

本文来自 Data + AI Summit 2021 会议中 Facebook 的Rongrong Zhong(Facebook Presto 团队的 TL) 和 Tejas Patil(Facebook Spark 团队的 TL) 工程师带来的名为 《Portable UDFs : Write Once, Run Anywhere》的分享。
虽然大多数查询引擎都提供了丰富的内置函数,但它并不能满足用户的所有需求。在这种情况下,用户定义函数(UDF)允许用户表达他们的业务逻辑并在查询中使用它。不过用户通常使用多个计算引擎来解决他们的数据问题。Facebook 为工程师提供多种系统来解决他们的数据问题:adhoc、批处理、实时处理。用户最终会根据他们的需求和手头的问题来选择一个系统。每个系统通常都有自己的方式来允许用户创建 UDF。如果在一个系统中定义了 UDF,那么很可能也需要在其他系统中有类似的 UDF。这导致用户不得不针对不同的计算引擎多次重写相同的 UDF。在这次演讲中,Rongrong Zhong 和 Tejas Patil 将深入探讨一种称为可移植 UDF(Portable UDF)。可移植 UDF 允许用户以一种与引擎无关的方式编写自定义函数,并在多个计算引擎中使用它。我们将介绍可移植 UDF 项目的动机、设计和当前状态。
