

文章目录
随着 Spark >= 3.3(在 3.4 中更加成熟)中引入的存储分区连接(Storage Partition Join,SPJ)优化技术,您可以在不触发 Shuffle 的情况下对分区的数据源 V2 表执行连接操作(当然,需要满足一些条件)。

Shuffle 是昂贵的,尤其是在 Spark 中的连接操作中,主要原因包括:
•Shuffle 需要跨网络传输数据,这是 CPU 密集型的。•在 Shuffle 过程中,Shuffle 文件被写入本地磁盘,这是磁盘 I/O 昂贵的。
数据源 V2 表是开放格式表,例如 Apache Hudi、Apache Iceberg 和 Delta Lake 表。
在撰写本文时,SPJ 支持目前仅在 Apache Iceberg 1.2.0 及以上版本中提供。
本文将涵盖以下内容:
•SPJ 工作的要求是什么?•需要设置哪些配置才能让 SPJ 工作?•如何检查 SPJ 是否为您的 Spark 作业工作?•通过了解设置的配置更深入地了解 SPJ。
让我们开始介绍吧。
SPJ 的要求
•目标表和源表都必须是 Iceberg 表。•源表和目标表应该有相同的分区(至少有一个分区列应该相同)。•连接条件必须包括分区列。•必须设置好相关配置•Apache Iceberg 版本 >= 1.2.0 和 Spark 版本 >= 3.3.0。
配置
•spark.sql.sources.v2.bucketing.enabled = true•spark.sql.sources.v2.bucketing.pushPartValues.enabled = true•spark.sql.iceberg.planning.preserve-data-grouping = true•spark.sql.requireAllClusterKeysForCoPartition = false•spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled = true
Partitioning Keys 和 Clustering Keys 指的是同一个概念,可以互换使用。请不要混淆它们。
我将使用 Spark 3.5.0 和 Iceberg 1.5.0 来进行这个操作。
在我们深入探讨 SPJ 之前,让我们先创建一些模拟数据,并查看当 SPJ 不工作时 Spark join plan 的实际样子:
初始化 SparkSession
我们将初始化一个 Spark Session,其中包含所有与 Iceberg 相关的配置,但首先不包含 SPJ 配置:
from pyspark.sql import SparkSession, Row
# update here the required versions
SPARK_VERSION = "3.5"
ICEBERG_VERSION = "1.5.0"
CATALOG_NAME = "local"
# update this to your local path where you want tables to be created
DW_PATH = "/path/to/local/warehouse"
spark = SparkSession.builder \
.master("local[4]") \
.appName("spj-iceberg") \
.config("spark.sql.adaptive.enabled", "true")\
.config('spark.jars.packages', f'org.apache.iceberg:iceberg-spark-runtime-{SPARK_VERSION}_2.12:{ICEBERG_VERSION},org.apache.spark:spark-avro_2.12:3.5.0')\
.config('spark.sql.extensions','org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')\
.config(f'spark.sql.catalog.{CATALOG_NAME}','org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.type','hadoop') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.warehouse',DW_PATH) \
.config('spark.sql.autoBroadcastJoinThreshold', '-1')\
.enableHiveSupport()\
.getOrCreate()
准备数据
我们将创建并写入两张 Iceberg 表:
数据是使用 Faker Python 库模拟生成的。如果你没有这个库:
pip install faker
# Creating Mockup data for Customers and Orders table.
from pyspark.sql import Row
from faker import Faker
import random
# Initialize Faker
fake = Faker()
Faker.seed(42)
# Generate customer data
def generate_customer_data(num_customers=1000):
regions = ['North', 'South', 'East', 'West']
customers = []
for _ in range(num_customers):
signup_date = fake.date_time_between(start_date='-3y', end_date='now')
customers.append(Row(
customer_id=fake.unique.random_number(digits=6),
customer_name=fake.name(),
region=random.choice(regions),
signup_date=signup_date,
signup_year=signup_date.year # Additional column for partition evolution
))
return spark.createDataFrame(customers)
# Generate order data
def generate_order_data(customer_df, num_orders=5000):
customers = [row.customer_id for row in customer_df.select('customer_id').collect()]
orders = []
for _ in range(num_orders):
order_date = fake.date_time_between(start_date='-3y', end_date='now')
orders.append(Row(
order_id=fake.unique.random_number(digits=8),
customer_id=random.choice(customers),
order_date=order_date,
amount=round(random.uniform(10, 1000), 2),
region=random.choice(['North', 'South', 'East', 'West']),
order_year=order_date.year # Additional column for partition evolution
))
return spark.createDataFrame(orders)
# Generate the data
print("Generating sample data...")
