

文章目录
导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。
Impala的架构
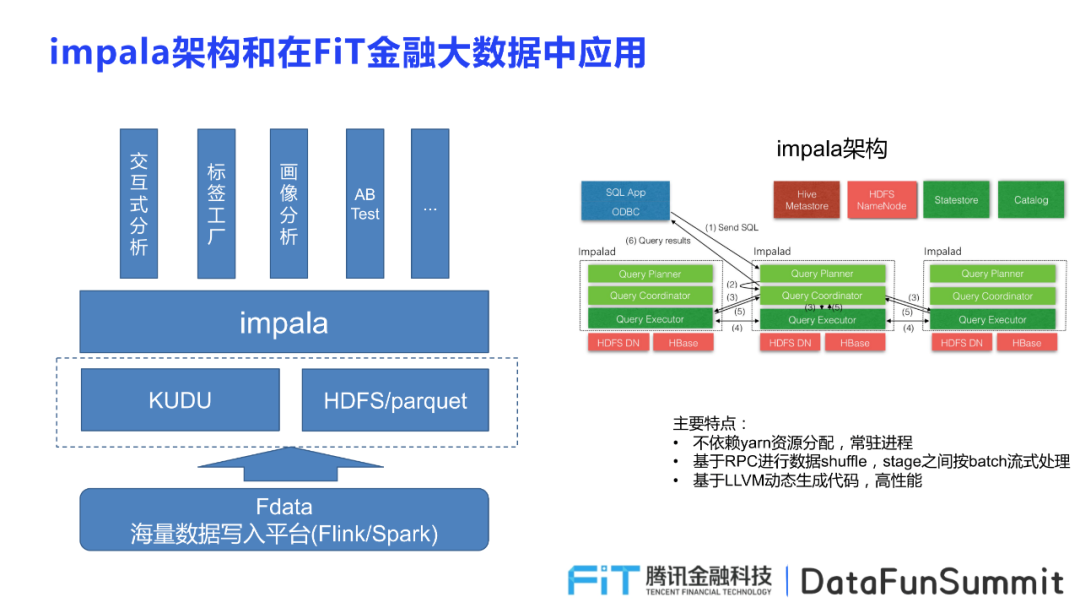
首先介绍Impala的整体架构,帮助大家从宏观角度理解整个Impala系统,掌握框架上的知识和概念。
Impala存储的方式分为两种分别是Kudu和HDFS,其中Kudu实时点击流的场景,HDFS存储大多数据。
Impala应用包括以下几类:
交互式分析:主要指对用户进行多维数据分析,进行数据建构;
标签工厂:允许业务人员根据不同用户属性和事件属性进行标签的构建,生成各具特性的标签集合,供业务具体使用;
画像分析:生成用户包并将其提供给业务人员,允许其查看用户的标签,为具体的业务工作提供参考;
ABTest:在ABtest中,提供数据分析支撑,提高运行速度,增添效率。
Impala的主要特点:Impala是在Hadoop大数据的框架中构建查询引擎,并主要依赖Hive和HDFS的组建,并通过Fdata将海量数据写入平台,从而为业务方提供高效便捷的数据查询功能。
不依赖yam资源分配,常驻进程;
基于RPC进行数据shuffle,stage之间按batch流式处理;
基于LLVM动态生成代码,高性能。
在从宏观角度整体了解了Impala的架构之后,接下来,为大家介绍Impala的两个重要原理,分别是并发原理和基于CBO的表关联优化原理。
Impala的并发原理
线程的分层