下面是本次分享对应的视频,感兴趣可以看下:
为什么需要设计 Portable UDFs

比如用户在 Presto 中需要实现一个自定义函数用于解析特定业务,那么用户需要按照 Presto 的相关规范去实现 UDF,比如下面是 Presto 中的 array_contains 函数的实现逻辑:

遗憾的是,在 Presto 中实现的用户自定义函数不能在 Spark 中运行:
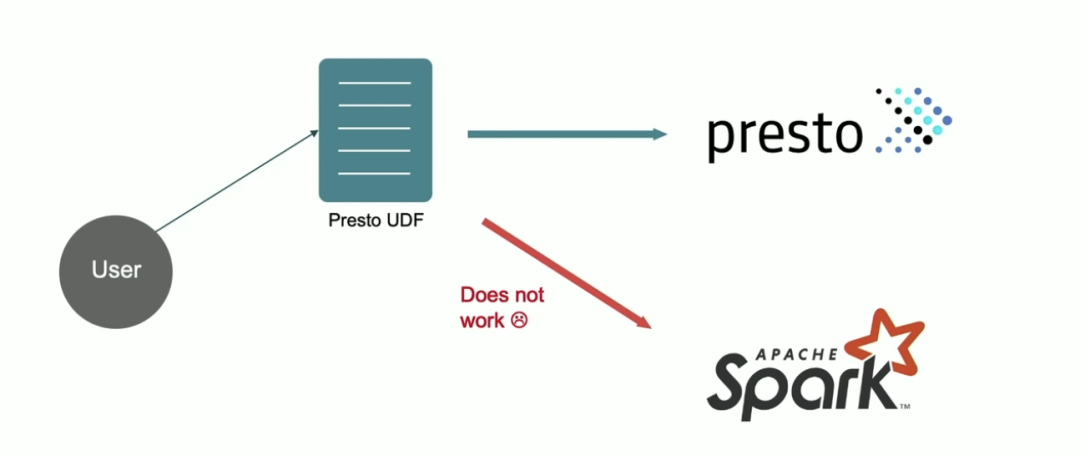
为了解决这个问题,我们通常需要在不同计算引擎中分别实现相同的业务逻辑,如下是 Presto 和 Spark 中实现 array_contains 函数的对比:

这种方式有以下五个问题:
•需要学习不同计算引擎实现 UDF 的规范;•不同计算引擎需要重复编写相同的业务逻辑;•不同计算引擎的相同 UDF 的可能版本不一样而导致逻辑不一致,如下 Presto 计算引擎中对应的 UDF 版本为 V2,而 Spark 中对应的 UDF 版本为 V1;
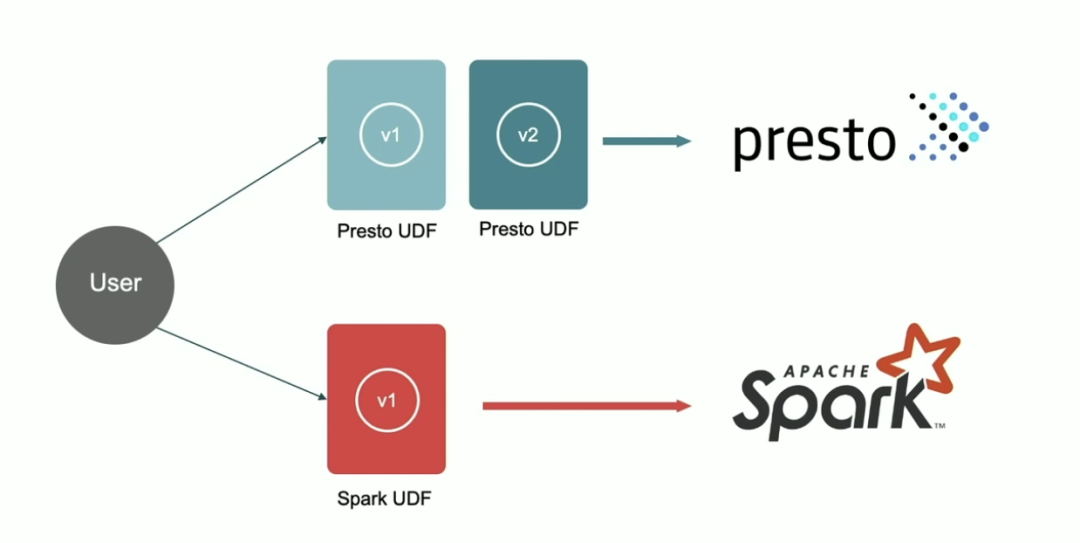
