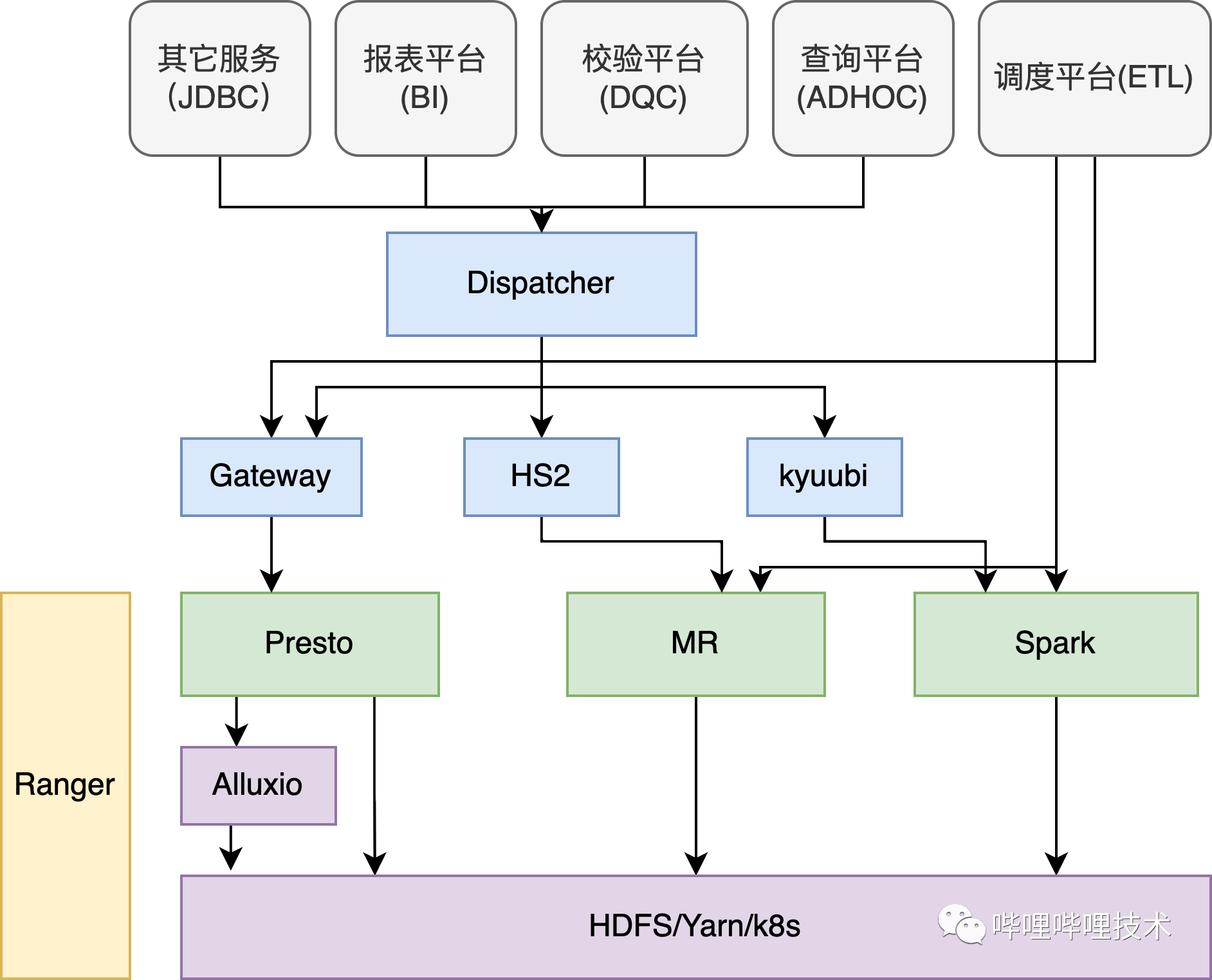
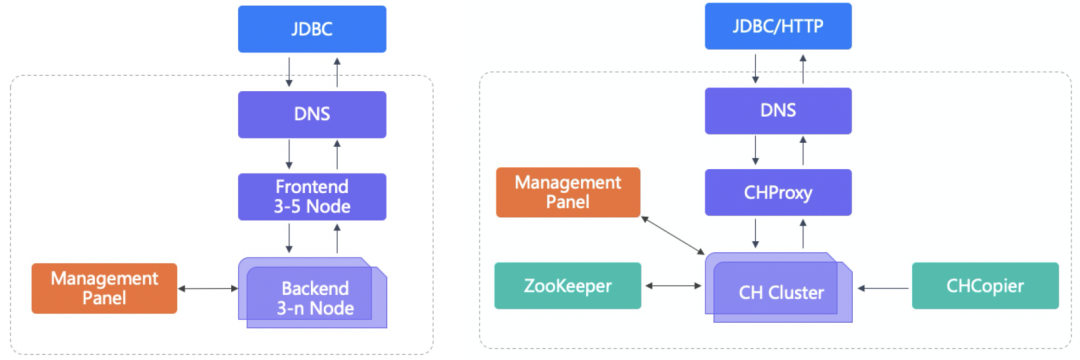
硬件故障是无法避免的,因此如何做到在硬件故障时用户使用上无感知是我们努力的方向。我们部署的CH集群在架构上划分为3层:DNS域名解析、CH代理层、CH集群节点。
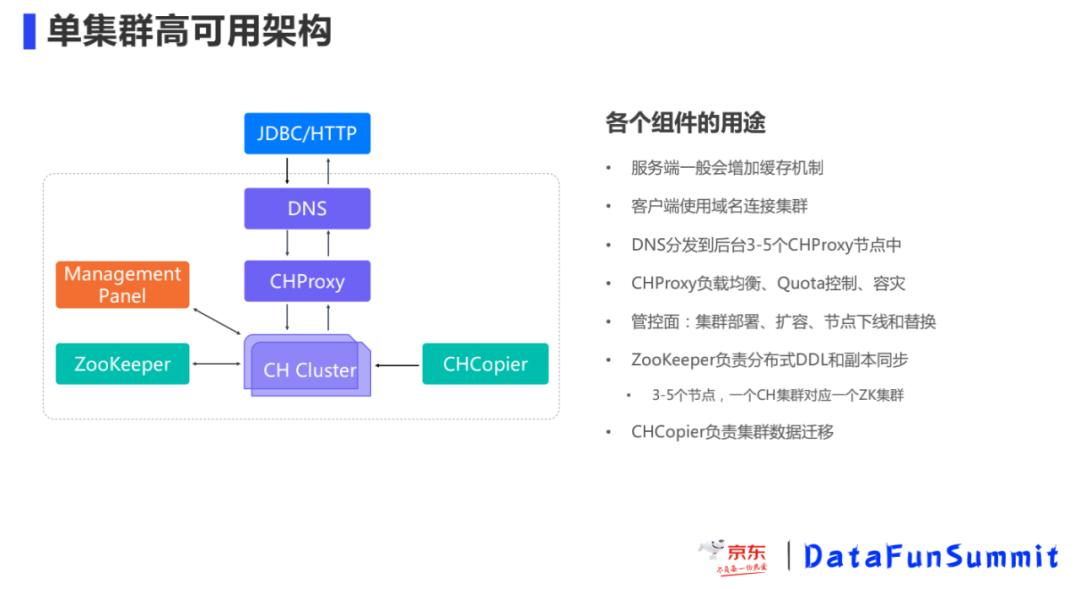
应用层通过JDBC/HTTP方式域名进行请求,DNS域名解析后将请求打到CHProxy,CHProxy根据路由规则做请求分发,即实现了无感知上线下线CH节点同时实现了负载均衡,通过CHProxy的负载均衡和流量分发,我们支持了日均6000亿条数据写入的集群。
Management Panel 集中化管理,负责账号的申请、集群部署、扩容、节点上下线、遇到故障时节点的替换以及提前预警告知等。
ZooKeeper 来负责分布式DDL元数据的更新和副本同步,故障发生时能够尽快的修复,在集群部署时尽量CH集群一一对应,避免在大规模情况下ZooKeeper 共用出现性能瓶颈,一般一个集群是3-5个节点。
CHCopier负责集群数据迁移工作,我们一般使用目标集群的CHCopier来同步源集群的数据。
挂掉一个节点在各种情况下的影响
数据安全,因为是多副本部署,数据有最少一个的备份,挂了一个副本,数据也不会丢失。
查询时,CHProxy会转发到健康节点,故障节点不会收到查询请求。另外,接收查询节点对副本有Load_balancing策略,比如轮询、随机等,同时使用ConnectionPoolWithFailover的逻辑,会对副本进行排序,执行子查询计划时会把子查询发给优先级高的健康副本,故障节点也不会收到子查询请求。
写入时,情况稍微复杂,如通过域名来写分布式表或随机写本地表和查询的机制类似。如果指定分片写入本地表,可以在QUERY中指定分片序号,CHProxy会转发写入到指定分片的某个副本上,同样会跳过故障副本节点。ClickHouse的机制是任一副本写入成功,其他副本会自动同步数据。