主要包括三类,分别是实例线程,数据扫描scan线程(解压缩),io线程。在impala的默认模式下,实现了计算和扫描一对多,扫描层充分开发,但在多线程模式下,在扫描层化为单线程直接使用实例线程,跟计算层构成以实例为单位的开发。
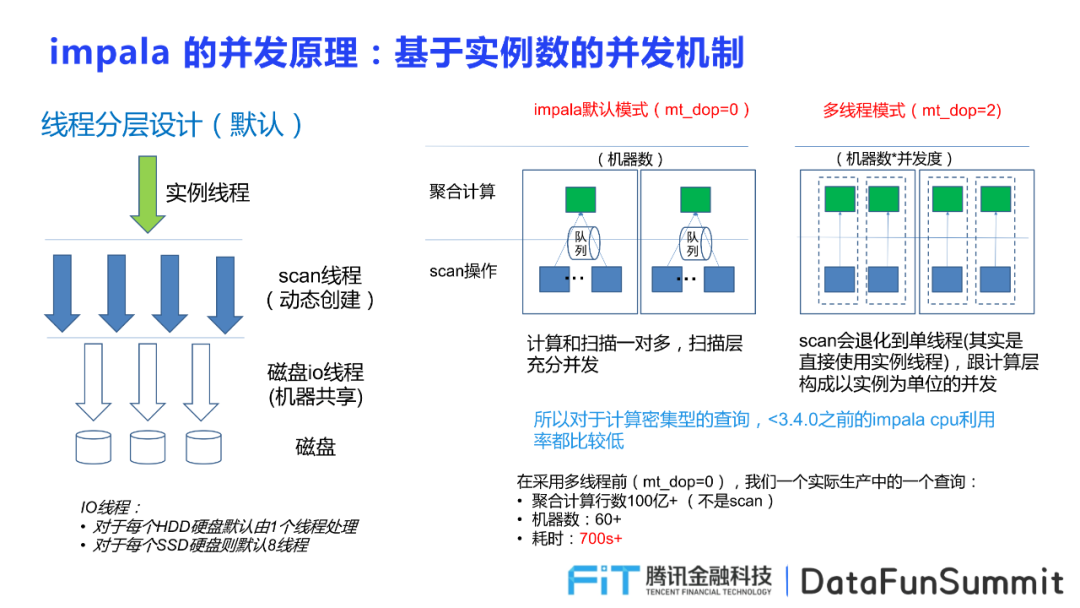
遇到的两个问题
① 高并发下抖动严重,原因出现在RPC相关的EXCHANGE:因为在高并发状态下,数据由sender端push给Receiver端,且Receiver端由BatchQueue进行接受,一旦队列满了或者deferred不为空,就会传输给deferredRPCS,因此极容易导致队列堆积。
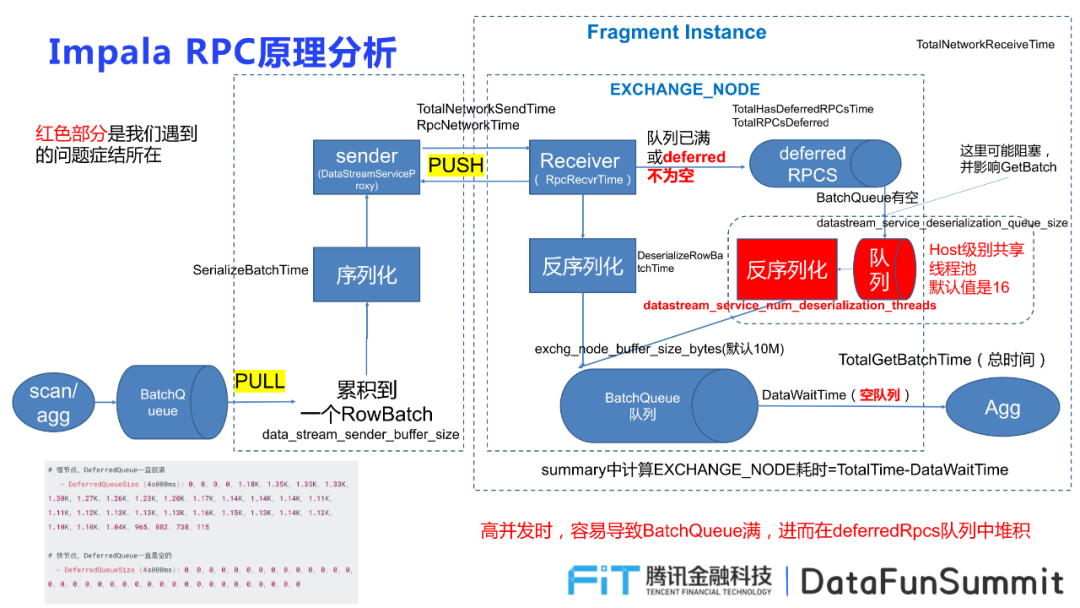
解决方式,首先将参数:
datastream_service_num_deserialization_threads
进行调整,因为机器CPU超线程数为96,所以将该参数调整到80,成功地提高了在高并发状态下地稳定性,提高了数据查询地有效性。
② Cast to string问题,导致并发不增反降,对查询效率带来极大的影响。
并发特性的制约因素
并发的最小颗粒度为文件,因此当表字段比较少,且按照文件大小生成文件,将导致在同一个文件中所包含的行数增多,并发度降低;若选择将文件拆开提高并行度,但获取的数据量变小,导致磁盘的io效率降低。因此从这两方面来说,均制约了Impala的并发。

Impala表关联优化原理:基于CBO(成本优化)
基本工作
