

分析型SQL引擎(如Apache Impala)在进行大型表扫描和聚合查询工作负载时非常出色。在大数据生态系统中,单个表的大小可达PB(拍字节)级别,因此要实现快速的查询响应时间,就需要依据WHERE或HAVING子句中的条件对表数据进行智能过滤。
通常会使用一个或多个列来对大型表进行分区,这些列能够有效地对数据进行范围过滤。例如,经常选择日期列作为分区键,这样当SQL查询中指定了日期范围时,就能够排除掉不相关的分区数据。除了在分区级别进行过滤之外,Parquet文件格式还支持基于文件中每个列的最小值和最大值在文件级别进行过滤。这些最小/最大列值存储在文件的尾部(页脚)中。如果文件中的最小值和最大值范围与查询所指定的数据范围没有重叠,那么系统在扫描时就会跳过整个文件。
过去,在过滤文件级别的最小/最大统计数据时比较粗糙:如果不能跳过整个文件,就必须读取整个文件。然而,随着Parquet格式在CDP(Cloudera Data Platform)1.0版本中加入了Parquet页索引,扫描器能够进一步减少从磁盘读取的数据量,从而为Impala中的SELECT查询带来显著的性能提升。
关于Parquet
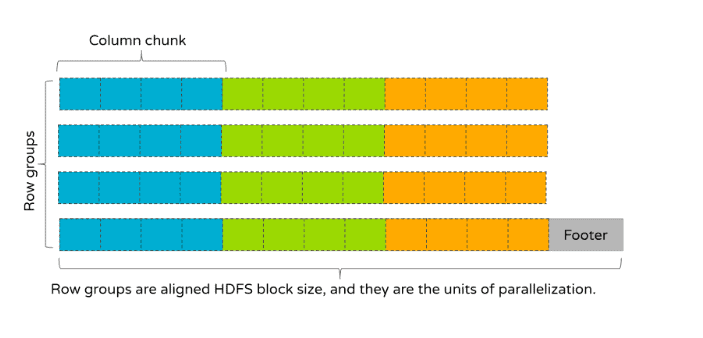
Apache Parquet是一种用于存储数据的二进制文件格式,通常用于存储表数据。Parquet将数据组织成行组,每个行组存储一组行。在内部,行组是按列存储的。这意味着行组被划分为被称为“列块”的实体,之所以称为列块,是因为一个行组只存储一个列的一部分数据。按列存储意味着属于第一个列块的值依次存储在一起,然后是第二个列块的值,依此类推。从这个意义上说,按列存储就是按照列块组织数据,并且列块包含最终存储数据的数据页。在文件的末尾是Parquet页脚,它存储着元数据。
整个Parquet文件看起来如下图(图1)所示。在这个图中,方框代表列值,并且颜色相同的方框属于同一个列块。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
最小/最大值过滤
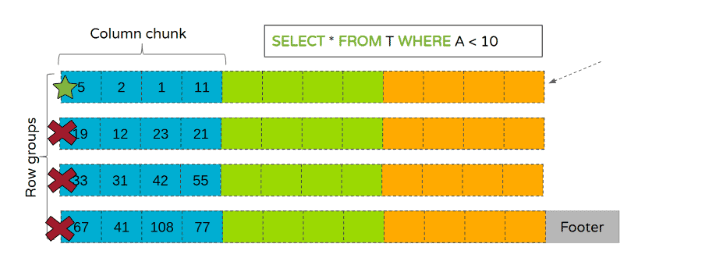
从Parquet 2.0开始,文件可以包含行组级别的统计数据,这些数据包含每个列块的最小值和最大值。这些统计数据可用于在扫描时排除行组,如下图(图2)所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在上述示例中,只有第一个行组满足搜索条件,因为[1, 11]这个范围与A < 10重叠。这就导致只读取第一个行组,而其他行组则被完全跳过。
页索引