customer_df = generate_customer_data(1000)
order_df = generate_order_data(customer_df, 5000)
customer_df.show(5, truncate=False)
order_df.show(5, truncate=False)
将数据写入到 Iceberg 表:
customer_df.writeTo("local.db.customers") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()
order_df.writeTo("local.db.orders") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()
关闭 SPJ 来 JOIN customers 和 orders 表:
CUSTOMERS_TABLE = 'local.db.customers'
ORDERS_TABLE = 'local.db.orders'
cust_df = spark.table(CUSTOMERS_TABLE)
order_df = spark.table(ORDERS_TABLE)
# Joining on region
joined_df = cust_df.join(order_df, on='region', how='left')
# Generated plan from
joined_df.explain("FORMATTED")
# triggering an action
joined_df.show(1)
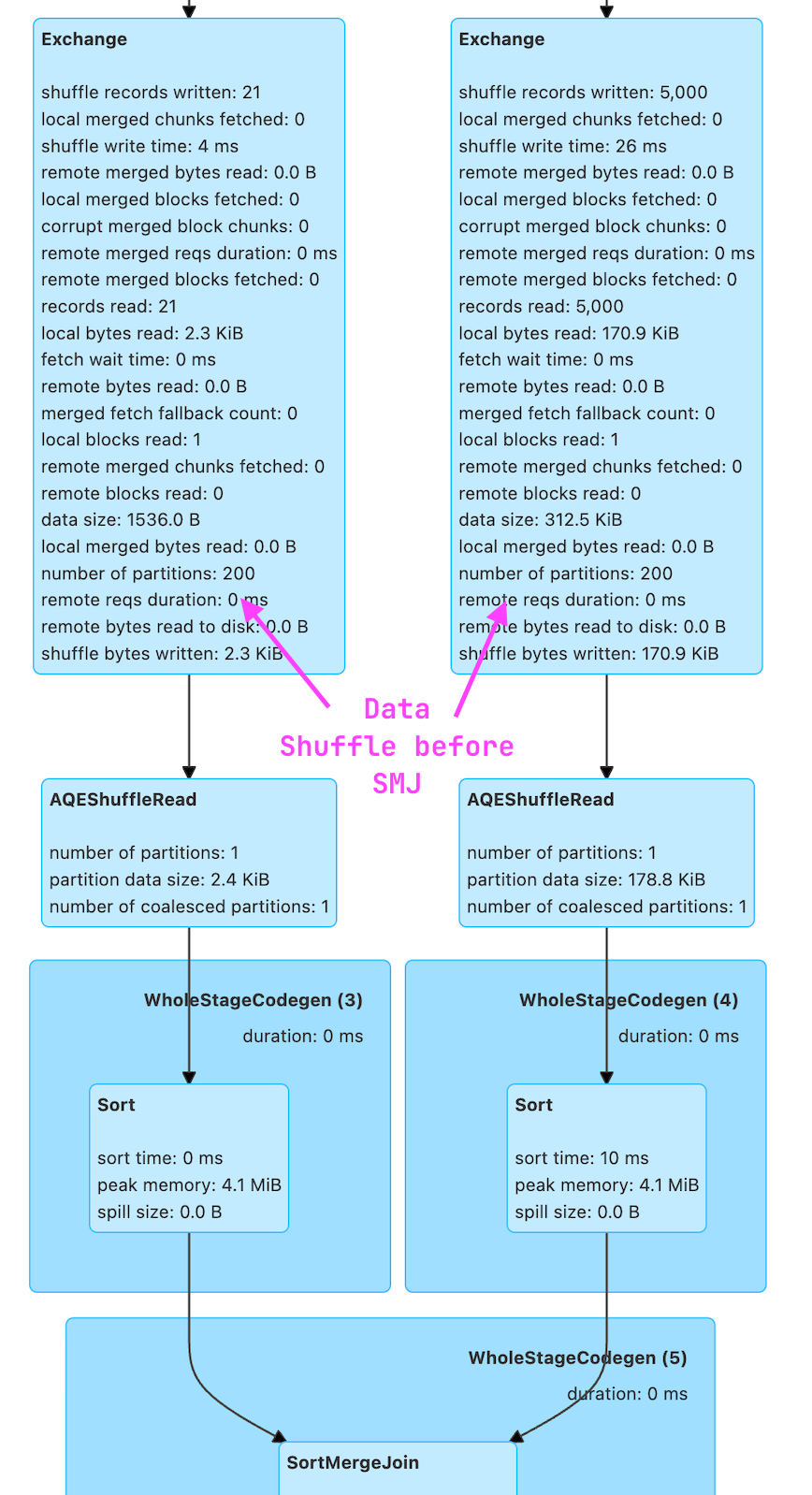
下面是这个查询的执行计划图:
== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)
上述计划中的 Exchange 节点代表了 shuffle 操作。
如果你更习惯使用 Spark UI,那么也可以在那里看到这个信息。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
开启 SPJ 来 JOIN customers 和 orders 表:
设置以下参数将在查询中开启 SPJ
# Setting SPJ related configs
spark.conf.set('spark.sql.sources.v2.bucketing.enabled','true')