运用Impala表关联优化原理,首要是统计信息的采集规则的制定,包括行数,字段的选择,以及join类型的选择,是broadcast,partition,顺序的选择,是大表在左还是小表在左;
基于平均分布对每个关联子表的数据量进行预估,并判断大小表从而选择合理的顺序。

三个问题
① Outer join出现数据倾斜,采取轴心表策略控制join的顺序,提升效率。
比如因为两表做了两次的exchange,所以A表join B表之后重新exchange导致大量NULL数据倾斜,对于这一问题采取的解决方案是轴心表策略,从join的顺序上控制数据的问题。该策略是基于RBO规则的,首先结合CBO预估子查询的数据量,以某个子查询为轴心,将其他的查询以这个表作为首位进行排列,并采用straight_join控制join的顺序,从而顺利解决该问题。并且在优化前后,效率得到了一个极大地提升。

② 多个表group不一致导致多余的exchange,不同地子查询有不同地groupby顺序,频繁地交换数据产出地顺序,带来大量数据冗余,降低了后续相关数据查询地效率,因此解决这个问题需要保证多个表在执行group by顺序一致,才能有效减少exchange地次数,从而提高效率
③ 平均分布假设引发的预估偏差导致broadcast join,因为impala在实践查询之前,会基于平均分布假设预估生成表地数据量,但一旦产生偏差,就会导致broadcast join地发生,从而影响该次查询的效率。
广泛应用
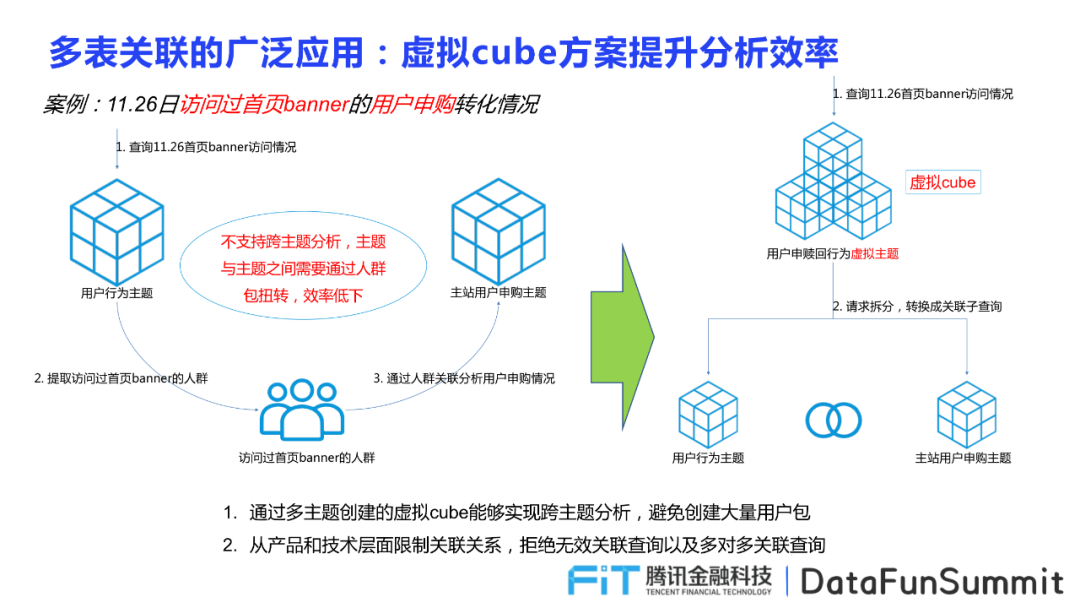
针对跨主题分析的情况,采用多表关联的虚拟cube方案,避免创建大量用户包,并尝试从产品和技术层面限制关联关系,减少无效关联查询和多对多关联查询。