•需要维护多个版本;•线上发布时间可能不会一致。

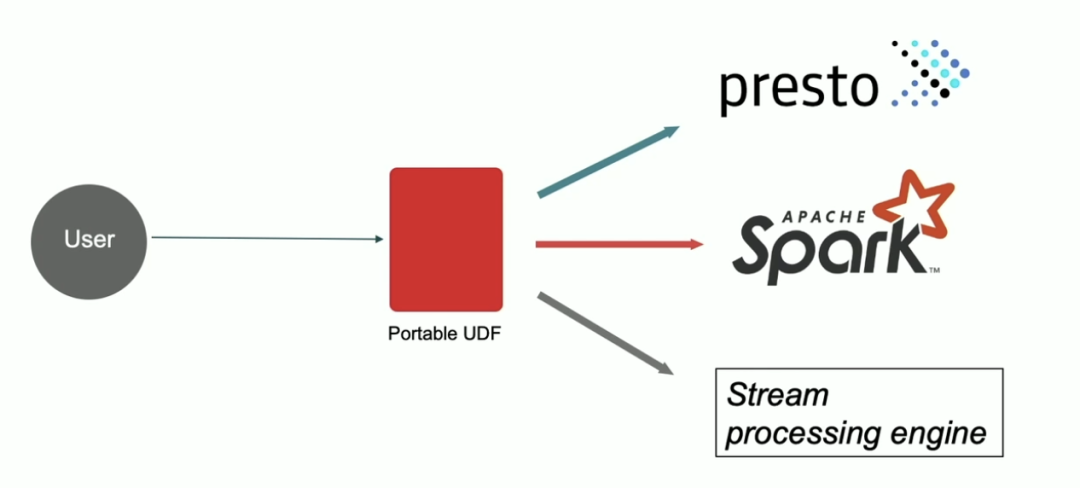
什么是 Portable UDF
Portable UDF 就是一种与特定计算引擎无关的一种服务,用户编写 UDF 的时候只需要按照 Portable UDF 的规范去编写即可,之后可以在 Presto、Spark 以及流处理引擎中使用,维护起来也很方便。
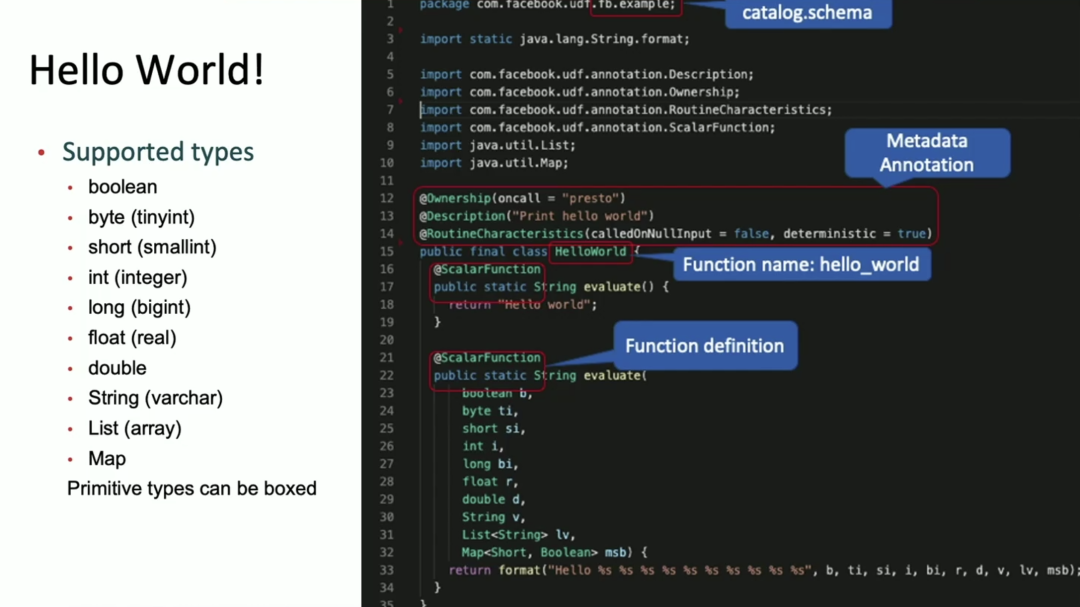
下面就是 Portable UDF 的一个例子。Portable UDF 是由 Java 编写的,并提供了多个 Annotation。比如 Ownership 用于标识这个 UDF 是由谁维护的;Description 用于标识这个 UDF 的功能描述;ScalarFunction 用于标识函数的定义,比如下面的第16行和第22行就是 HelloWord 类中的两个自定义函数实现。
当前,Facebook 的 Portable UDF 支持很多种数据类型,比如 boolean、byte、short 等等。
总体而言,Portable UDF 主要有三种函数元数据