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
spark.conf.set('spark.sql.iceberg.planning.preserve-data-grouping','true')
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
spark.conf.set('spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled','true')
我们来执行上面一样的查询,然后查看执行计划有什么变化:
joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")
joined_df.show()
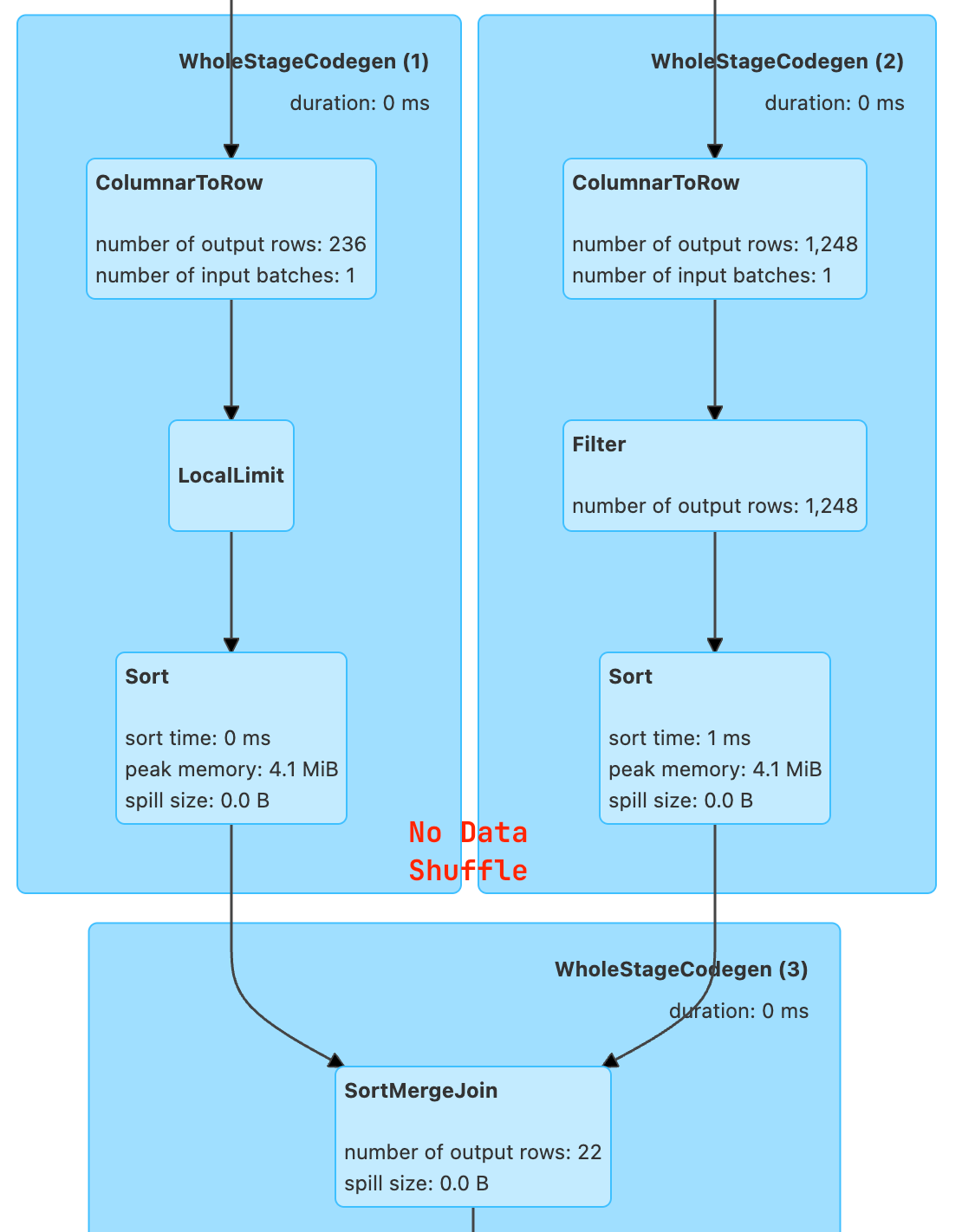
我们在下面的执行计划中看不到 Exchange 节点了,这代表没有 SHUFFLE 操作!
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)
我们可以到 Spark UI 确定这个:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这确实令人惊叹,但嘿,等等,那是理想情况,我们的表以相同方式分区,并且连接仅使用分区列。在现实世界中,这种情况很少见。
有道理!让我们深入了解它的工作原理,并查看一些类似于现实情况的连接条件,以检查 SPJ 是否会起作用。
了解 SPJ 中使用的配置
Storage Partitioned Join 利用现有的存储布局来避免 shuffle 阶段。
SPJ 工作的必要和最低要求是设置可以提供此信息的配置,即:
spark.sql.iceberg.planning.preserve-data-grouping 当为真时,查询计划期间保留分区信息。这防止了不必要的重新分区,通过减少执行期间的 shuffle 成本来优化性能。
spark.sql.sources.v2.bucketing.enabled 当为真时,尝试通过使用兼容的 V2 数据源报告的分区来消除 shuffle。
让我们看看各种连接场景:
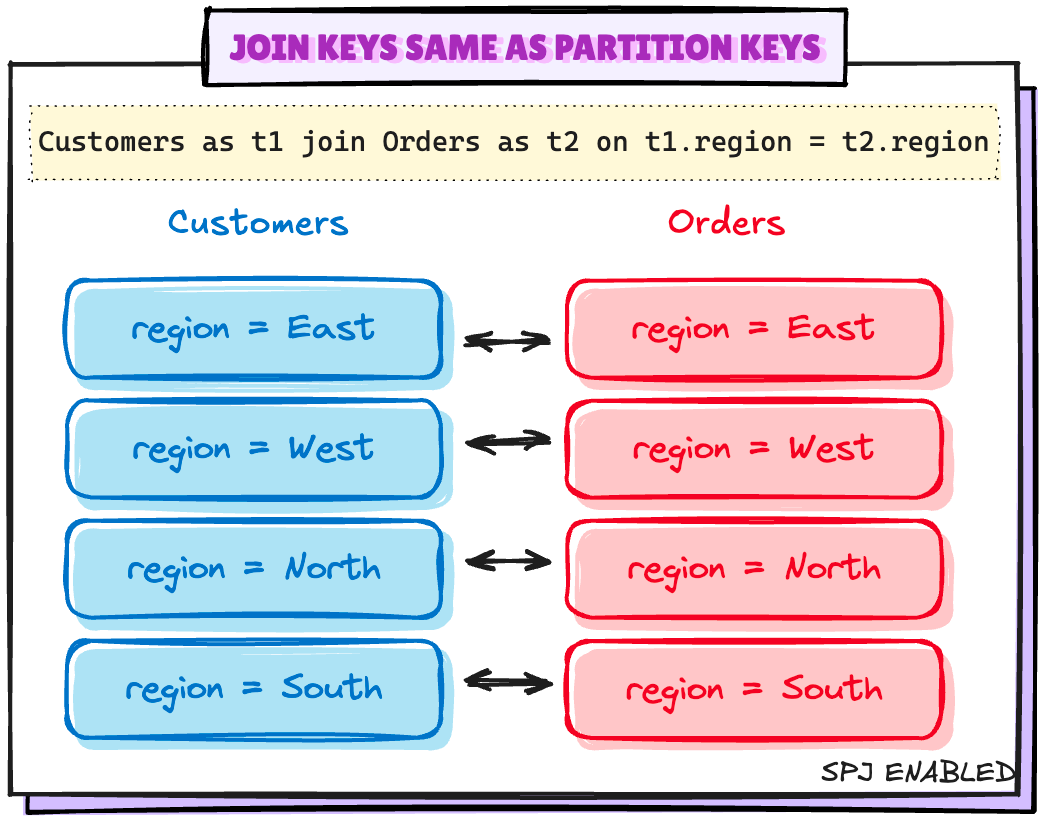
场景 1:连接键与分区键相同
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