DDL操作,当节点挂掉之后故障节点上的DDL操作会失败,抛出异常。有两种方案,一种是不用ON CLUSTER,自己遍历每个节点执行DDL,如果执行失败先记录,等节点恢复了再重新执行一遍,另一种是先下线故障节点,等修复后再上线,或者备用机先进行替换。DDL操作的处理所需的工作量最大。
节点下线、上线、替换
前面说到了节点挂掉后产生的影响,这块看下如何实现节点替换和上下线。
节点下线:修改配置文件,删掉要下线的节点信息,并且下发到所有节点进行通知,节点会重新加载配置文件,完成节点下线,如果是永久下线,还需要清理ZooKeeper中的该节点的副本相关信息。配置下发用salt或ansible,节点清理可以自己写一个工具遍历zk路径。
节点上线:同样将上线的节点信息配置到集群中并下发通知其他节点,但是因为新上线的节点没有元数据信息,因此需要通过工具将ZooKeeper 中其他副本的元数据信息同步过来。
节点替换:在节点上线步骤的基础上,看看如果新节点的IP有变化,也需要在ZooKeeper 中进行更新或者增加。
这有一个通用的节点故障处理流程,即确定是否可以恢复;如果不可恢复,进行节点的下线,可恢复的情况下,定位原因尝试修复,修复完事后进行上线,或者不可修复进行节点的替换。节点上下线和替换,因为步骤较多,手工操作工作量较大,整个过程我们自动化了。
双活集群方案
当集群中但节点故障,我们可以快速的下线节点保证业务的正常,如果发生整个机房的故障问题,需要长时间的排查修复,我们同样有集群双活的保障,分钟级的切换备用集群。
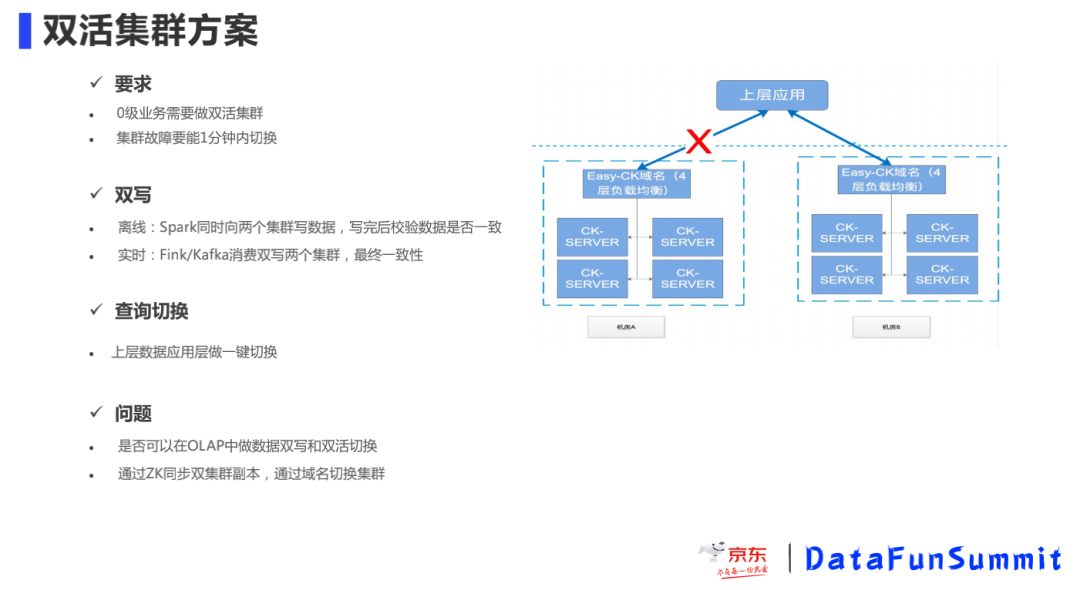
因为双活机房间数据目前离线是通过Spark同时向两个集群写入数据,实时是通过Flink 消费双写两个集群 ,只能保证数据的最终一致性,这种方式对于业务端比较复杂,所以关于能否实现OLAP集群间的双写,通过分布式共识机制同步双集群群副本,通过域名切换集群,这是未来我们要考虑的一个工作。
5. 参数优化 – 系统、ZooKeeper、ClickHouse