•函数管理元数据,比如 Ownership、Description 等;•函数解析元数据,比如函数签名、调用惯例(注:函数的调用方和被调用方对于函数如何调用需要有一个明确的约定,只有双方都遵守同样的约定,函数才能被正确的调用。)、函数调用结果是否确定等•函数运行元数据,比如包地址、版本等

比如下面就是上面 HelloWord 自定义函数的函数元数据信息,这些函数元数据是存放在 Metastore 里面的。
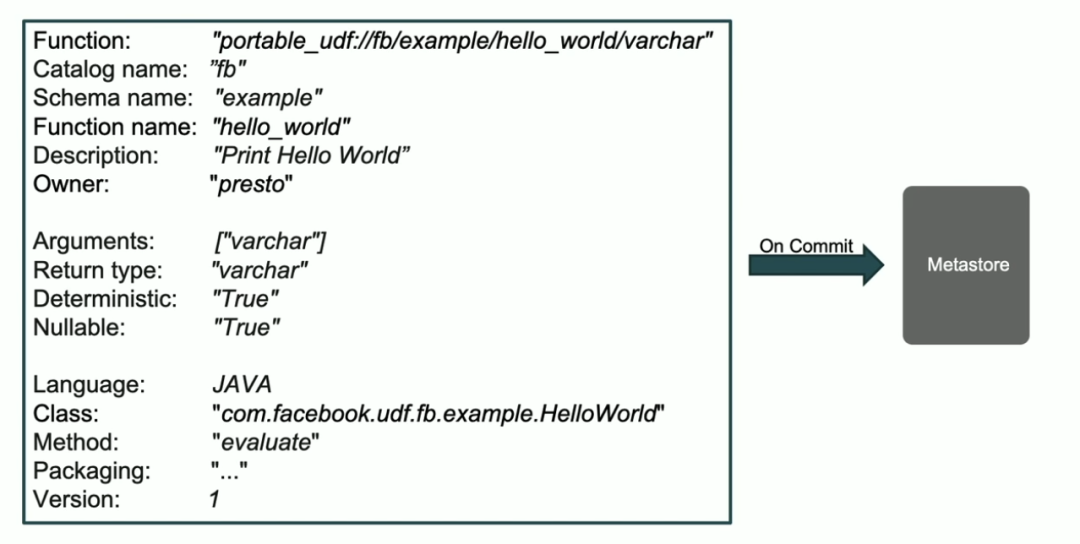
有了 Portable UDF 之后,编写 UDF 的 API 就和计算引擎独立;而且版本可以统一管理,发布生命周期也很好控制。

Portable UDF 是如何运行的
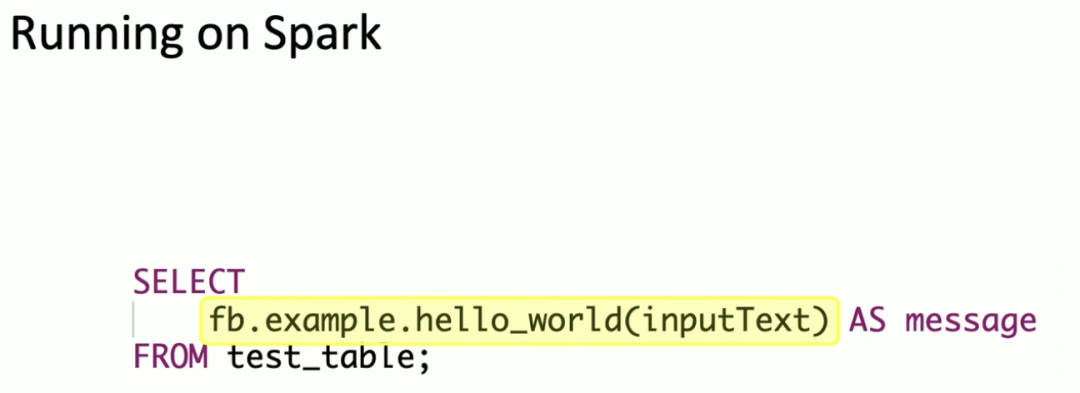
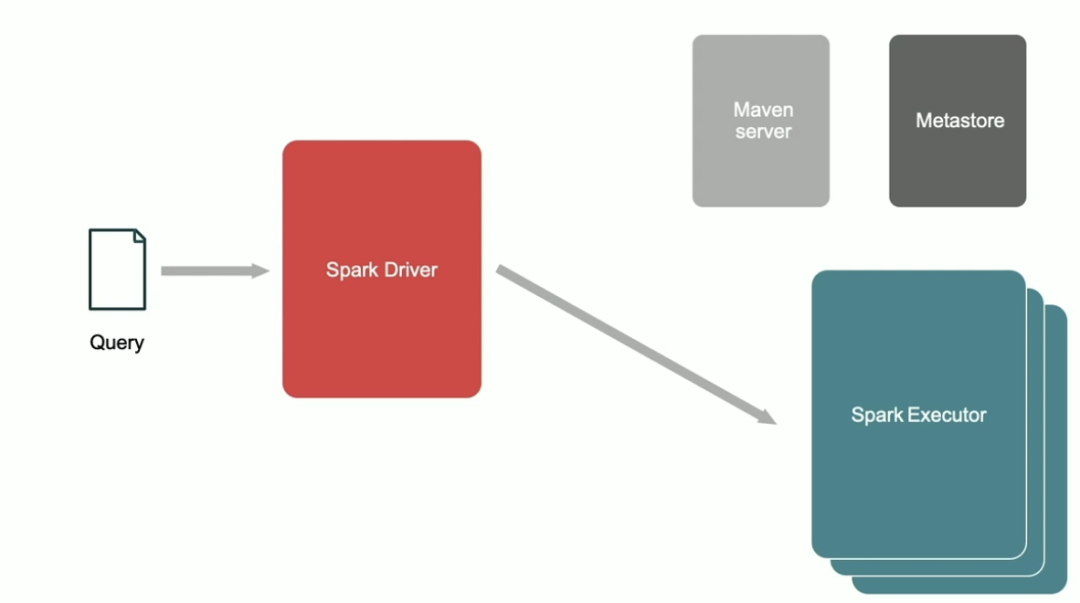
下面我们来看看 Portable UDF 是如何运行的。首先我们来看看在 Spark 他是如何使用的。在 Spark 中,只需要使用如下方式就可以调用 Portable UDF,其中黄色背景的就是 Portable UDF。