# Setting up the minimum configuration for SPJ
spark.conf.set("spark.sql.sources.v2.bucketing.enabled", "true")
spark.conf.set("spark.sql.iceberg.planning.preserve-data-grouping", "true")
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)
计划中没有 Exchange 节点。所以在这种情况下,最小配置是有效的。
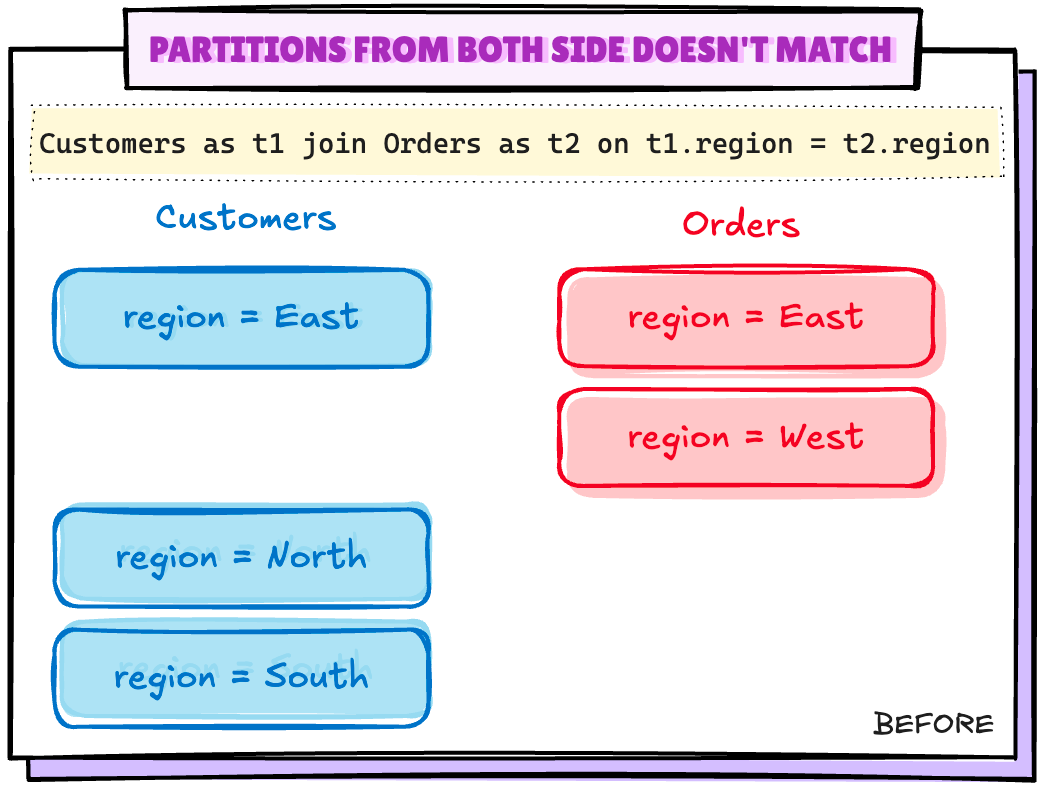
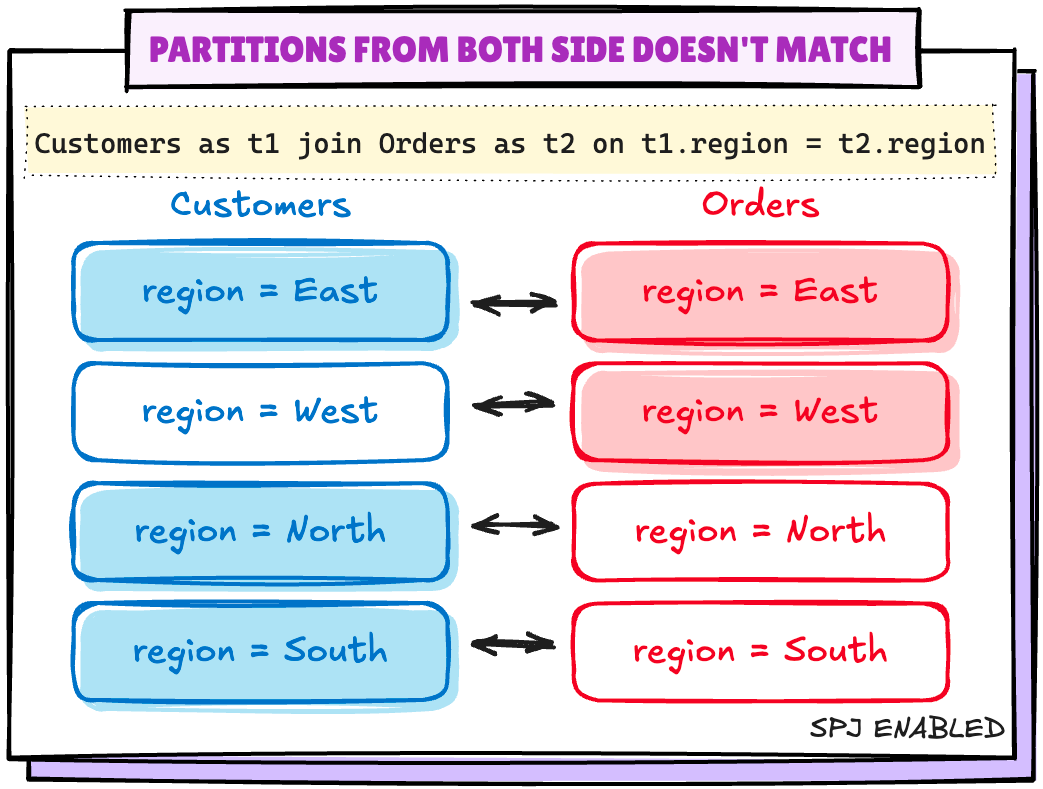
场景 2:双方的分区不匹配
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
让我们通过从 Orders 表中删除一个分区来创建这种场景
# Deleting all the records for a region
spark.sql("DELETE FROM {ORDERS_TABLE} where region='West'")
# Validating if the partition is dropped
orders_df.groupBy("region").count().show()
+------+-----+ |region|count| +------+-----+ | East| 1243| | North| 1267| | South| 1196| +------+-----+
现在让我们检查相同连接条件下的计划:
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")
== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)
Exchange(Shuffle)又回来了..‼️
为了处理这种情况,Spark 在启用上述配置后会为缺失的分区值创建空分区:
spark.sql.sources.v2.bucketing.pushPartValues.enabled 当启用时,如果连接的一侧缺少另一侧的分区值,尝试消除 shuffle。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
我在代码里面开启 spark.sql.sources.v2.bucketing.pushPartValues.enabled
