

文章目录
Apache Spark 3.3.0 从2021年07月03日正式开发,历时近一年,终于在2022年06月16日正式发布,在 Databricks Runtime 11.0 也同步发布。这个版本一共解决了 1600 个 ISSUE,感谢 Apache Spark 社区为 Spark 3.3 版本做出的宝贵贡献。根据经验,这个版本应该不是稳定版,想在线上环境使用的小伙伴们可以再等等。

PySpark 的 PyPI 月下载量已经迅速增长到2100万次,Python 现在是最流行的 API 语言。与去年同期相比,PySpark 的月下载量翻了一番。此外,Maven 的月下载量超过2400万次。Spark 已经成为最广泛使用的可伸缩计算引擎。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Spark 3.3 仍然是继续将 Spark 更加统一、简单、快速和可扩展作为目标,基于此目标, Spark 3.3 新增了以下特性:
- 通过 Bloom filters 提升 Join 查询性能,最高可提高10倍的速度。
- Pandas API 的覆盖率更加全面,比如这个版本新增了
datetime.timedelta和merge_asof。 - 通过改进 ANSI 兼容性和新增几十个新的内置函数来简化从传统数据仓库的迁移。
- 通过更好的错误处理、自动完成(autocompletion)、性能提升和 profiling 来提高开发效率。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
性能提升
Bloom Filter Joins
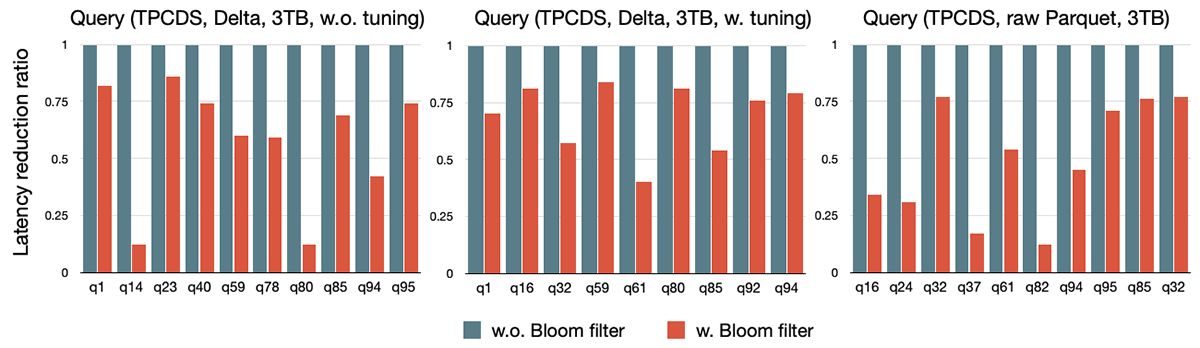
Spark 可以根据需要在查询计划中注入和下推 Bloom Filter,以便在早期过滤数据,减少 shuffle 和后期计算的中间数据大小。Bloom 过滤器是行级运行时过滤器(row-level runtime filters),用于补充动态分区修剪(dynamic partition pruning,DPP)和动态文件修剪(dynamic file pruning,DFP),以适应动态文件跳过(dynamic file skipping)不够适用或不够彻底的情况。如下图所示,社区在三种不同的数据源变体上运行 TPC-DS 基准测试:未调优的 Delta Lake、调优的 Delta Lake 和原始 Parquet 文件,通过启用这个 Bloom 过滤器特性,我们观察到速度提高了约10倍。如果缺乏存储调优或准确的统计数据(例如调优前的 Delta Lake 数据源或基于原始 Parquet 文件的数据源),性能改进的比率会更大。在这些情况下,Bloom 过滤器使查询性能更加健壮,而无需进行存储/统计调优。关于 Bloom Filter Joins 可以参见 SPARK-32268。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
查询执行的改进
这个版本中有几个自适应查询执行(AQE)的改进:
- 通过 Aggregate/Union 传递临时的 empty relation,具体参见 SPARK-35442;
- 在普通和 AQE 优化器中优化单行查询计划,具体参见 SPARK-38162;
- 支持消除 AQE 优化器中 limit。
Whole-stage codegen 也在多个方面进行了改进:
- Full outer sort merge join 支持代码生成,具体参见 SPARK-35352,性能提升 20%~30%;
- Full outer shuffled hash join 支持代码生成,具体参见 SPARK-32567,性能提升 10%~20%;
- Existence sort merge join 支持代码生成,具体参见 SPARK-37316;
- Sort aggregate without grouping keys 支持代码生成,具体参见 SPARK-37564。
Spark Parquet vectorized readers 支持嵌套类型
这个改进在 Spark 的 Parquet 向量化读取器中增加了对复杂类型(如 list、map 以及 array)的支持。微基准测试显示,Spark 在扫描 struct 字段时平均可以提高约15倍的性能,在读取包含 struct 和 map 类型元素的数组时平均可以提高约1.5倍的性能。性能测试包括可以参见 https://github.com/apache/spark/pull/33695,Spark Parquet vectorized readers 支持嵌套类型的 ISSUE 可以参见 SPARK-34863。