页索引功能的工作方式与行组级别的最小/最大值统计数据类似,但粒度更细。顾名思义,页索引存储有关页面的信息,例如它们在文件中的位置、包含哪些行,最重要的是存储值的最小/最大统计信息。页索引本身存储在Parquet文件的页脚中。带有过滤谓词的查询会首先读取页索引,然后确定要对哪些页面执行操作,例如读取、解压、解码等。没有过滤谓词的扫描不需要读取页索引,这样就不会产生运行时开销。
以下示例展示了Parquet页面过滤算法如何利用页面级别的统计数据有效地为带有一个或多个过滤谓词的查询过滤数据。
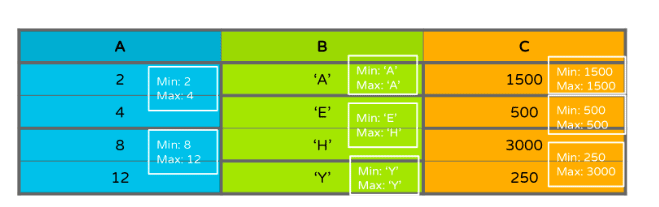
考虑如下表格:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在图3中,粗边框表示页面边界,白色方框显示每个页面存储的最小/最大统计数据。
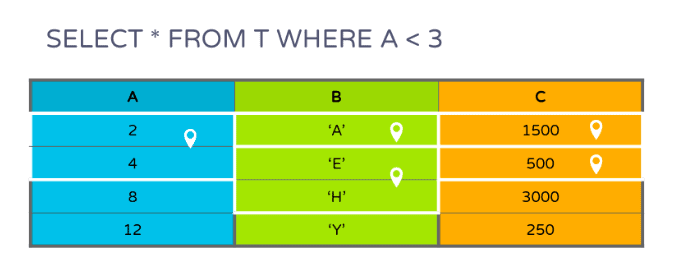
如果有一个WHERE子句中的谓词,只需要扫描一部分页面,如下图(图4)所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
虽然只有一个针对第一列的谓词,但根据匹配的行,也可以从其他列过滤页面。
如果有多个针对列A和B的谓词,只需要扫描C列中包含A和B过滤页面的公共子集行的页面,如下图(图5)所示:
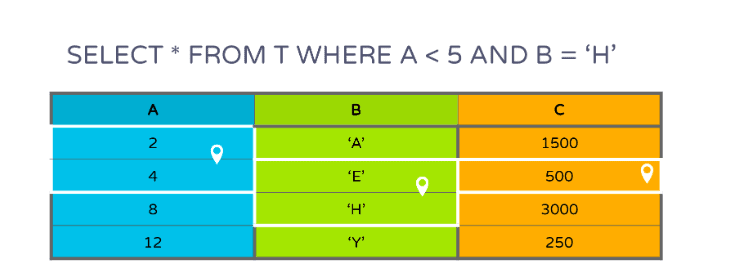
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果有多个针对列A和B的谓词,只需要扫描C列中包含A和B过滤页面的公共子集行的页面,如下图(图6)所示:
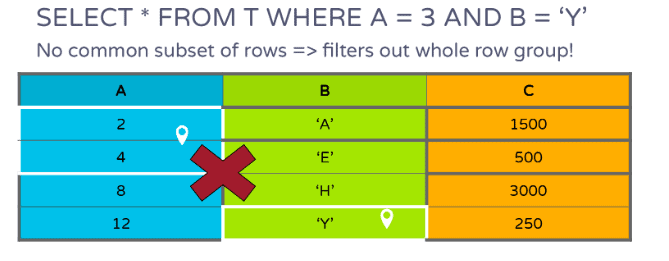
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在图7中,如果数据存在间隙,则可以过滤掉整个行组:
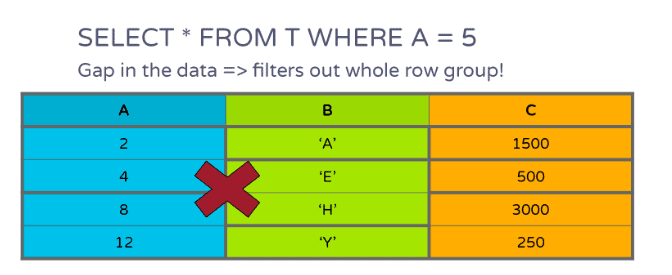
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
使用页索引,可以过滤掉那些无法通过行组级别统计数据过滤掉的整个行组。
页索引功能在排序数据上效果最佳,因为排序数据的页面通常存储不相交的范围,这使得过滤非常高效。当查找异常值时,这个功能也很好用,因为这些值很可能在大多数页面的最小/最大范围之外。页索引可以与分区互补。例如,可以按一组列对数据进行分区,然后使用SORT BY按照另一个在过滤条件中使用的列对数据进行排序。
使用Parquet - MR进行测试