# Enabling config when there are missing partition values
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")
这时候的查询计划如下:
== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)
不再有 shuffle..!!
场景 3:连接键与分区键不匹配
这种情况可能有以下两种情况:
•连接键是分区键的超集•连接键是分区键的子集
3.1 连接键是分区键的超集
这些是在连接中除了分区键之外还有额外字段的查询,例如:
Select * from Customers as t1 join Orders as t2 on t1.region = t2.region and t1.customer_id = t2.customer_id -- additional column `customer_id`
默认情况下,Spark 要求所有分区键必须相同并且有序,以消除 shuffle。可以通过以下设置关闭此行为:
spark.sql.requireAllClusterKeysForCoPartition 当设置为真时,要求连接或合并键与分区键相同且顺序一致,以消除 shuffle。这就是将其设置为 false 的原因。
# Setting up another config to support SPJ for these cases
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
joined_df = cust_df.join(order_df, on=['region','customer_id'], how='left')
joined_df.explain("FORMATTED")
关闭 spark.sql.requireAllClusterKeysForCoPartition 后的查询执行计划:
== Physical Plan ==
AdaptiveSparkPlan (8)
+- Project (7)
+- SortMergeJoin LeftOuter (6)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (5)
+- Filter (4)
+- BatchScan local.db.orders (3)
可以看到,已经没有 shuffle..!!!
