

文章目录
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。
测试目的
- 验证影响Alluxio加速收益的各种因素
- 记录Alluxio在适宜条件下的加速表现
- 总结Alluxio的使用建议
测试环境
集群部署架构图
计算引擎使用Presto,数据源为Hive,Alluxio作为缓存。共搭建2个集群:Presto+Alluxio集群,Hadoop集群。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Presto+Alluxio集群配置
- 机器:4台 linux虚拟机
- cpu/内存:32核 64G
- 磁盘:60GB SSD + 200GB SSD
- 网络:万兆带宽
- 关键配置:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Hadoop集群配置
- 机器:5台 linux虚拟机
- cpu/内存:16核 32G
- 磁盘:60GB HDD + 1200GB HDD
- 网络:万兆带宽
- 关键配置:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
测试用数据集列表
测试使用的数据是tpc-ds标准数据集。因测试需要,我们导入了多份不同大小的数据集。每份数据集里的表结构是完全相同的,区别是表中的数据量不同,部分表之间的分区也不相同。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Alluxio强悍的加速表现
首先我们来看看,当提供了相对适宜的条件,Alluxio的具体加速表现。
- 以下查询的数据集是tpc-ds数据集tpcds_bin_partitioned_orc_100,整个数据集的大小为23.4G。
- 以下执行的SQL是在tpc-ds提供的sql中选取7条满足条件的,实验中对7条SQL各反复查询10次,记录每次查询的耗时。
- 每次查询之间间隔8~10秒,给Alluxio的异步缓存一定时间,尽量提高下一次查询的命中率。
实验结果展示
重点说明
- 耗时的单位为ms。
- “avg”列的值是第2次查询至第10次查询耗时的平均数。
- “first”列的值就是第1次查询的耗时。“加速收益”列的计算方式是:(first - avg) / first。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
实验结果分析
- 第一次查询时,由于数据还没有被缓存,耗时是最高的,往后数据逐渐被异步缓存入Alluxio,查询耗时逐渐递减,等全量数据进入Alluxio缓存,此时加速收益达到最高,查询耗时最低且停止递减。
- 我们可以看到相较于耗时最大的first,avg的值有大幅度的降低,耗时仅有原来的20%~30%。从“加速收益”列来看可以更量化的评估加速收益。
- 下面我们验证一下关于影响Alluxio加速收益的具体因素。在下面的实验中,可以看到Alluxio在更适宜的环境下,甚至可以把查询耗时减少到原来的5%。
影响加速收益的重要因素
根据测试的结果,结合官方文档描述,总结出几点因素会对Alluxio加速收益产生影响。下面我们就来看看这些因素
重点说明:这里说的Alluxio加速收益,指的是查询的耗时在加速后比加速前快了多少,并不单单是指IO那部分的耗时快了多少。更具象化的描述,它指的是单个查询在加速后的耗时比加速前降低了百分之多少。
因素一:查询的Hive表的底层数据文件的大小和加速收益正相关
1. 结论:查询的数据文件在小于约2MB时,文件越小,Alluxio加速收益越低。
因文件过小,所以每个文件是一个split。Presto解析每个split创建driver,调度driver执行,这段耗时是不能被加速的,而operator扫描的数据太小,那么磁盘IO的耗时在整个耗时中占比就会较低,Alluxio对查询的加速收益就会降低。
在本次测试所使用的环境中,每个数据文件小于约50KB时,在查询的整体耗时上,加速收益会比较低。
数据文件大于约2MB时,文件大小对加速收益的影响相对不那么明显。
这个2MB和50KB只是在本环境中观察到的一个大概阈值,在不同环境中可能会有不同的表现。
验证:用一条简单的SQL进行测试
【a. 实验用例说明】
测试方法采用相同的SQL去查询5个tpcds数据集中的同名表,保证SQL复杂度相同、表结构相同,分区表的分区数相同,仅仅是数据文件大小不同。
这里用一条简单的SQL语句反复多次查询,记录每次查询的耗时。
select * from web_sales where ws_wholesale_cost=1。
where条件字段ws_wholesale_cost并不是分区字段,所以会触发全表扫描。
在presto看到仅被划分出2个stage

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
本次实验查询的web_sales表在5个数据集中的相关元数据
○ 对于分区表,由于数据文件较小,每个文件就是一个split。
○ 为了有更清晰的对比,也引入了非分区表的查询,非分区表的数据文件数较少,每个数据文件大小均在100MB以上,Presto会按照HDFS文件块大小来划分split,每个split中的数据大概是28~38MB左右。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【b. 实验结果展示】