京东的场景多数据量大,遇到的问题也多,我们做了大量测试和试验,调整了很多参数包括Linux系统、ZooKeeper和JVM、ClickHouse的调优,通过优化这些参数,可以让集群处于一个高性能稳定运行的状态。如ClickHouse按列存储,小文件比较多,inode数量需要改大一些;如max_memory_usage这个参数避免内存超过限制;如zk中的参数优化会让zookeeper不那么频繁出问题,可以参考官方的配置。
问题和规划
常见问题和解决方案

系统问题:包括通过设置CK内存解决OOM问题;在硬件资源遇到故障时快速的下线节点;注意在Part文件太大时内存文件Cache 会失效。
导数问题:Insert太频繁/Part数太多/分区太多都会导致小文件问题;分布式表写入性能差,数据分发太慢;导数分区不合理Znode数量大;数据字段更新,选择合适的表引擎和方案。
元数据和ZK:DDL卡住/失败可以增加增加DDL线程数解决;ZK和CH元数据不一致,通过轮询检查和修复脚本进行保障,控制Znode规模避免因数量太大引发的超时问题;还有就是在Copier迁移数据ZK压力较大,需要重点关注。
查询问题:CPU不均匀,造成流量分发不均匀和数据倾斜;在查询中通过改写子查询,本地join 以及物化视图的方式改进性能不好的Join查询;大查询的影响,通过Quota限制,命中索引;当并发太大,CPU太高,通过增加Cache的方式缓解。
ClickHouse并发能力,因为CH是MPP架构,分布式表的查询会分发到所有节点去执行,每个分片的节点都会参与计算,并发能力和单机是一样的,增加副本可以提升并发能力。另一方法是提升单个查询的查询性能,比如通过改写SQL、物化视图或者字典表的使用降低查询时间。在查询时间优化到几十毫秒以内,增加副本数可以让QPS达到数千甚至上万。