运行上面的 SQL 时,这个 SQL 被发送到 Spark Driver,这时候 Spark 识别出 Portable UDF,它会从 MetaStore 中获取这个 Portable UDF 的相关信息。
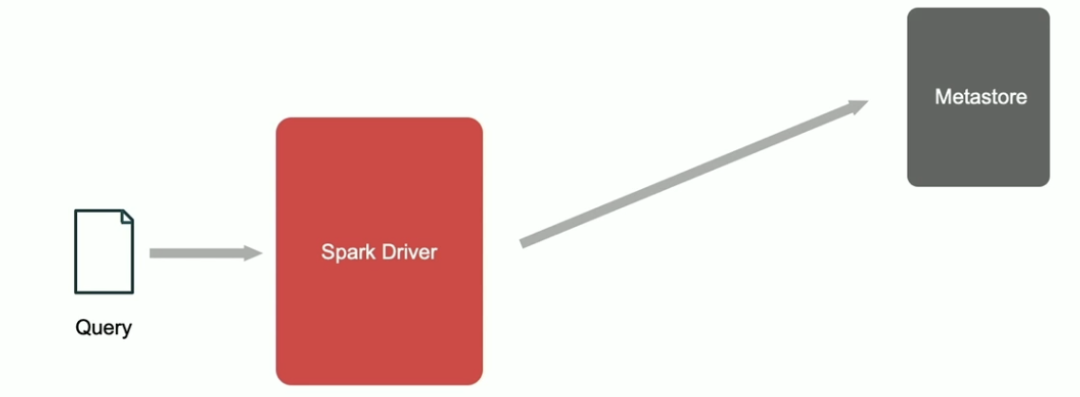
Spark 首先会从 MetaStore 中获取这个 Portable UDF 的函数基本信息,比如函数的 catalog name、函数的名称、函数的描述以及 Owner 等信息。

紧接着,Spark 会获取这个 Portable UDF 的函数类型、函数返回值的类型等信息。

最后,Spark 会获取这个 Portable UDF 的对应实现类、需要调用的方法、包名以及版本等信息。

拿到这些信息之后,Spark Driver 会从 Maven server 下载对应的 Jar 文件 。
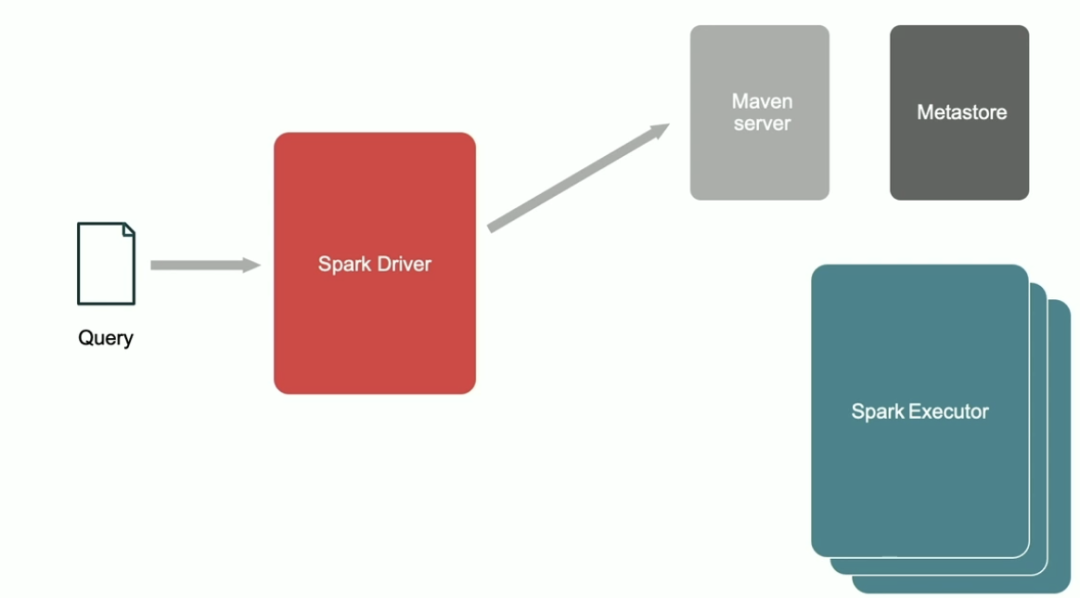
之后,Spark Driver 会做一些校验,最后发送到 Spark Executor 上执行对应的 Portable UDF。
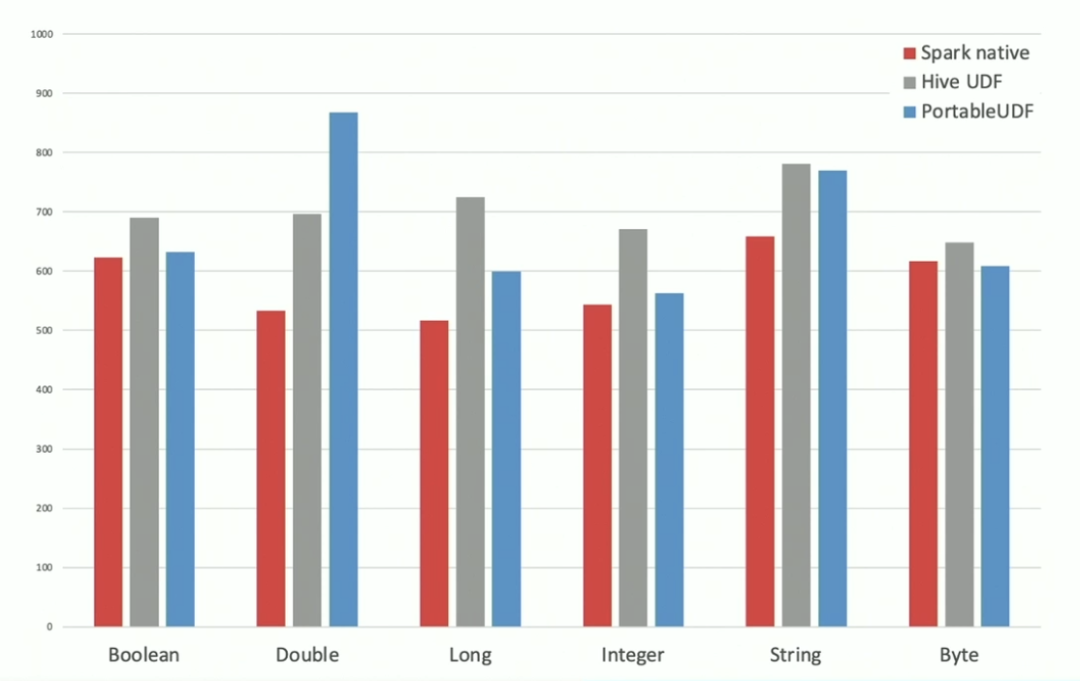