比如需要查询11.26日访问过首页banner的用户申购转化情况,首先需要根据访问11.26首页banner的用户数据,生成用户行为主题,随后提取所有访问过首页banner的人群,通过人群关联分析整个用户申购的情况,申城主站用户申购的主题。这一过程反映了原来的分析模型不支持主题分析,主题和主题之间需要通过人群包进行转化,效率低下。
但在运用了impala的多表关联功能之后,可以将用户申赎回行为的虚拟主题这以请求进行拆分,转换成关联子查询,分为用户行为主题和主站用户申购主题,极大的提高了效率,也避免了人群包的使用,减少数据量的处理。
除了以上介绍的两个基本原理,Impala的存储层实现的原理和应用在整个Impala中也是不可忽视的,接下来为大家介绍的就是其存储层的相关理论和运用。
Impala的存储层
原理
交互式分析引擎的实现思路分为进行预计算,提前计算出所有可能维度组合的结果,或通过即时计算包括建立倒排索引和列式存储统计信息。其中倒排索引是指对匹配的结果进行链表归并或bitmap处理,将每一列独立存储,并在符合olap每次只分析部分列的需求,同时利用统计信息减少io的消耗。在并发度不那么高的背景下,多采用列式存储的原理,因其采用单行组的形式对数据进行存储,可以减少io次数,从而提升QPS。下图为列式存储的抽象表示:
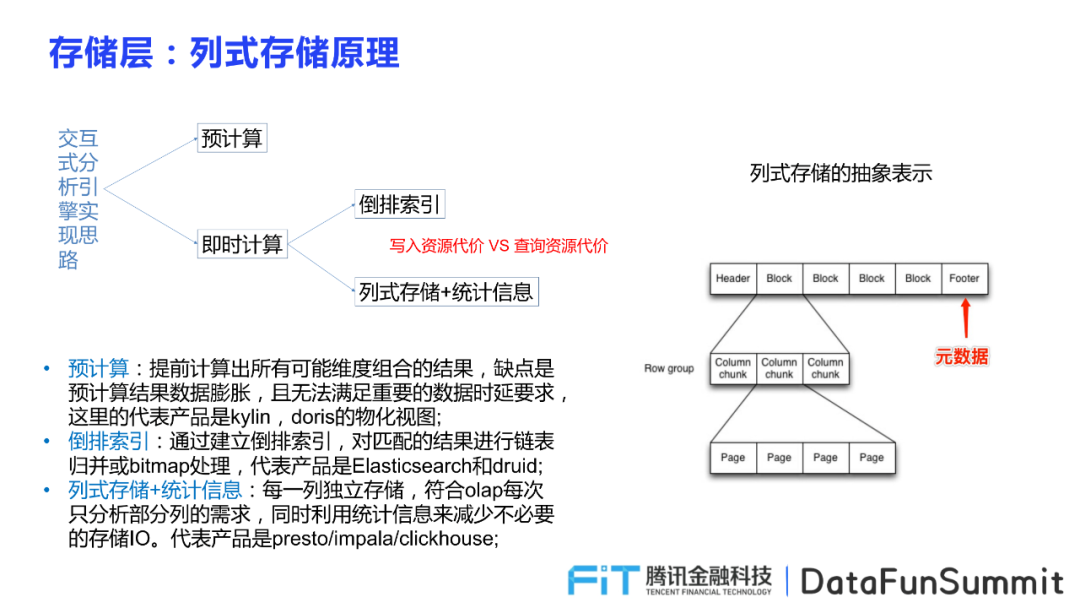
