

文章目录
引言

在字节跳动内部,Presto 主要支撑了 Ad-hoc 查询、BI 可视化分析、近实时查询分析等场景,日查询量接近 100 万条。
功能性方面
完全兼容 SparkSQL 语法,可以实现用户从 SparkSQL 到 Presto 的无感迁移;
性能方面
实现 Join Reorder,Runtime Filter 等优化,在 TPCDS1T 数据集上性能相对社区版本提升 80.5%;
稳定性方面
首先,实现了多 Coordinator 架构,解决了 Presto 集群单 Coordinator 没有容灾能力的问题,将容灾恢复时间控制在 3s 以内。其次实现了基于 histogram 的静态规则和基于运行时状态的动态规则,可以有效进行集群的路由和限流;
可运维性方面
实现了 History Server 功能,可以支持实时追踪单个 Query 的执行情况,总体观察集群的运行状况。
字节跳动 OLAP 数据引擎平台 Presto 部署使用情况
过去几年,字节跳动的 OLAP 数据引擎经历了百花齐放到逐渐收敛,再到领域细分精细化运营优化的过程。存储方面离线数据主要存储在 HDFS,业务数据以及线上日志类数据存储在 MQ 和 Kafka。计算引擎根据业务类型不同,Presto 支撑了 Ad-hoc 查询、部分 BI 报表类查询,SparkSQL 负责超大体量复杂分析及离线 ETL、Flink 负责流式数据清洗与导入。
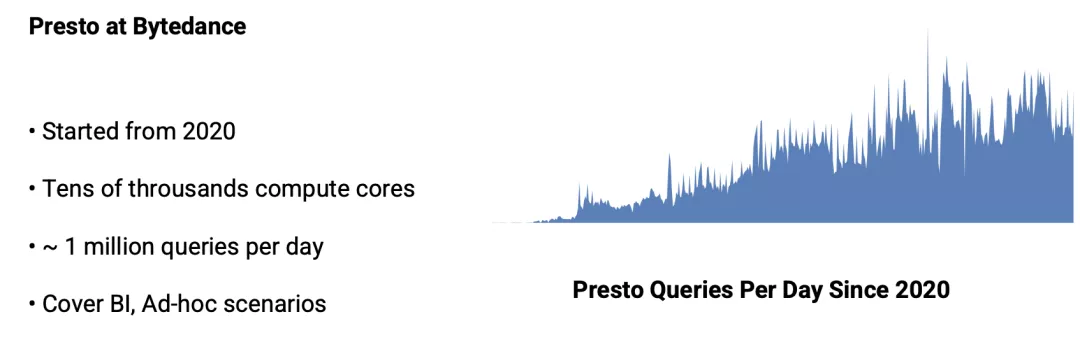
为了处理日益增长的 Ad-hoc 查询需求,在 2020 年,字节跳动数据平台引入 Presto 来支持该类场景。目前,整个 Presto 集群规模在几万 core,支撑了每天约 100 万次的查询请求,覆盖了绝大部分的 Ad-hoc 查询场景以及部分 BI 查询分析场景。