下面是 Spark 原生的 UDF、Hive UDF 以及 Portable UDF 的相关性能对比。可以看出,Portable UDF 除了 Double 的数据类型比较差,其他都比 Hive UDF 要好。
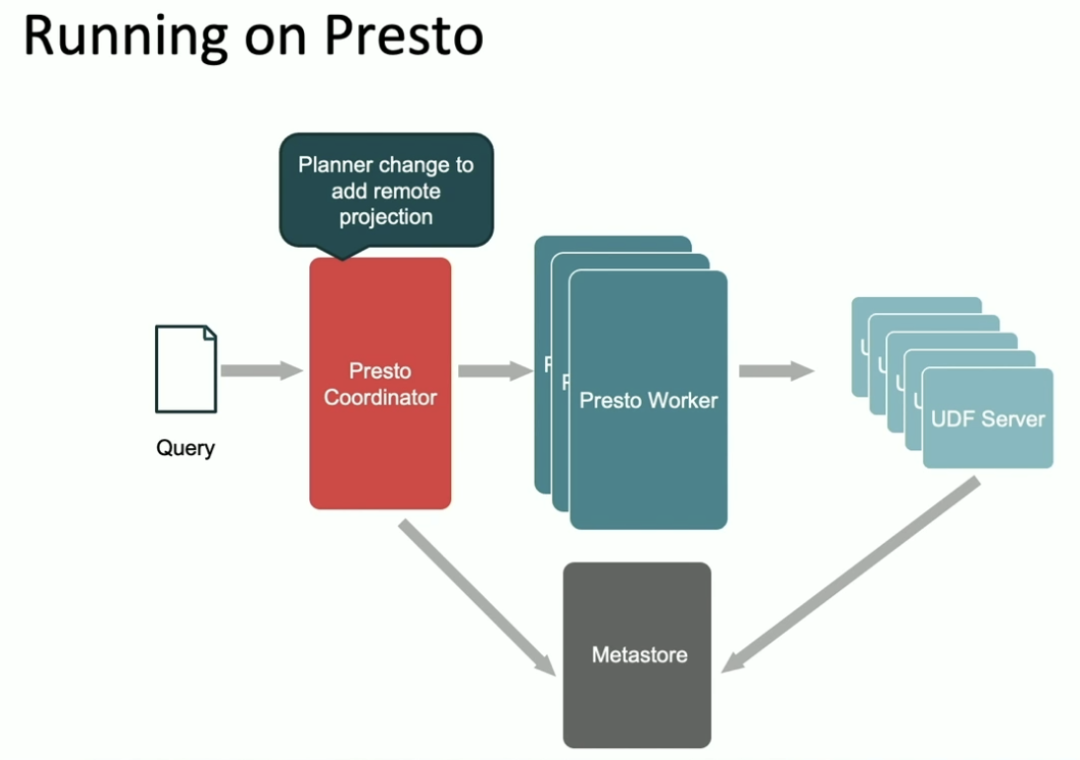
下面我们来介绍一下 Portable UDF 如何在 Presto 上运行的。Presto 从0.238 版本开始支持创建外部函数(external function、作者正好就是 rongrong。参见:https://prestodb.io/docs/current/sql/create-function.html、https://github.com/prestodb/presto/commit/f209297a6cb02a0a02415c48db15724547e3e0de)。所以在 Presto 中通过定义外部函数来创建一个 Portable UDF。
另外,和 Spark 不一样的是,由于 Presto 集群是共享的,做不到作业之间的隔离,而且我们无法完全信任 Portable UDF 是安全的。所以在 Presto 中,Portable UDF 是在单独的远程集群中运行的。