ClickHouse Join优化,CH的Optimizer不够自动化,很多SQL需要显式的指定执行顺序和优化参数。我们之前做过ClickHouse的TPC-DS的测试,大部分多表Join的SQL都需要改写,比如把Join改为子查询,改为本地表Join,设置distributed_group_by_no_merge去做分布式GroupBy等,改写之后的性能比较好,但大表和大表的Join在右表数据量达到千万级别之后,性能会急剧下降。
架构问题 – ZooKeeper瓶颈
ClickHouse和ZooKeper是一种松散耦合的架构,执行DDL操作时,每个节点是轮询DDL队列去执行,执行完毕后设置标记,接收到SQL的节点轮询状态直到所有节点执行成功然后返回给客户端,这种模式和大部分有Master节点的分布式系统稍有不同,如Kudu和Doris。
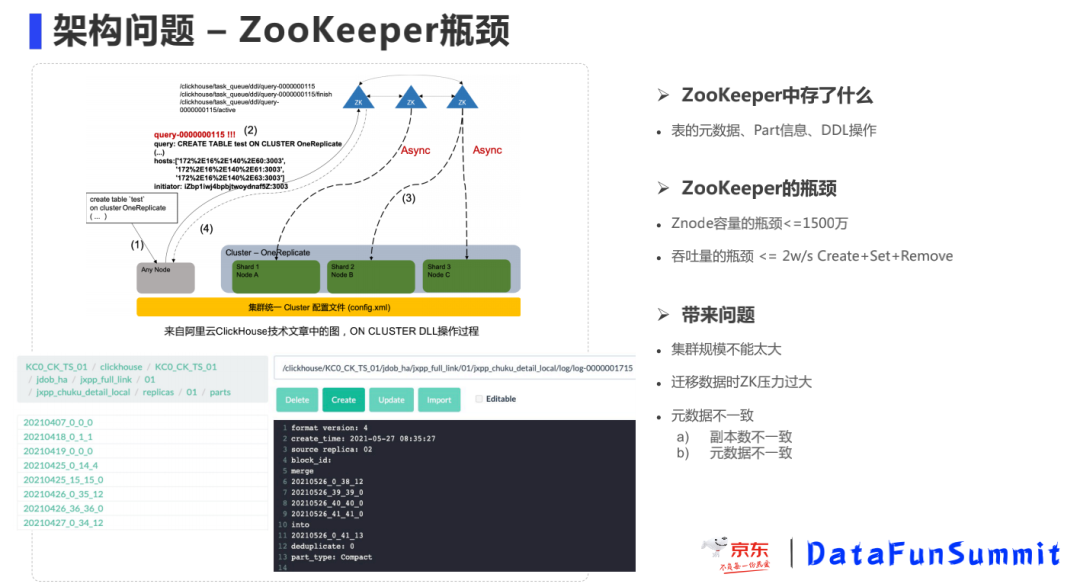
ZooKeeper存在性能瓶颈,ZooKeeper存储了表元数据、副本、Part信息、Merge和Mutation日志以及DDL队列,Znode数量是随文件数量而增长的,如果Znode数量太大,GC时卡顿导致操作延时较大,Znode应当小于2000万左右,吞吐量的瓶颈3w/s左右。理论上,是可以通过不同节点访问不同的ZK集群来分散压力,但是这种方式较为复杂。
ClickHouse分布式能力偏弱,如果用过Doris之后,再来看ClickHouse的分布式能力的话,ClickHouse在节点管理、元数据管理、事务管理、弹性伸缩等方面较为简陋,需要做大量的工作去运维。比如在Doris中,可以通过SQL命令增加、退休和删除节点;后台同步元数据让元数据在节点中始终保持一致;两段提交的事务机制,保证数据导入的原子性;同时扩缩容,后台会自动同步文件,让集群中的数据处于均衡状态。
架构问题 – 扩缩容的问题

主要是扩副本和扩分片进行扩容,前面已经简单介绍过:
横向扩副本:直接修改配置文件,增加副本信息,然后在ZooKeeper手动的注册,之后台专门的线程会将主副本数据进行同步,操作时应该按分片逐步滚动操作,避免同时同步数据压力太大。
纵向扩分片:也扩副本方式类似,分片比较好扩展,但是扩分片之后旧分片数据没法自动均衡,这块社区也正是在改进,我们有计划在社区基础上,进行工具化研发,能够在后台在线进行数据均衡。