我们使用Parquet - MR对随机生成的数据进行了一系列性能测试。主要目的是衡量SELECT查询的潜在性能提升,并证明该功能不会导致性能退化。
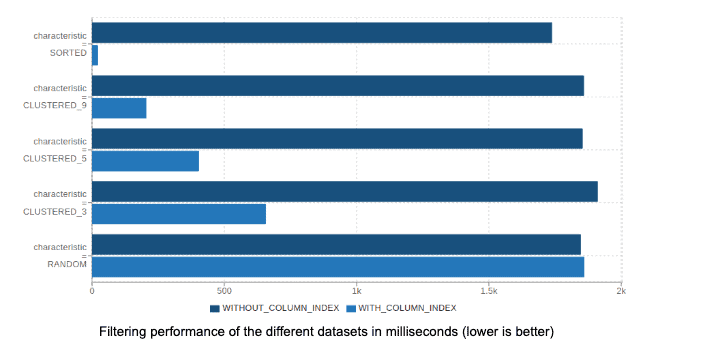
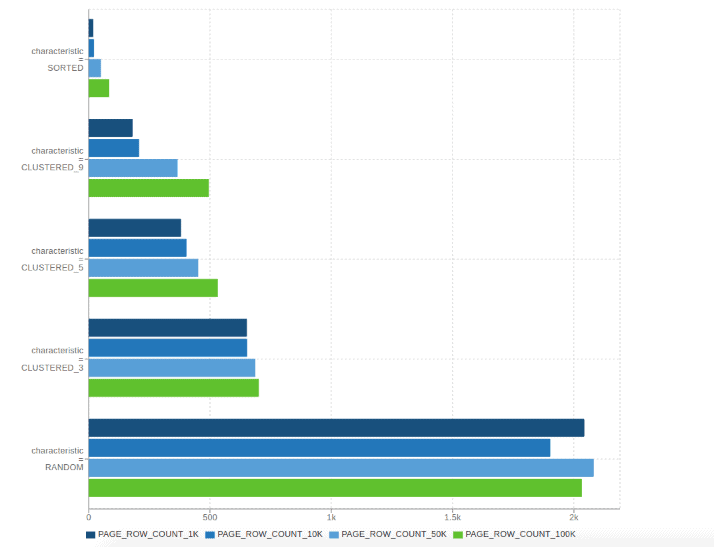
以下图表展示了Parquet - MR从五个不同特性角度针对简单SELECT查询(如column = x)在数据集上的性能表现。使用了以下数据集:
SORTED:我们生成随机数据然后对整个数据进行排序。
CLUSTERED_n:我们生成随机数据,将其拆分成n个桶然后分别对每个桶进行排序。这模拟了现实工作负载中出现的部分排序数据,例如由事件时间戳组成的数据集。
RANDOM:我们生成随机数据并且没有应用任何排序。
排序后的数据集最适合页索引。即使是部分排序的数据也比完全随机的数据表现得好得多。这些示例还表明,在纯随机数据上使用页索引不会有显著的性能损失。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这些示例还表明,从“页索引”的角度来看,列块中的页面越多越好。在开发这个功能之前,Parquet - MR只有一个可以控制列块中页面数量的属性:parquet.page.size。使用这个属性存在的问题是,某些编码在某些数据上可能表现得“过于出色”。例如,在高度重复的数据上使用RLE编码。在这种情况下,即使使用较小的页面大小,也会导致一个列块的所有值都只适合一个页面。那么基于页索引就无法进行有效的过滤。
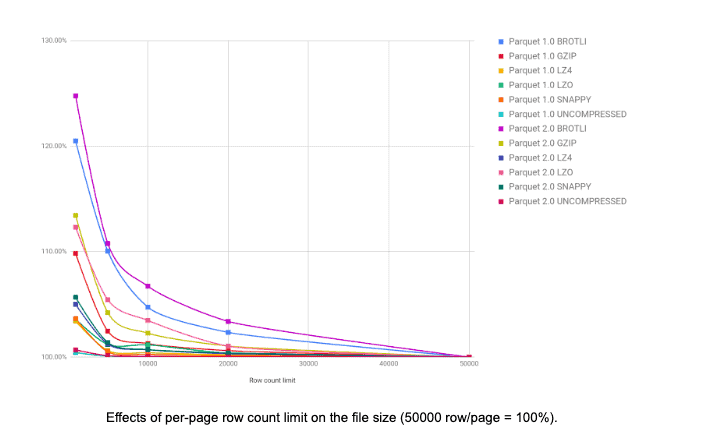
为了解决这个问题,我们引入了新属性parquet.page.row.count.limit。这个属性控制实际页面中的行数。根据以下图表,20,000被选定为默认值,这似乎是性能良好和页面数量较多之间的一个很好的中间值。页面过多会显著增加文件大小。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
不同页面大小的过滤性能(以毫秒为单位)。注意越低越好。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
使用Impala进行测试
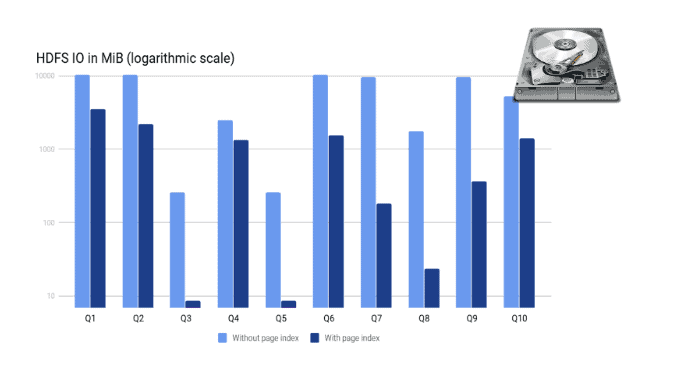
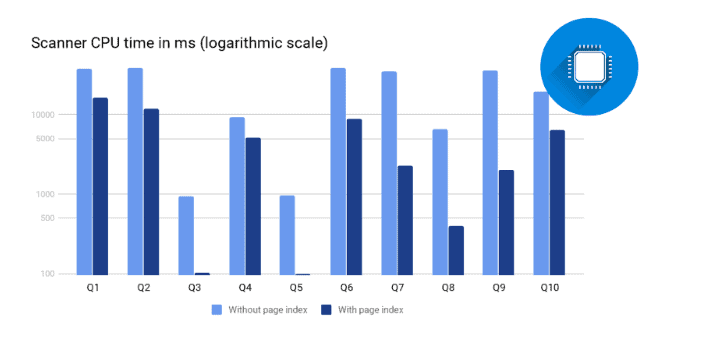
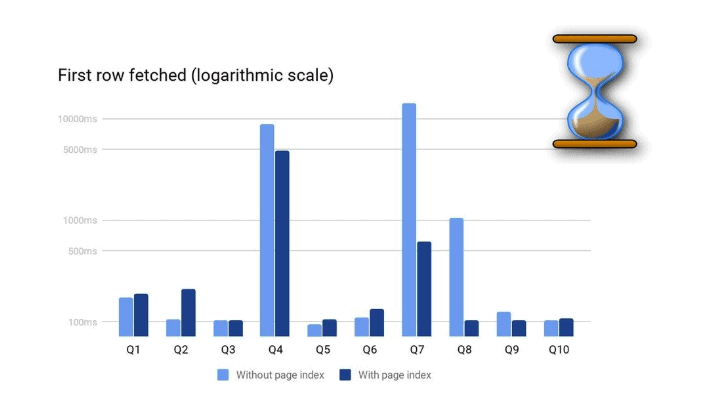