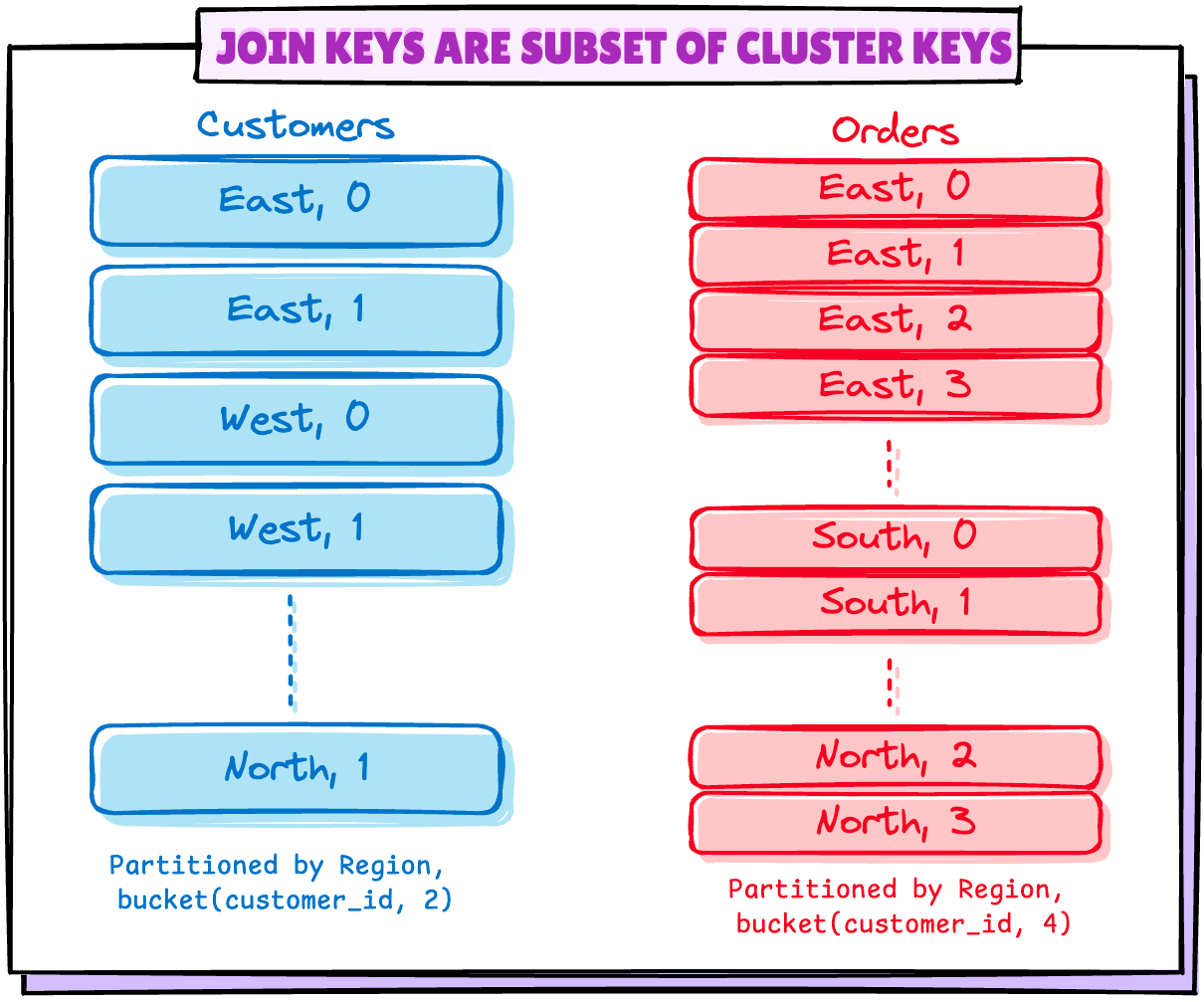
3.2 连接键是分区键的子集
在 Spark < 4.0 中,SPJ 不适用于这种情况。下面的代码示例是在本地构建的最新 Spark 4.0 代码中测试的。
这些情况可能是表格没有以相同方式分区的情况,例如:
•Customers 表按 region 和 bucket(customer_id,2) 分区•Orders 表按 region 和 bucket(customer_id, 4) 分区
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
或者是在多个列上对表进行分区,而连接仅使用其中的少数列进行连接的情况。
在这种情况下,Spark 4.0 会在列 regions 上对输入分区进行分组,类似于下面的方式:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
Spark 4.0 提供了一个配置来启用这一功能—— spark.sql.sources.v2.bucketing.allowJoinKeysSubsetOfPartitionKeys.enabled 当启用时,如果连接条件不包含所有分区列,则尝试避免 shuffle。
// Spark 4.0 SPJ Subset Join Keys test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
object SPJTest {
def main(args: Array[String]): Unit = {
// SparkSession creation
val spark = SparkSession.builder......