Pandas 扩展
优化默认索引
在这个版本中,Spark 上的 Pandas API 将默认索引从 sequence 切换到 distributed-sequence,后者可以通过 Catalyst Optimizer 进行优化。在 i3.xlarge 5 节点集群的基准测试中,Spark 上的 Pandas API 中使用默认索引扫描数据的速度提高了 2 倍。关于 Optimized Default Index 可以参见 SPARK-37649。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Pandas API 覆盖率
PySpark 现在在 Spark 上通过 Spark SQL 和 Pandas API 可以原生地支持 datetime.timedelta(参见 SPARK-37275、SPARK-37525),这个函数返回的 Python 类型现在映射到 Spark SQL 中的 date-time interval 类型。 此外,在此版本中,Pandas API on Spark 现在支持许多缺少的参数和新的 API 功能。 包括 ps.merge_asof (SPARK-36813)、ps.timedelta_range (SPARK-37673) 和 ps.to_timedelta (SPARK-37701) 等。
迁移简化
ANSI 增强
这个版本完成了对 ANSI interval 数据类型 (SPARK-27790) 的支持。 现在我们可以从表中读取/写入 interval 值,并在许多函数/运算符中使用 interval 来进行日期/时间运算,包括聚合和比较。 ANSI 模式下的隐式转换现在支持类型之间的安全转换,同时防止数据丢失。 不断增长的“try”函数库,例如“try_add”和“try_multiply”,补充了 ANSI 模式,允许用户接受 ANSI 模式规则的安全性,同时仍然允许容错查询。
新增内置函数
除了 try_* 函数 (SPARK-35161),这个新版本现在还包括九个新的线性回归函数和统计函数、四个新的字符串处理函数、aes 加密和解密函数、通用的 floor和 ceiling 函数、“to_number”格式化以及许多其他函数 .
生产力提升
错误消息改进
这个版本中引入了诸如“DIVIDE_BY_ZERO”之类的显式错误类,这些使在线搜索有关错误的更多上下文变得更加容易,完整的显式错误类可以参见 https://docs.databricks.com/error-messages/index.html。
对于许多运行时错误,Spark 现在返回错误发生的确切上下文,例如指定的嵌套视图主体中的行号和列号。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Profiler for Python/Pandas UDFs
这个版本引入了一个新的 Python/Pandas UDF 分析器,它提供了具有有用统计信息的 UDF 确定性诊断。Profiler for Python/Pandas UDFs 可以参见 SPARK-37443。下面是一个使用新的基础架构运行 PySpark 的示例:
% ./bin/pyspark --conf spark.python.profile=true

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
通过 Type Hint Inline Completion 实现更好的自动补全
在这个版本中,所有类型提示都从存根文件迁移到了内联类型提示,以实现更好的自动补全。例如,显示参数的类型有助于提供有用的上下文。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在这篇博文中,我们总结了 Apache Spark 3.3.0 中的一些高级特性和改进。大家可以留意 Databricks 的官方博客了解深入探讨这些功能的文章。所有 Spark 组件和已解决的 JIRA 单子的主要功能的完整列表,请访问 Apache Spark 3.3.0 release notes。
本文翻译自:Introducing Apache Spark™ 3.3 for Databricks Runtime 11.0
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【历时一年 Apache Spark 3.3.0 正式发布,新特性详解】(https://www.iteblog.com/archives/10185.html)