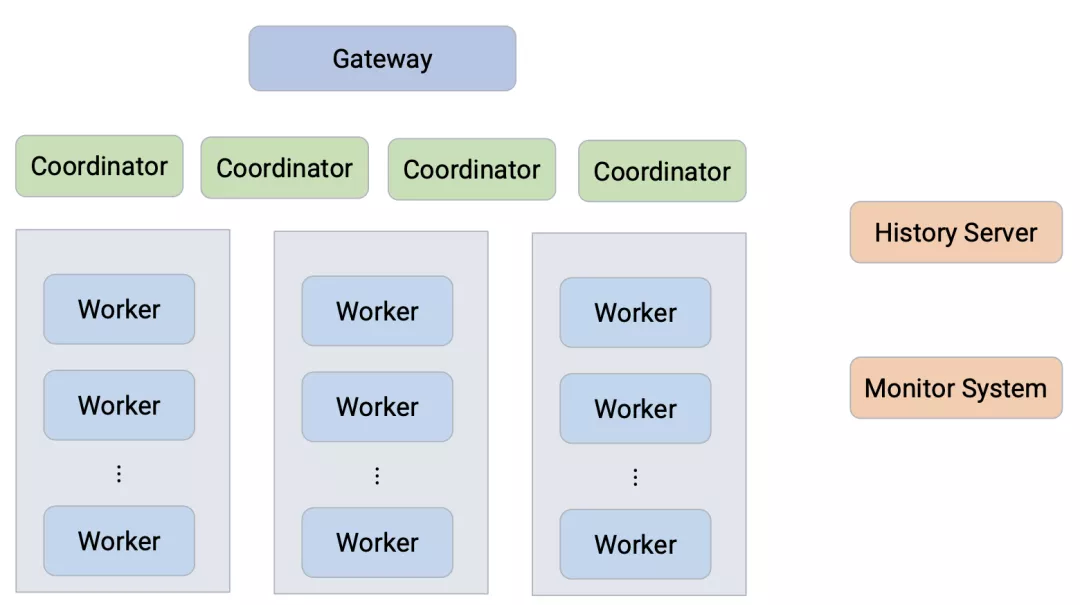
图注:字节跳动内部 Presto 集群部署架构图
上图是字节跳动内部 Presto 集群部署的架构,针对不同的业务需求拆分为了多个相互隔离的集群,每个集群部署多个 Coordinator,负责调度对应集群的 Worker。
接入层提供了统一的 Gateway,用以负责用户请求的路由与限流。同时还提供了 History Server,Monitor System 等附属组件来增加集群的可运维性与稳定性。
Presto 集群稳定性和性能提升
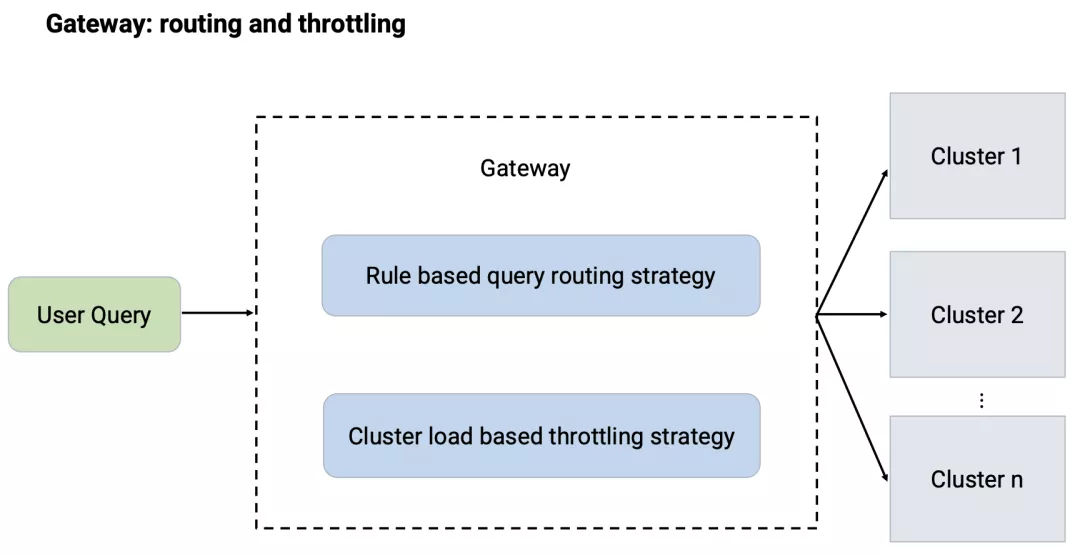
针对不同的业务场景以及查询性能要求,我们将计算资源拆分为了相互独立的 Presto 集群。
Gateway 负责处理用户请求的路由,这部分功能主要通过静态的路由规则来实现,路由规则主要包括允许用户提交的集群以及降级容灾的集群等。
为了更好的平衡不同集群之间的负载情况,充分有效的利用计算资源,后期又引入了动态的路由分流策略。该策略在做路由选择的过程中会调用各个集群 Coordinator 的 Restful API 获取各个集群的负载情况,选择最优的集群进行路由调度。
通过静态规则与动态策略相结合的方式,Gateway 在为用户提供统一接入接口的情况下,也保证了集群之间工作负载的平衡。
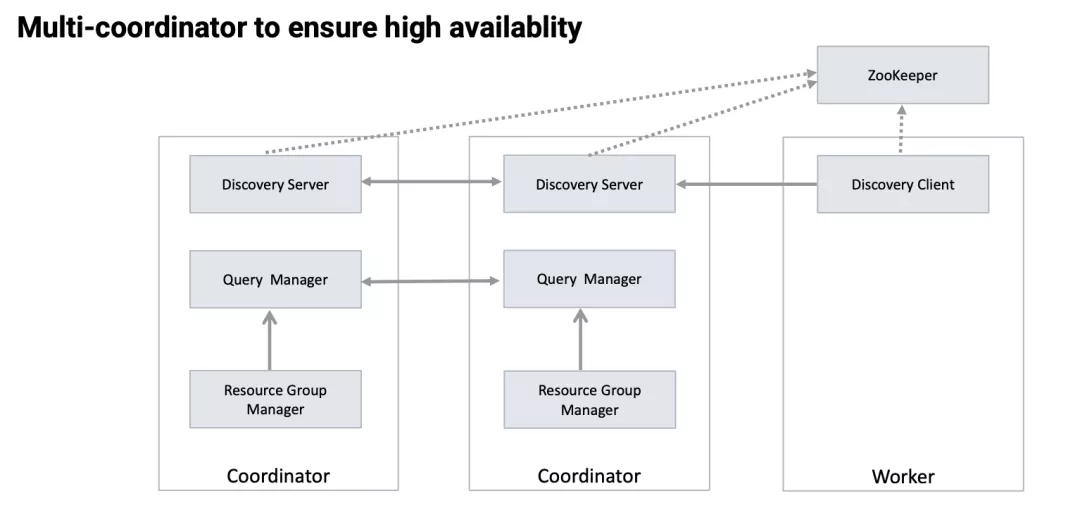
Coordinator 节点是单个 Presto 集群的核心节点,负责整个集群查询的接入与分发,因此它的稳定性直接影响到整个集群的稳定性。
在最初的部署中,每个 Presto 集群只能部署一个 Coordinator,当该节点崩溃的时候,整个集群大概会消耗几分钟的不可用时间来等待该节点的自动拉起。