未来规划
短期:统一的元数据管理
为了解决上面的问题,我们目前正在开发基于Raft分布式共识算法的ZooKeeper替代方案,一方面是提升吞吐量和容量,另一方面是需要和ClickHouse结合更加紧密,保存更多元数据类型以增强CH的分布式能力,比如节点状态,元数据管理,副本、分区和文件信息,并在此基础上形成弹性扩缩容的能力,集群迁移和备份恢复能力,以及跨数据中心数据复制能力。
中期:OLAP管控面加强
在使用CH和Doris的过程中,特别是大促的经历,让我们积累了大量的运维和故障处置脚本,我们正在把这些脚本进行产品化,让用户自助式使用OLAP,如资源申请,创建用户和库,自助式的监控报警,异常处理和性能诊断,对管理员侧,做到集群部署和管控,以及故障自动诊断和治愈。管控面的产品化,降低了运维的工作量,提升了人均可维护的集群和机器数量。
长期:云原生的OLAP
在容器化部署的同时,进一步实现云原生,利用HDFS和对象存储的优势,甚至可以和数据湖对接,把存储层放到外部,避免数据的重复存储,节省导入时间,计算节点可以弹性扩缩容。存储分离出来之后,存储如何扩缩容,以及计算节点和存储分片之间如何映射,本地数据如何缓存等都是新的问题,这块需要继续研究。
其他方面如查询优化、分布式缓存、易用性提升等也都在规划之中。截止目前为止,京东OLAP集群的规模有将近3000台服务器,每天8千万次查询,1万亿条数据写入,总计3PB的数据规模,覆盖交易、流量、算法等场景,同时我们也积极参与和回馈社区。京东OLAP采取了ClickHouse和Doris双引擎策略,两个引擎都有深度使用,近期会发布深度详细的对比文章,从内核、性能、功能到运维都会涉及,敬请期待。
今天的分享就到这里,谢谢大家。
分享嘉宾:

原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【京东 ClickHouse 高可用实践】(https://www.iteblog.com/archives/10021.html)