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【c. 实验结果分析】
○ 当每个split的数据小于2MB时,加速收益会明显低一些。数据越小,加速收益越低,split的数据达到几十KB时,加速就很微弱了。
○ 我们看到当每个split的数据达到2MB时,加速收益和30MB的区别不大,说明数据大于2MB后,数据大小对加速的影响就不大了。
○ 下面我们换一条SQL、换一张表再验证一次,可以看到结论是一样的。
3. 验证:用tpcds中的Query55进行测试
【a. 实验用例说明】
query55中包含聚合、排序、大小表join,复杂度一般,presto会为其划分7个stage
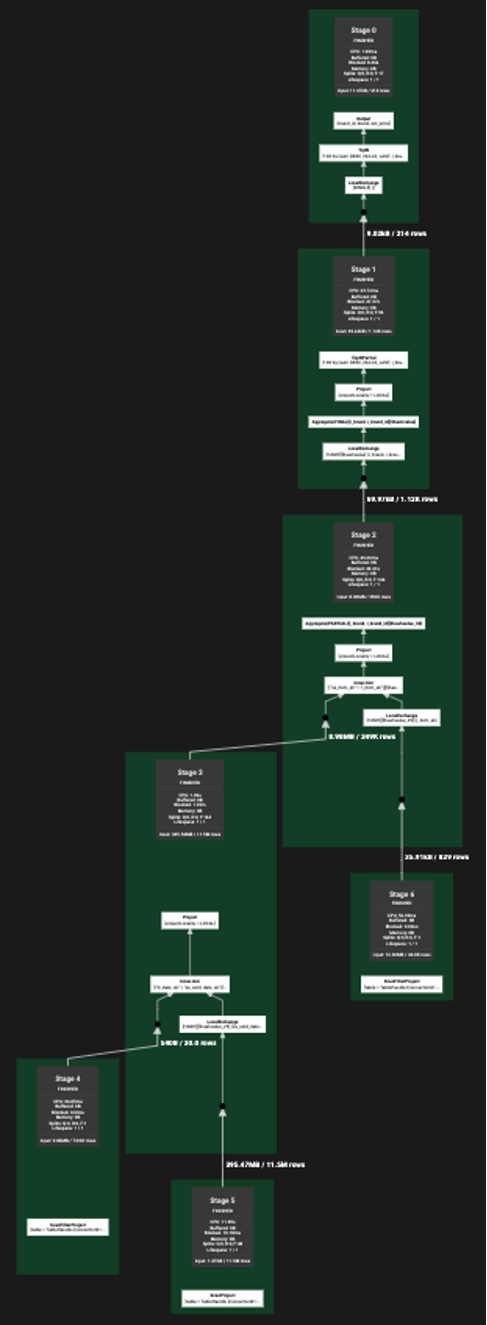
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
query55查询的事实表为store_sales。
store_sales表的相关元数据

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【b.实验结果展示】

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【c. 实验结果分析】
○ 结论跟上一次实验一致,当split的数据只有百来K的时候,加速收益比较微弱,仅20%。
○ split的数据大于2M以上,数据大小对加速收益的影响较小。
因素二:执行的SQL语句的复杂度和加速收益负相关
1. 结论:SQL语句越复杂,Alluxio的加速收益越低
SQL语句越复杂,计算的耗时就会越长,在整体耗时中,IO耗时的占比就会下降,而Alluxio只能加速IO的耗时,所以在整体耗时的加速上,收益会降低。
在评估SQL复杂度时,我们可以参考Presto在执行SQL时划分的Stage的数量,来量化SQL的复杂度,Stage越多则说明SQL相对复杂些。当然也可以肉眼大致判断下复杂度:
a. 简单:分组聚合、排序
b. 复杂:大小表join、select语句嵌套
c. 特别复杂:大表join大表、更多的表参与join、多个select语句嵌套
2. 验证:针对store_sales事实表进行测试
【a. 实验用例说明】
测试方法:采用选取tpc-ds中查询同一张事实表的不同query,去查询同一个数据集。保证表结构相同、文件数相同、文件大小相同、分区数相同,仅仅SQL不同。
query中除了事实表还会查询维度表,不同query涉及的维度表可能不同,但是维度表的数据量极小(比事实表小1000倍至1w倍),且都不是分区表,所以在这里我们可以忽略维度表不同所带来的影响。
测试时对同一条sql反复执行,记录每次执行的耗时。每次查询之间间隔8~10秒。
以下测试数据集选择tpcds_bin_partitioned_orc_100,事实表选择store_sales。
store_sales表的相关元数据:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
测试SQL采用如下6条

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【b. 实验结果展示】

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【c. 实验结果分析】
○ 我们看到最简单的SQL,加速收益非常高。
○ 面对一般复杂的SQL,Alluxio也依然很好的加速收益。
○ 整体来看,Stage数量小于15时,Alluxio都有不错的表现。
3. 验证:当查询的数据文件较小且SQL语句很复杂
【a. 实验用例说明】
我们这里再补充做一个实验,当查询的数据文件较小,而SQL语句又复杂的话,加速收益如何呢。
本实验SQL语句使用query88,分别查询2套数据集。
表的相关元数据

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【b. 实验结果展示】

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【c. 实验结果分析】
我们看到,在这种很不适宜Alluxio的条件下,加速收益会比较低。
因素三:查询SQL语句返回的数据量的大小和加速收益负相关
1. 结论:查询返回的数据量越大,Alluxio的加速收益越低
Presto最后会使用一个Driver来reduce所有Driver的计算结果,数据量越大,reduce的耗时越长,这里主要包括计算的耗时和网络IO耗时。如果是扫表时过滤的数据就很少,那么参与计算的数据量就会增加,增加了计算耗时,那么就降低了IO耗时在整个查询耗时中的占比
2. 验证:
【a. 实验用例说明】
我们使用2条简单的SQL查询同一张表,用where条件和limit控制一下返回的数据量
使用tpcds_bin_partitioned_orc_100中的web_sales表。
表的相关元数据