为了解决这个问题,我们开发了多 Coordinator 的功能。该功能支持在同一个 Presto 集群中部署多个 Coordinator 节点,这些节点相互之间处于 active-active 备份的状态。
主要实现思路是将 Coordinator 和 Worker 的服务发现使用 Zookeeper 来进行改造。
Worker 会从 Zookeeper 获取到现存的 Coordinator 并随机选取一个进行心跳上报,同时每个 Coordinator 也可以从 Zookeeper 感知到其他 Coordinator 的存在。
每个 Coordinator 负责存储当前连接到的 Worker 的任务负载情况以及由它调度的查询执行情况,同时以 Restful API 的形式将这些信息暴露出去;其他 Coordinator 在做任务调度的时候会通过这些 Restful API 获取到整个集群的资源使用情况进行相应的任务调度。
目前多 Coordinator 机制已经在集群中上线使用了半年,将集群的不可用时间从几分钟降低到 3s 以内。
另一个影响 Presto 集群稳定性的重要因素是超大规模的查询。
在 Ad-hoc 场景下,这种查询是无法避免的,并且由于这种查询会扫描非常多的数据或者生成巨大的中间状态,从而长期占用集群的计算资源,导致整个集群性能下降。
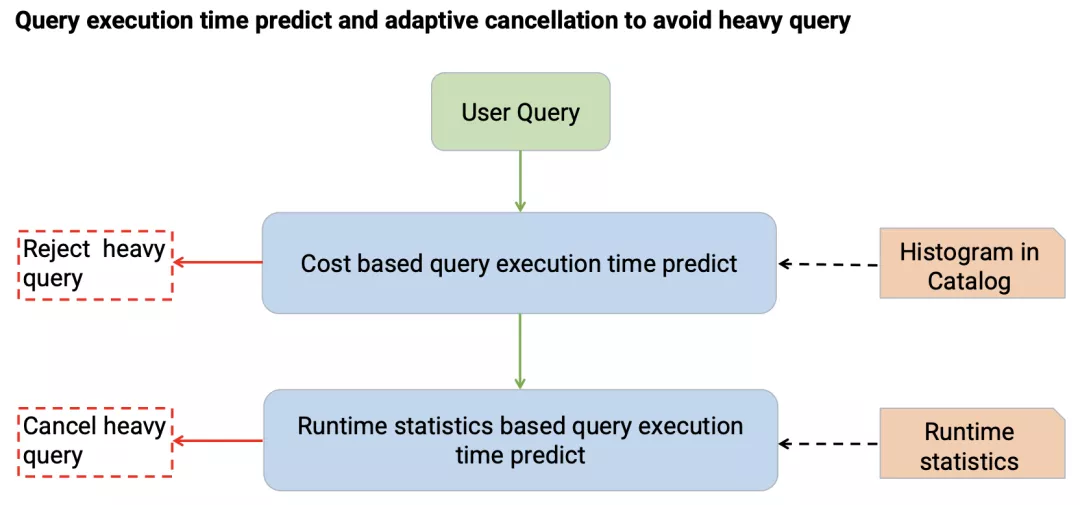
为了解决这个问题,我们首先引入了基于规则以及代价的查询时间预测。
基于规则的查询时间预测主要会统计查询涉及到的输入数据量以及查询的复杂程度来进行预测。
基于代价的查询时间预测主要是通过收集在 Catalog 中的 Histogram 数据来对查询的代价进行预测。
上述预测能够解决部分问题,但是还是会存在一些预估不准的情况,为了进一步处理这些情况,我们引入了 Adaptive Cancel功能。