//Setting all SPJ configs available in Spark 3.4.0
spark.conf.set("spark.sql.sources.v2.bucketing.enabled","true")
spark.conf.set("spark.sql.iceberg.planning.preserve-data-grouping","true")
spark.conf.set("spark.sql.sources.v2.bucketing.pushPartValues.enabled",
"true")
spark.conf.set("spark.sql.requireAllClusterKeysForCoPartition","false")
// Configuration from Spark 4.0
spark.conf.set("spark.sql.sources.v2.bucketing.allowJoinKeysSubsetOfPartitionKeys.enabled", "true")
// CUSTOMER table partitioned on region, year(signup_date), bucket(2, customer_id)
// ORDER table partitioned on region, year(order_date), bucket(4, customer_id)
val CUSTOMER_TABLE = "local.db.customers_buck"
val ORDERS_TABLE = "local.db.orders_buck"
val cust_df = spark.table(CUSTOMER_TABLE)
val orders_df = spark.table(ORDERS_TABLE)
// join cust_df and orders_df on region alone
val joined_df = cust_df.alias("cust")
.join(orders_df.alias("ord"),
col("cust.region") === col("ord.region"),
"left")
println(joined_df.explain("FORMATTED"))
上面查询执行计划如下:
== Physical Plan ==
AdaptiveSparkPlan (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers_buck (1)
+- Sort (4)
+- BatchScan local.db.orders_buck (3)
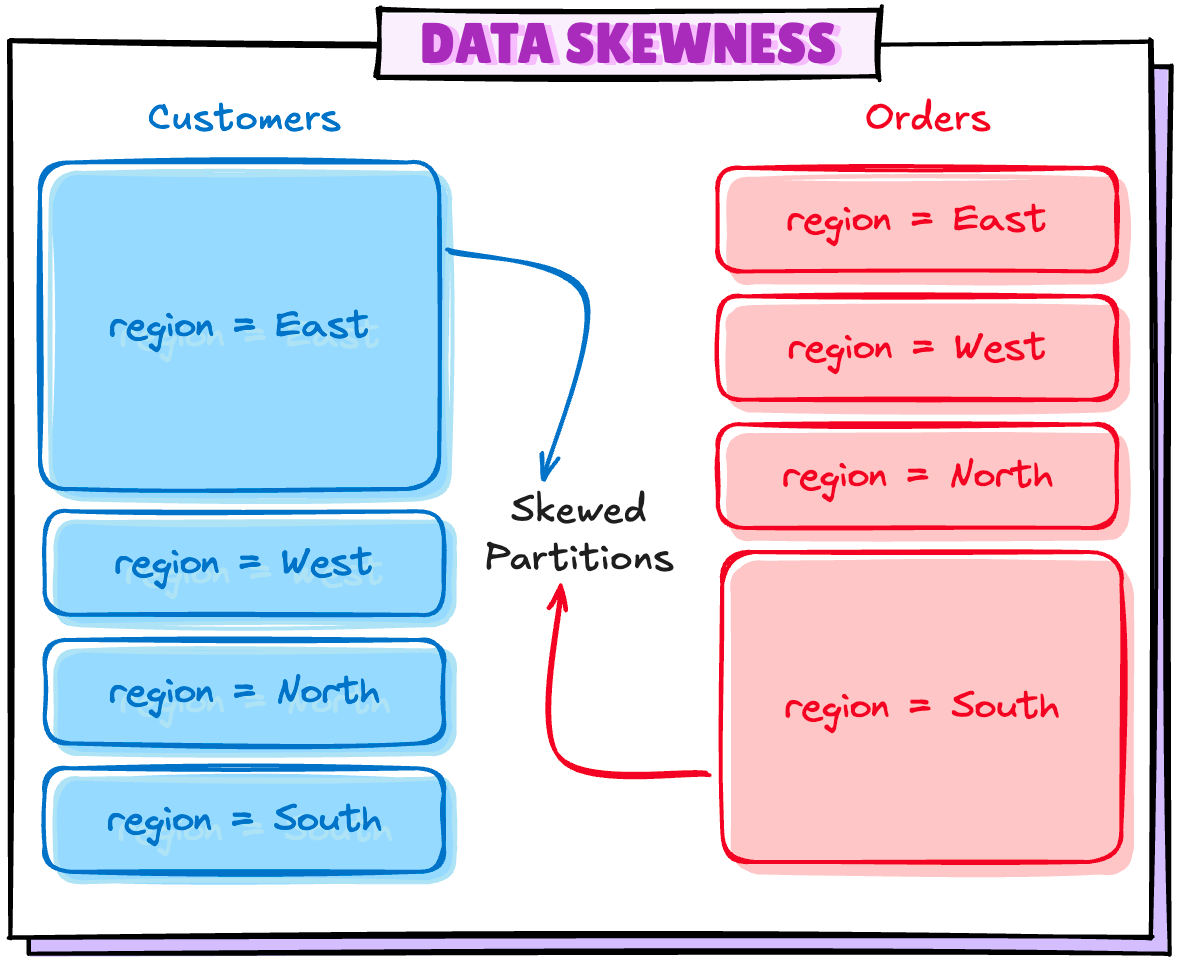
场景 4:分区中的数据偏斜