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
○ SQL1:select * from web_sales where ws_wholesale_cost=1
- 返回的数据条数为7.35K,数据大小为2.12MB。
○ SQL2:select * from web_sales limit 2000000
- 返回的数据条数为2M,数据大小为558.87MB。
【b. 实验结果展示】

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
【c. 实验结果分析】
○ 在返回少量数据时,查询的整体耗时很短,加速收益非常好
○ 返回大量数据时,查询的整体耗时大幅增加,加速收益不太好
因素四:影响加速收益的硬件环境因素
Alluxio的加速收益还受以下硬件因素影响:
• Alluxio缓存读写速度
• UFS磁盘读写速度
• 网络带宽
这部分结论就不做验证了。
声明:所有测试均在较为理想的环境下进行
上述所有测试,都没有考虑同时扫描的数据文件大小超过了Alluxio缓存的情况,在查询时,数据可以被全量缓存,达到全部本地命中的效果。所以我们看到每次查询耗时在经过2到4次查询的递减后,就会在一个很小的范围内波动,总的来说耗时比较稳定。
在生产环境可能会面临很多查询并行执行,需要扫描大量数据,数据文件的总大小会超过Alluxio缓存的大小。那么就会触发数据的淘汰,每个查询都不可能缓存所有需要的数据,所以查询的耗时永远不会稳定,而是在一个较大的区间范围去波动。
本次测试没有涵盖数据文件存储在对象存储的场景。如果使用对象存储S3,预计会有更显著的加速效果。
关于Alluxio应用于生产业务的使用、优化建议
Alluxio并不能在所有场景下都达到良好的加速收益,要发挥Alluxio更大的价值,我们总结了一些使用、优化建议。
建议一:使用Shadow Cache检测Alluxio与生产上业务的贴合性
生产上引入Alluxio是否能带来加速收益,应该设置多大的缓存容量能达到最大收益,需要有评估和检测。
Alluxio提供了一个Shadow Cache功能,可以使用布隆过滤器记录计算引擎访问过哪些数据以及总数据量的大小。每次计算引擎访问数据,都统计一次是否命中shadow cache中的数据。结合shadow cache和Alluxio的命中率可以检测业务是否适合使用缓存。
○ 业务场景不适合使用缓存
统计shadow cache的命中率,如果较低,则说明业务场景中极少会访问重复数据,那么是不适合使用缓存的。
○ Alluxio缓存需要加大空间
如果shadow cache的命中率高,但Alluxio缓存的命中率低,说明业务场景适合使用缓存,但是当前Alluxio缓存的空间过小了。因为在数据文件被重复访问时,之前存入Alluxio的缓存,已经因为缓存满了而被淘汰了,所以重复访问时将得不到任何加速。那么此时加大Alluxio缓存空间会取得更好的加速收益。
○ Alluxio缓存的收益已经达到较佳值
如果shadow cache命中率高,Alluxio缓存的命中率也高,则说明目前Alluxio缓存带给业务的加速收益已经达到良好水平,再加大Alluxio缓存空间意义不大。
使用Shadow Cache,对使用Alluxio在优化上有一个更直观的方向指导。
建议二:预先加载热数据
Alluxio的加速需要先把数据load到缓存中,这需要等待用户先访问一次数据,也就是说第一次查询是没有加速收益的。那么对于热点数据,我们可以在用户访问前就预先load到缓存中。对于长时间不会改变且热点的数据,还可以把数据pin在缓存中,不会被淘汰。
建议三:动态判断查询是否需要被加速
有的查询被Alluxio缓存可以带来很好的加速收益,有的则不行。我们可以在查询时动态的判断是否需要让Alluxio缓存。在查询时,解析SQL语句得到查询的表,先去拿到表的元数据,判断数据文件大小,同时也结合SQL的大致复杂度,再决定查询是否要走Alluxio。
建议四:设置单层缓存,使用SSD作为存储介质
Alluxio官方建议不要设置多层缓存,数据在多层缓存中的下沉和上浮可能会对性能有些影响。出于成本和性能的综合考虑,单层缓存的存储介质建议使用SSD。
建议五:合并小文件
小文件过多会影响Alluxio的加速收益,可以对热点数据,在查询前先执行小文件的合并。Alluxio提供了这个功能,可以对Hive表同一分区下的所有文件进行合并,合并后的文件不会覆盖原来的小文件,也不会更改Hive的元数据。当Alluxio要缓存这些小文件时,会直接缓存合并后的文件,大幅提升读取速度。
本文转载自:Alluxio 对 Presto 的查询性能加速测试报告
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Alluxio 对 Presto 的查询性能加速测试报告】(https://www.iteblog.com/archives/10161.html)