该功能主要是在查询开始执行后,周期性的统计查询预计读取的数据量以及已完成的任务执行时间来预测查询整体的执行时间,对于预测超过阈值的查询提前进行取消,从而避免计算资源浪费,提升集群稳定性。
![]()
另外,Presto 本身提供的 UI 界面可以很好地对查询执行情况进行分析,但是由于这部分信息是存储在 Coordinator 内存当中,因此会随着查询数量的累积而逐步清除,从而导致历史查询情况无法获取。
为了解决这个问题,我们开发了 History Server 的功能。
Coordinator 在查询执行完成之后会将查询的执行情况存储到一个持久化存储当中,History Server 会从持久化存储当中加载历史的查询执行情况并提供与 Presto UI 完全相同的分析体验,同时基于这部分持久化的信息,也可以建立相应的监控看板来观测集群的服务情况。
在不同场景的优化与实践
1、Ad-hoc 查询分析场景
2020 年之前,大数据场景下的 ad-hoc 查询主要由 Hive/SparkSQL 来支撑。为了进一步优化查询性能,提高资源使用效率,从 2020 年开始,我们在生产环境大规模使用 Presto。
与 SparkSQL 相比,Presto 是一个常驻的 MPP 架构的 SQL 查询引擎,避免了 Spark Context 启动以及资源申请的开销,端到端延迟较低。
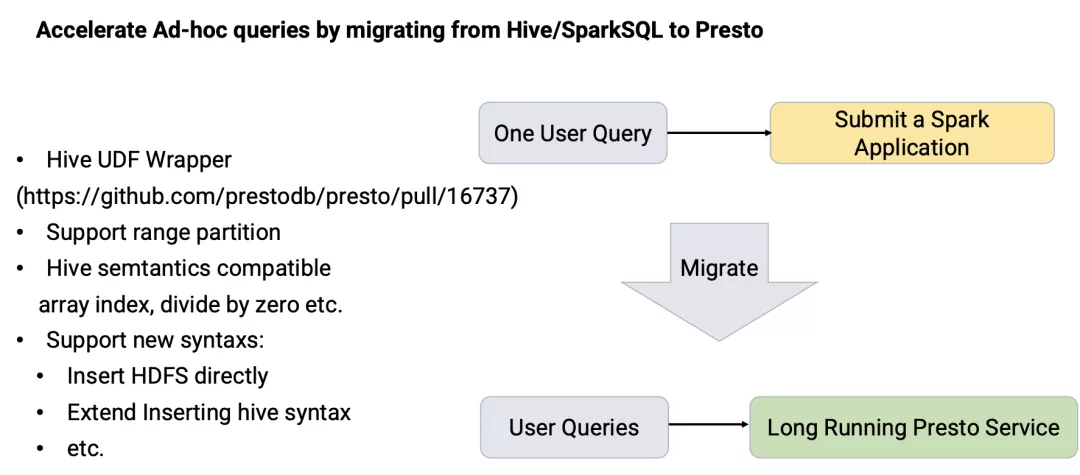
与 Hive/Spark Thrift Server 相比,Presto Coordinator 更加成熟,轻量,稳定,同时 Presto 基于全内存的 Shuffle 模型可以有效的降低查询延迟。为了做到用户查询无感迁移到 Presto,我们做了大量的工作使得 Presto 在语法和语义层面兼容 SparkSQL。
在接入层方面:提供了 SQL 标准化改写功能。该功能可以将用户的 SQL 改写成 Presto 可以支持的 SQL 语法进行执行,做到了底层引擎对用户透明。
