

文章目录
0 引言
排序是计算机科学中研究最深入的问题之一。高效排序算法的研究主要集中在缓存效率、减少分支预测错误、并行性和最坏情况模式等关键问题上,但主要限于对大型整数数组进行排序。数据库系统研究主要关注许多相同的问题,并且数据库系统具有一些最实用的排序用例:ORDER BY 和 WINDOW 等算子需要明确使用到排序。因此,拥有高效的排序实现以提供快速查询响应时间至关重要,尤其是对于分析 (OLAP) 数据管理系统而言。对关系数据进行排序比对整数数组进行排序更复杂,本文将详细介绍 Velox 的 OrderBy 算子的实现。
1 OrderBy 算子简介
在 Velox 里面以下的查询执行计划树里面包含 OrderBy 算子。
SELECT c_customer_sk, c_birth_country, c_birth_year
FROM customer
ORDER BY c_birth_country DESC,
c_birth_year ASC NULLS LAST;
在上面查询中,c_birth_country 按降序排列,如果 c_birth_country 相等,则按 c_birth_year 升序排序。通过指定 NULLS LAST,空值将被视为 c_birth_year 列中的最小值。和我们平常了解的排序算法不一样的地方是,除了 c_birth_country 和 c_birth_year 列需要排序,c_customer_sk 也得更着排序。在业界排序的列称为 key columns,而其他要输出的列称为 payload columns。
2 OrderBy 算子实现
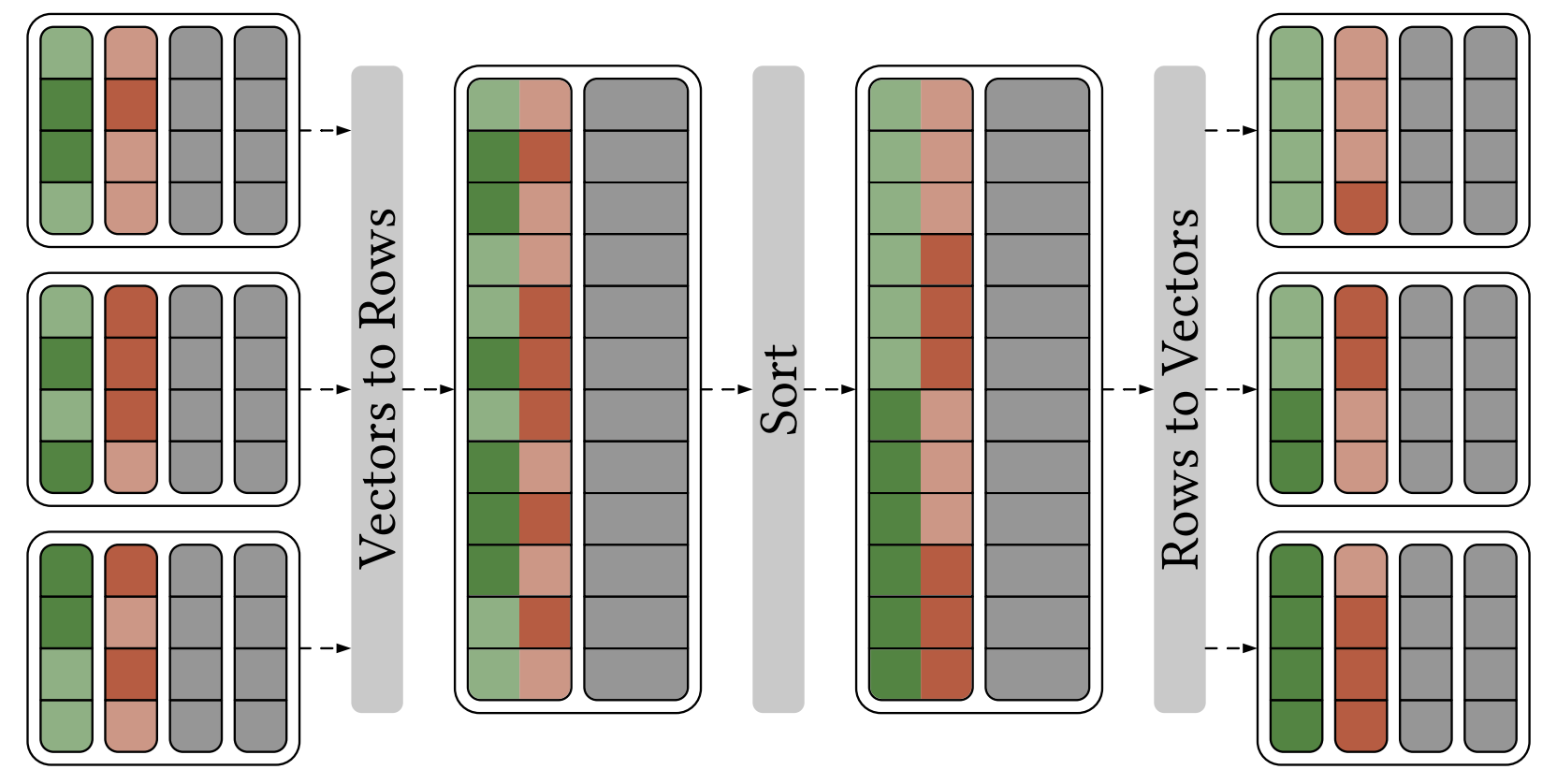
因为本文仅关注排序部分的实现,所以本文将不会关注 orderby 的 spill 相关的逻辑。Velox 的 OrderBy 算子实现主要逻辑是通过 SortBuffer::addInput 把 Vector 里面列存数据转换成行存储到 RowContainer 里面,然后再使用排序算法对 RowContainer 里面行存的数据进行排序,最后通过 RowContainer#extractColumn 把排序后的数据转成 Vector 列存数据,这个列存数据就是我们要的排序结果。主要过程如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
熟悉 Presto 的同学应该知道,Presto OrderBy 的实现是不用将 Page(列存)转换成行存排序的,而是直接基于列存的数据进行排序,在排序过程中仅仅需要移动 Block 里面的序号,最后根据排序后的序号构建新的 Page。虽然 Velox 的 OrderBy 排序需要将 Vector 转成 Row,然后再把排序后的 Row 转换成 Vector。但是根据业界研究表明,无论查询引擎之间的架构差异如何,对行进行排序几乎总是比对列数据进行排序更有效,即使这需要将数据从列转换为行并转回。
排序的过程,主要需要考虑到三件事:
- 选择比较函数(comparison functor);
- 选择比较好的排序算法(sorting algorithm);
- 排序过程中数据的移动,因为 Velox OrderBy 的排序过程均通过移动数据对应的指针来实现数据的移动,所以这个问题我们不关注。
2.1 std::sort