对于性能差异的原因,通过一个例子能够很好的理解,比如一个分区存储150G,供727个文件,平均每个文件211M,一共273列,平均每一列774k。impala再读取的过程中会向scanRange对象中填充读取一个内存块,所以若每次只读一列,只需要一次io,但如果分散再多个行组中就需要多次io,尤其是如果行组太多就同行存无异。因此在一个parquet文件与hdfs的block大小一致,并且仅包含一个row group,可以最大限度地提高QPS和运行效率,避免大量行组导致效率低下地问题。
数据过滤
Impala的存储层有良好的数据过滤体系,主要分三步从行组级统计信息、pageIndex、字典信息三个方面进行最大化的数据过滤,减少io次数。其中前两步都需要考虑profile中的指标,行组中每个列地统计信息包括最大值或最小值等等。第三步字典信息中对于profile重点阿指标只对encode类型进行考虑,包括PLAIN DICTIONARY等并只使用与总数小于4万地情况。
并考虑采取全局排序、hash分区后排序、z-order排序三种方式对数据过滤过程进行优化,提高处理效率和稳定性。
应用
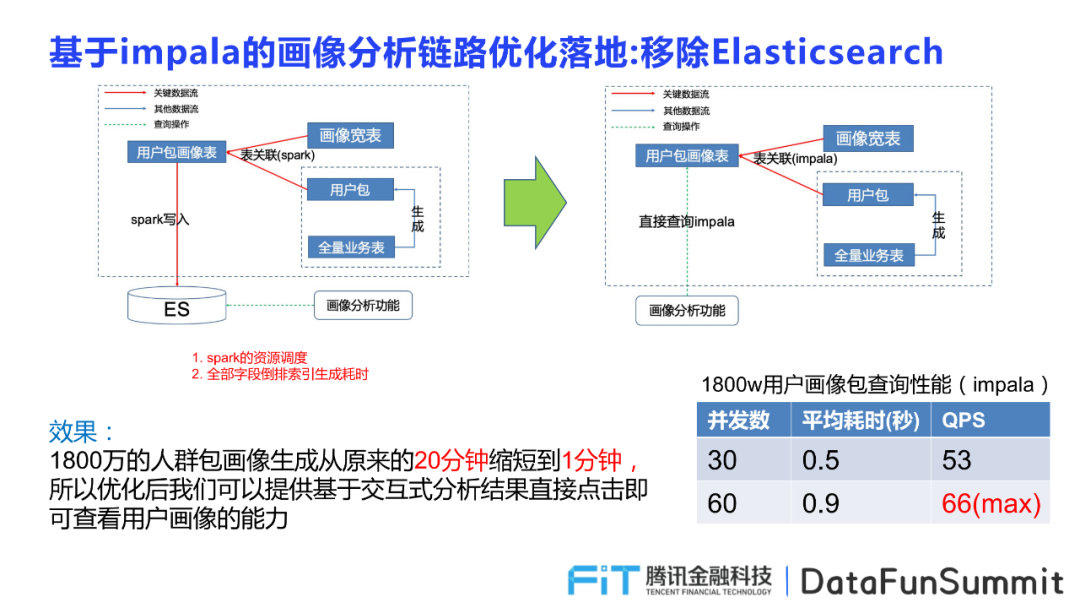
优化前的画像分析需要运用spark进行资源调度,并对全部字段生成倒排索引消耗大量时间,在引入Impala优化后,可以直接进行画像分析。Impala通过用户包画像表直接表关联到画像宽度和依据用户包和全量业务表生成的集合表,提供画像分析功能的使用。基于这一层次x优化落地的功能效果也十分显著,例如针对1800万人群包画像生成时间从20分钟缩短成1分钟,并支持基于交互式结果的直接查看用户画像的能力,性能和功能都得到了极大的提升。