在函数支持方面:在 Presto 中支持了 Hive UDF 的执行,使得之前数据分析师积累下来的大量 UDF 可以在 Presto 中执行。该功能主要支持了在解析阶段可以加载 Hive UDF 和 UDAF,并进行类型转换使其适配 Presto 类型体系,最终封装成 Presto 内置函数的形式进行执行。该功能部分已经贡献回了 Presto 社区:
https://github.com/prestodb/presto/pull/16737
2、BI 可视化分析场景
Presto 在字节跳动应用的另一个比较重要的场景是 BI 可视化分析。
BI 可视化分析提供了可视化交互的功能来进行数据分析,数据分析可以直观快速的进行数据分析并生成相应的分析图表,这给查询引擎提出了更高的要求。在这一场景下,不仅,QPS 大幅提高,同时还要求查询引擎能给出比较低的查询延迟。
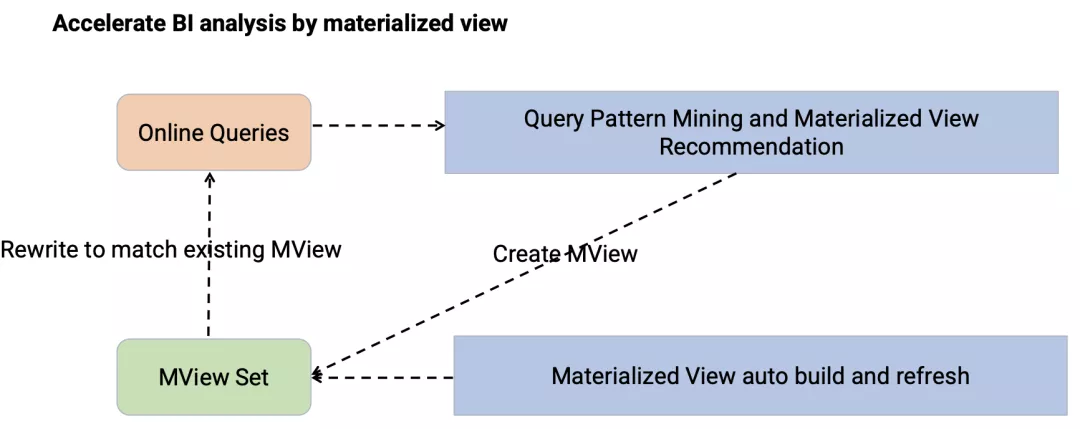
为了应对这些挑战,我们做了一个比较重要的工作——在 Presto 中引入了物化视图。
这种场景下,查询 SQL 往往都是由 BI 可视化平台根据固定的模版自动生成的,用户的可视化操作往往限于对查询过滤条件,聚合维度以及聚合指标的改变,适合物化视图的应用。
![]()
在物化视图功能中,我们借鉴了很多传统数据库的经验,工作主要涉及三方面的工作:
物化视图的自动挖掘——主要根据用户查询的历史记录进行分析,统计不同数据的查询频率进行物化视图的自动推荐与创建。
物化视图的生命周期管理——主要维护分区级别物化视图的自动更新、删除。
物化视图的重写功能——基于已有的物化视图,对用户的 query 进行重写以减少查询执行的复杂度。
3、近实时场景的查询分析
这是今年开始探索的一个场景,主要是为了降低数据链路的延迟,提升查询分析的时效性。