在 Velox 的实现早期中,Orderby 里面的排序算法直接用 C++ 中的 std::sort 来实现的,而比较函数是通过 rowContainer#compare 实现的。如下所示:
std::sort(
rows.begin(), rows.end(), [&](const char* leftRow, const char* rightRow) {
for (auto i = 0; i < compareFlags.size(); ++i) {
if (auto result = rowContainer->compare(
leftRow, rightRow, i, compareFlags[i])) {
return result < 0;
}
}
return false;
});
注意,上面 rows 对应着每行数据在 RowContainer 里面的地址信息。所以上面排序不需要移动数据,只需要移动数据对应的内存地址即可。
可以看到这个实现逻辑很简单,但是有几个问题:
- 数据比较时,数据是直接从底层数据结构中读取,比如这里需要调用 rowContainer#valueAt 拿到对应列的数据。这些操作都会有一些额外的内存访问开销。
- 因为数据可能为 NULL,而这些信息是存储在 rowContainer 里面。每次比较时,我们需要先从 rowContainer 里面读出每个参与计算的列是否为空,然后再读出对应列的数据,这些操作也会有一些额外的内存访问开销。
- RowContainer 里面除了排序键之外,还存储着其他信息,比如每列是否为 null、payload columns 的数据等等。这样,排序所需的数据存储在比实际需要更大的内存块中,存在额外的缓存未命中。
- std::sort 虽然使用方便,但是有其他比他更好的排序算法。
2.2 Timsort
intel 的开发者曾经还给 Velox 提过用 timsort 来替代 std::sort 的,参见 https://github.com/facebookincubator/velox/pull/6745。Benchmark 显示用 timsort 替代 std::sort 性能提升2倍。但是由于 Orderby 算子比较重要,直接替换的话可能有未知的问题,所以当时社区给的方案是先替代 Spiller 中的排序算法,目前来看社区应该也不太可能使用 timsort 来替代 Velox 里面所有的 std::sort。
2.3 PrefixSort
2023年底,阿里的工程师将他们内部的 PrefixSort 实现贡献到 Velox 社区,这个排序已经成为 Velox 里面 ORDER BY 和 WINDOW 等算子的默认排序算法,性能相比 std::sort 方案提升还是很明显的。PrefixSort 主要解决了我前面将的两个大问题:选择比较函数(comparison functor)以及选择比较好的排序算法(sorting algorithm)。
2.3.1 二进制字符比较(Binary String Comparison)
从上面的 std::sort 小结可以看出,std::sort 的比较函数存在诸多问题,最终肯定会影响到排序性能。鉴于每条记录都参与多次比较,如果替代格式可以加快中间排序操作,那么在排序之前和之后重新格式化每条记录似乎是值得的。最适合快速比较的格式是简单的二进制字符串,这样转换既保序又无损。换句话说,键比较的整个复杂性可以降低到比较二进制字符串,并且可以从二进制字符串中恢复排序的输出记录。由于比较两个二进制字符串只需要几十条指令,关系数据库系统早在 System R 中就使用规范化键(normalized keys)进行排序,如果将 key 比较简化为二进制字符串的比较,那么更容易利用硬件资源。