如果您正在处理繁重的工作负载,数据偏斜是相当常见的问题。假设您的数据分布如下所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
不幸的是,即使经过多次尝试,我也无法复制这种情况,因此这只能是理论上的,也许我会在将来能够复制这种情况后立即更新。
因此,从理论上讲,Spark 提供了一种配置:
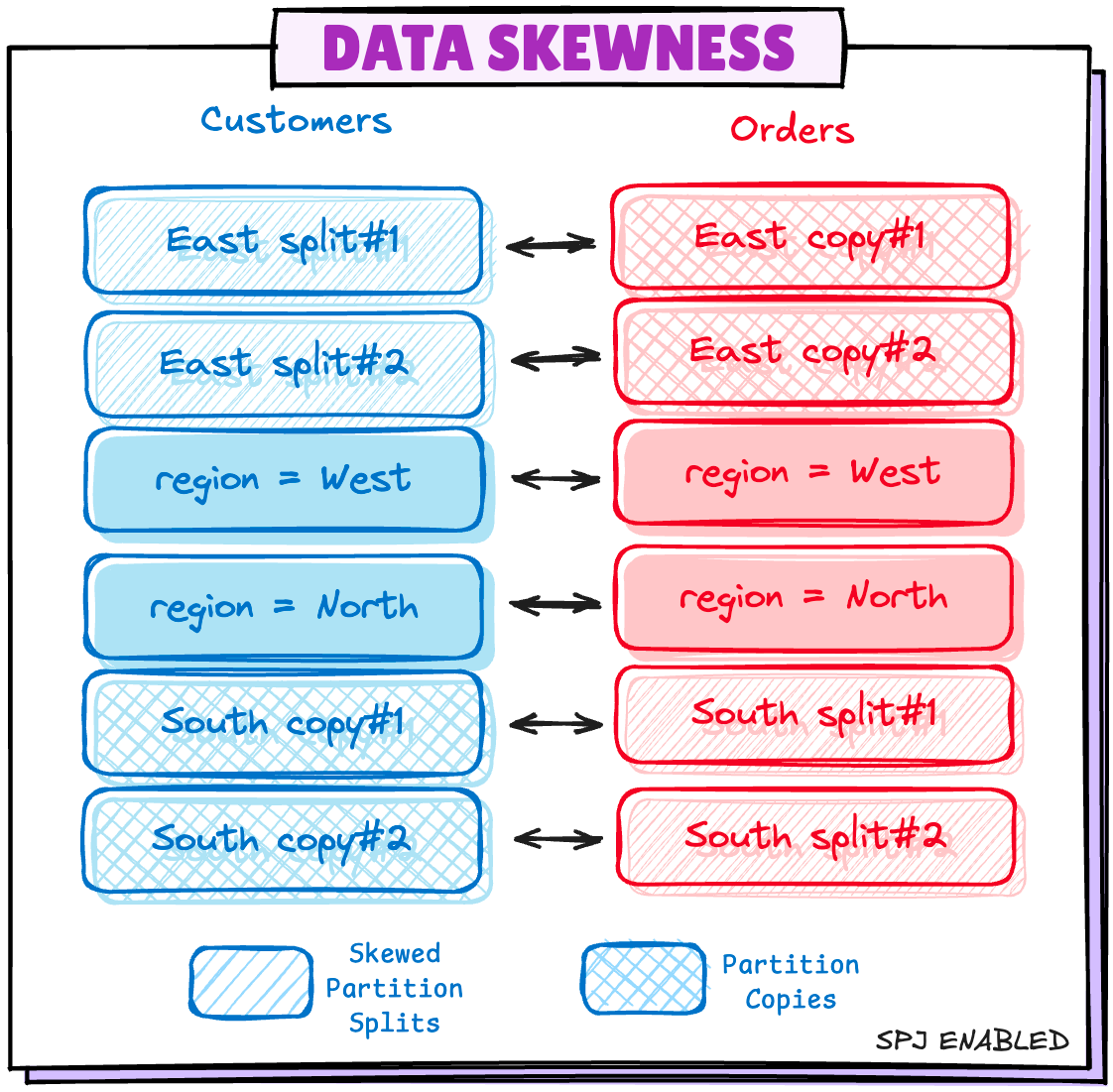
spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled 当设置为真,并且连接不是全外连接时,启用偏斜优化,以在避免 shuffle 时处理包含大量数据的分区。
启用此配置后,Spark 会将偏斜的分区拆分为多个拆分,并将同一分区的另一侧分组并复制以匹配相同的分区。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
region=East 倾斜分区从 Customers 表中拆分为 2 个小分区,在 Orders 表侧,创建了 2 个 region=East 的副本。
参考文献
[1] Storage Partitioned Join Design Doc:https://docs.google.com/document/d/1foTkDSM91VxKgkEcBMsuAvEjNybjja-uHk-r3vtXWFE/edit?ref=guptaakashdeep.com
[2] Spark PR for SPJ:https://github.com/apache/spark/pull/32875?ref=guptaakashdeep.com
[3] Spark PR for Partially Clustered Distribution:https://github.com/apache/spark/pull/32875?ref=guptaakashdeep.com
[4] Spark 4.0.0 preview2 documentation:https://spark.apache.org/docs/4.0.0-preview2/sql-performance-tuning.html?ref=guptaakashdeep.com#converting-sort-merge-join-to-shuffled-hash-join
本文翻译自:https://www.guptaakashdeep.com/storage-partition-join-in-apache-spark-why-how-and-where/
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【告别 Shuffle!深入探索 Spark 的 Storage Partition Join(SPJ) 技术】(https://www.iteblog.com/archives/10226.html)