传统的基于 ETL 的数据链路中,业务数据和日志数据经由 Kafka 定期 dump 到 HDFS,然后会有多个 ETL 任务对数据进行加工清理形成不同层级的 Hive 表用来进行查询分析。
这个链路中往往需要进行表数据的全量更新,任务比较重,与线上数据存在 1 天以上的数据延迟。
为了降低数据延迟,我们引入了 Hudi 来进行数据的增量更新。
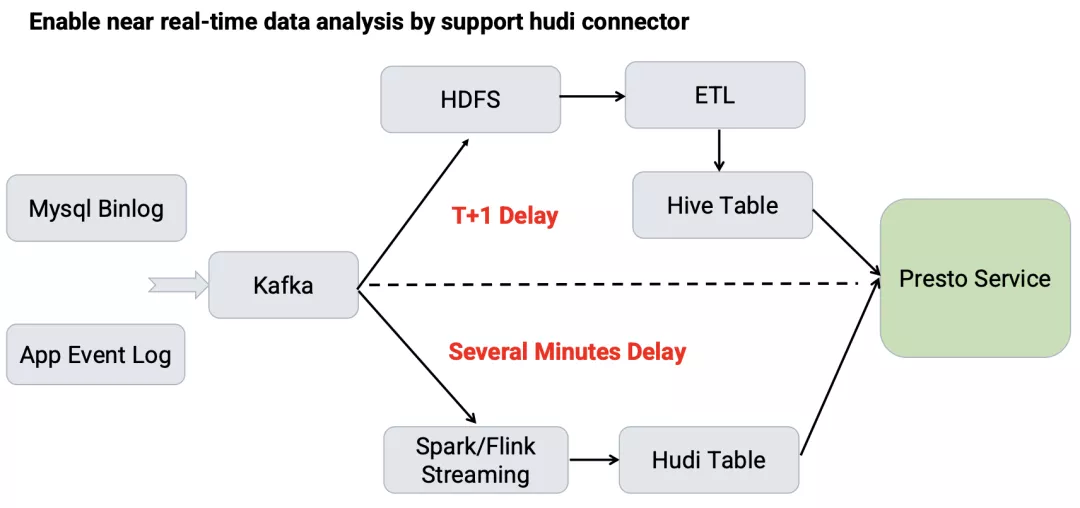
在这个链路中,业务数据和日志数据经由 Spark/Flink Streaming 任务增量写入到 Hudi 表中,数据分析师可以直接查询这部分数据。目前,该链路可以做到分钟级别的数据延迟。
我们在 Presto 的优化工作主要是将 Hudi 表读取的功能从 Hive Connector 中提取出来成为了一个单独的 Hudi Connector。
首先,Hudi Connector 针对 Hudi 表的结构特点更好地支持了基于不同策略的分片调度算法,保证任务分配的合理性。
同时,Hudi Connector 优化了 Hudi MOR 表读取过程中的内存管理,避免了 Worker 节点 OOM,提升了集群稳定性。
最后,Hudi Connector 的引入降低了 Hudi 版本升级带来的工作量,可以更好的集成 Hudi 社区最新的功能。这部分功能我们将会逐步贡献回社区:
https://github.com/prestodb/presto/issues/17006
本文转载自:Presto 在字节跳动的实践与优化
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Presto在字节跳动的内部实践与优化】(https://www.iteblog.com/archives/10124.html)