二进制字符串比较技术通过简化比较器来提高排序性能。它将 ORDER BY 子句中的所有列编码为单个二进制字符串,对这个二进制字符串比较时,将产生正确的整体排序顺序。
哪些列可以规范化以及计算规范化字符串长度
为了将所有 key 的列编码成单个二进制字符串,首先要做的是判断 key columns 里面哪些列可以被规范化(normalized )。Velox 先通过 PrefixSortEncoder#encodedSize 计算出支持规范化的列需要占几个字符,比如 INTEGER 占用 4 个字节,BIGINT 占8个字节,如果对应的列有 NULL,那么还需要额外1个字节来标记某一行的某一列是否为空。以下几种情况不支持列的规范化:
- 通过 PrefixSortEncoder#encodedSize 计算出来的 encodedSize 为 std::nullopt;目前 Velox 里面 SMALLINT、INTEGER、BIGINT、HUGEINT(long Decimal)、REAL、DOUBLE、TIMESTAMP、VARBINARY 以及 VARCHAR 类型支持规范化,所以通过 PrefixSortEncoder#encodedSize 能计算出编码的大小,其他列类型直接返回 std::nullopt。比如 order by int_col, bigint_col, tinyint_col, double_col,其中 int_col 和 bigint_col 列类型分别为 INTEGER 和 BIGINT,是支持规范化的;而 tinyint_col 为 tinyint 类型目前不支持规范化(这个 PR 已经支持 tinyint 类型了 https://github.com/facebookincubator/velox/pull/12672),所以从 tinyint_col 列开始,后面的列均不支持规范化,虽然 double_col 列支持规范化,但是其前面字段不支持,所有它也不支持。
- 规范化后的二进制字符是有大小限制的(默认为 128,通过 prefixsort_normalized_key_max_bytes 参数配置)。如果前面支持规范化的列占用的大小加上当前列的 encodedSize大于 prefixsort_normalized_key_max_bytes 配置,那么当前列及后面列都不支持规范化了。
- 如果当前列类型是 VARCHAR 或者VARBINARY,且这列最长的字符串长度大于 prefixsort_max_string_prefix_length 参数配置(默认值为 16),那么当前列仅会把一部分字符串放进规范化的字符串里面,当前列后面的列将不参与规划化操作。
规范化 orderBy 的列
通过前一步,我们已经算出哪些列支持规范化,以及每行规范化后的字符串占用多少字节(entrySize,注意,实际上列的数据规范化后的大小应该为 normalizedBufferSize,但是为了处理不支持规范化列的比较,所以每一行规范化后的字符串后面还会加上当前行在 rowContainer 里面的地址,所以 entrySize = normalizedBufferSize + 8)。