在了解完Impala的整体架构,处理逻辑的原理和存储层的相关理论之后,相信大家都对Impala有了一个更加深入的认识,接下来就为大家提供一些思路的总结。
总结与思考
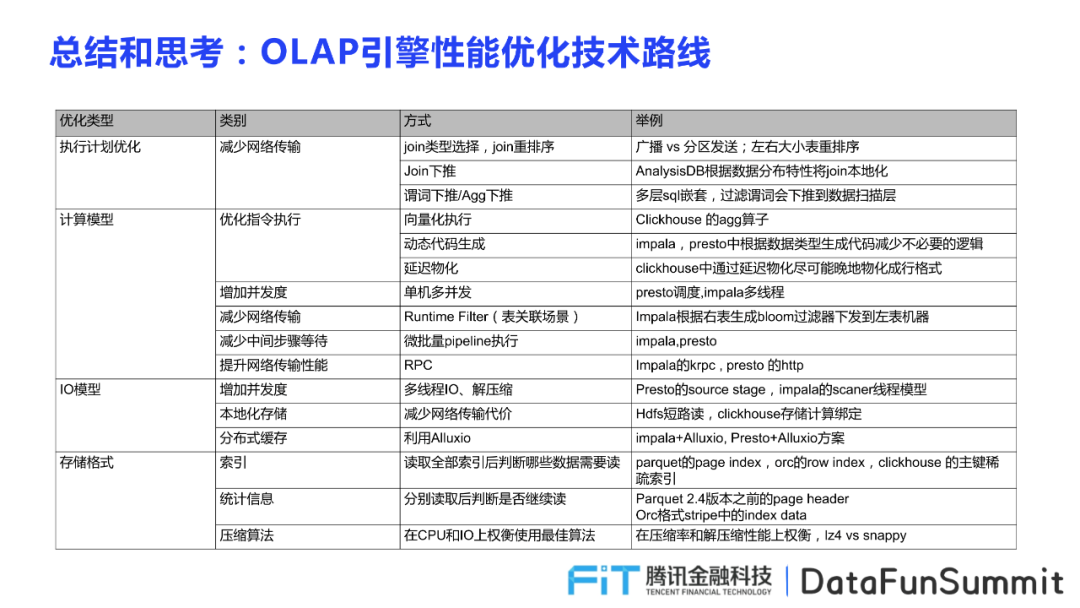
OLAP引擎性能优化技术路线
下面是对OLAP引擎性能优化技术路线的一个总结,这对于深入到某个具体的引擎做深度优化,提升性能是很好的参考思路。向量化、动态代码生成这两种方式是比较传统的思路,其中动态代码生成最大化减少对类型的分支判断,减少指令,提升计算性能。
Impala性能相关优化思路总结
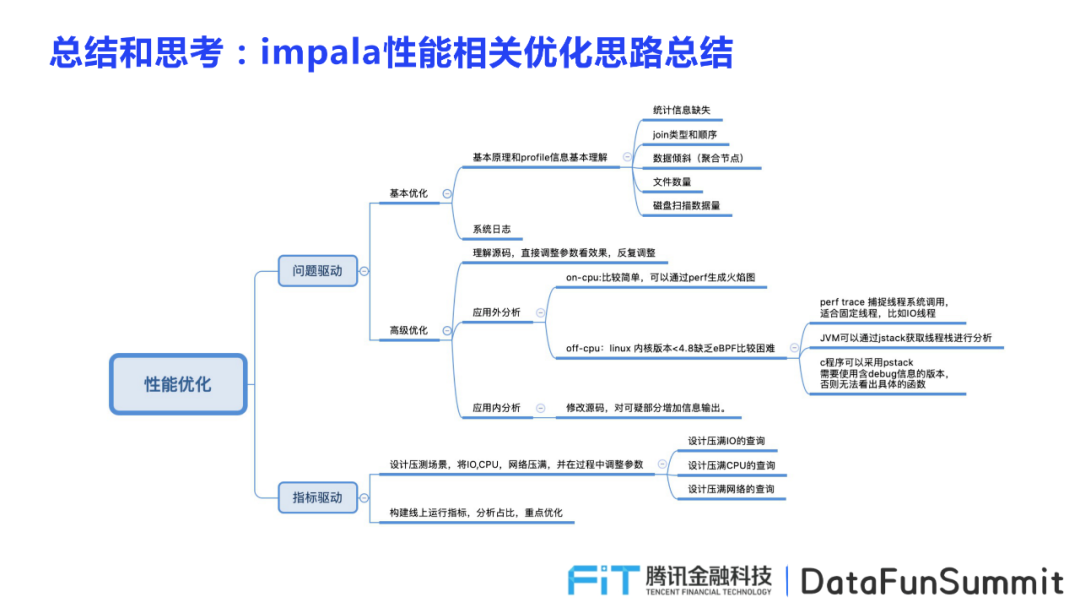
性能优化思路分为问题驱动和指标驱动。其中问题驱动包括基本优化和高级优化两类,基本优化需要从基本原理和profile信息进行基本理解,并优化系统日志两部分;高级优化首先需要理解源码,反复直接调整参数看优化效果,同时考虑从应用外分析和应用内分析。
指标驱动则通过设计压力测试场景进行优化,将IO,CPU,网络压满,并看在这些状况下,系统查询行为表现如何,在不断实践过程中调整参数,并构建线上运行指标,分析占比,重点优化各项重要指标,从而对impala性能进行一个好的优化。
分享嘉宾:

原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Impala在腾讯金融大数据场景中的应用】(https://www.iteblog.com/archives/10068.html)