下面是 Portable UDF 在 Presto 中的运行。首先,查询被发送到 Coordinator 中,这时候 Presto 的 Planner 会通过查询 MetaStore 把带有 Portable UDF 的列修改成 remote projection,然后发送到 Worker 端;Worker 在运行的时候遇到 Portable UDF 时会把相应的计算发送到 UDF Server 中单独计算。
下面是带有 Portable UDF 的查询计划。可以看出,查询中有三个带有 Portable UDF 的列,而输出的执行计划也可以看出有三个带有 REMOTE 的 project。

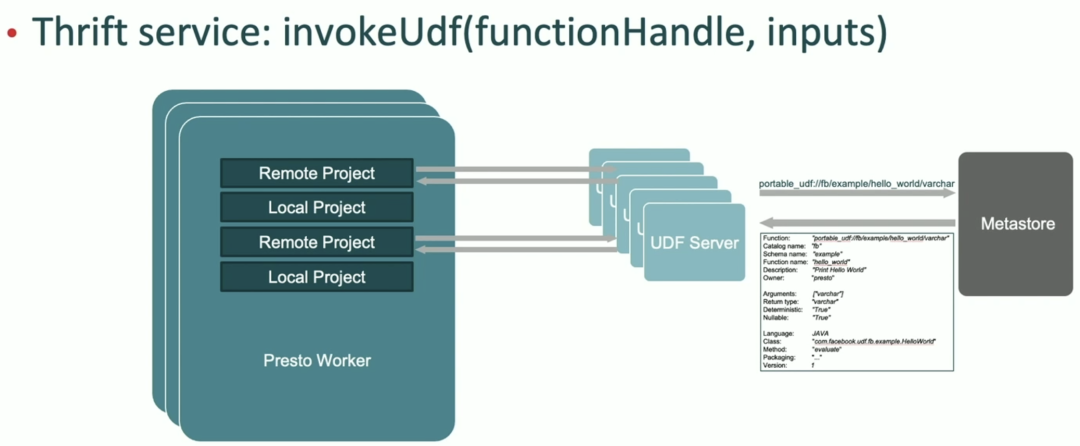
下面是 Presto Worker 处理 Portable UDF 的流程:
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Portable UDF:Facebook 工程师为了解决不同计算引擎 UDF 统一的项目】(https://www.iteblog.com/archives/10107.html)