我们使用TPC - H基准测试套件中的LINEITEM表(规模因子为50)并对其编写了多个SELECT查询。该表未分区并且按照L_ORDERKEY列进行排序。所有查询都在单线程上执行,以便将测量重点放在扫描速度的提升上。
测试使用了以下查询:
- Q1: select * from lineitem where l_suppkey = 10
- Q2: select * from lineitem where l_suppkey > 499995;
- Q3: select * from lineitem where l_orderkey = 1
- Q4: select * from lineitem where l_orderkey = 73944871
- Q5: select * from lineitem where l_orderkey < 1000;
- Q6: select * from lineitem where l_extendedprice < 910
- Q7: select * from lineitem where l_extendedprice = 902.00
- Q8: select * from lineitem where l_extendedprice > 104946.00
- Q9: select * from lineitem where l_receiptdate = ‘1998-12-30’
- Q10: select * from lineitem where l_commitdate = ‘1992-01-31’ and l_orderkey > 210000000
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如上所述,扫描时间与读取的数据量成正比。读取的数据量取决于查询中的实际过滤条件及其选择性。
总结
本文介绍了Parquet页索引功能,并通过示例展示了它如何提高查询性能。它可以在不需要修改查询的情况下显著减少某些工作负载的扫描时间,并大大缩短查询响应时间。该功能在Parquet - MR 1.11.0和Impala 3.3.0版本中发布,并且在CDP 1.0及以上版本中可用。Impala和Parquet - MR默认启用页索引的读写操作。不过请注意,为了获得最佳结果,应该对数据进行排序/聚类。
本文翻译自:Speeding Up SELECT Queries with Parquet Page Indexes
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【通过 Parquet Page Indexes 加速查询性能】(https://www.iteblog.com/archives/10229.html)