因为最后所有支持规范化的列的数据是需要写到一个字符串里面的,然后进行二进制比较。所以我们需要对每种类型的数据进行编码,编码后的数据写到规范化的字符串里面比较顺序也是要对的。
比如 Velox 里面的整数都是有符号的,而负数的二进制最高位是1,正数的最高位为0。如果直接把整数的这种二进制数据写到规范化的字符串里面,我们比较的时候结果就是错的,因为1大于0。为了解决这个问题,Velox 里面将有符号的整数映射到无符号的整数里面。做法也比较简单,直接将整数的二进制高位取反(比如 value 为 int32_t 类型, 高位取反操作 (uint32_t)(value ^ (1u << 31)))。经过这个操作之后,所有正数的无符号值被提升到 [2ⁿ⁻¹, 2ⁿ) 区间,负数的无符号值被限制在 [0, 2ⁿ⁻¹) 区间。因此,正数的无符号值必然大于所有负数的无符号值,这样就能保证整数写到规范化的字符串里面比较顺序也是对的。
另一方面,我们的服务器基本都是采用 little endian 编码的。比如整数18,二进制为 00000000 00000000 00000000 00010010,如果采用 little endian 编码,那么在内存的表示则为 00010010 00000000 00000000 00000000,如下图所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果直接把这个数据写到规范化的字符串里面,二进制 00010010 将被写到字符串的前面,那么比较的结果将是不对的。所以我们需要对这个整数的二进制进行反转操作,比如 Velox 对 uint32_t 类型的二进制数据使用 __builtin_bswap32 进行反转。所以上面的二进制经过反转后在内存的表示如下:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
这样写到二进制字符串里面后进行比较结果就是对的。
Velox 里面所有行和所有列的规范化后的字符串都是写到 prefixBuffer 里面,这个指针的内存是连续存储的。在进行列编码的时候,需要到 rowContainer 里面读出对应的数据。然后按照排序的列顺序依次写到 prefixBuffer 内存里面,每一行排序的列都是写到连续的内存里面,接着写第二行,第三行,以此类推。
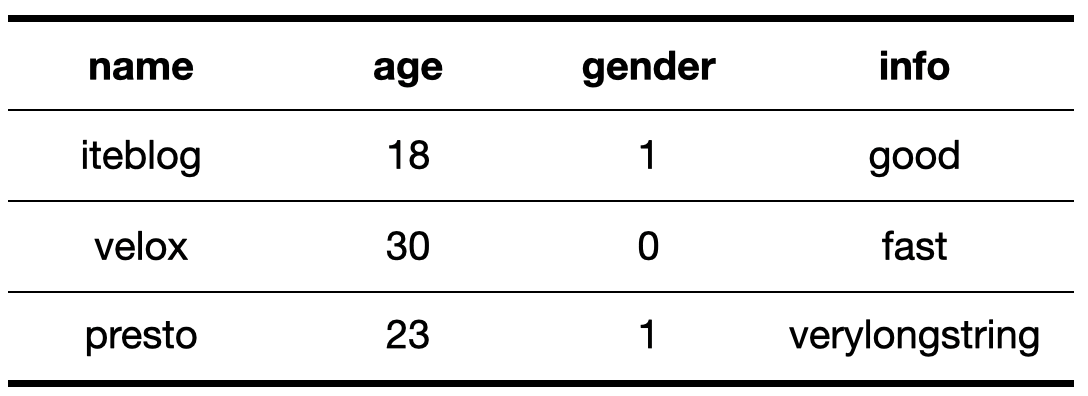
下面我们以一个例子来介绍前缀编码字符串长什么样子。比如我们有一张名为 iteblog 的表,里面有 (name string, age int, gender bool, info string),表里面的数据如下所示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
假设我们的查询为:select * from iteblog order by name, age,那么按照上面的介绍,每列经过规范化后得到如下所示的数据:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
注意,表里面 name 字段所有行的最大长度为7(就是 iteblog 这行),所以其他行里面 name 字段长度小于7,都需要在后面补上0,这样保证每一行 Normalized Key 的长度都一样。另外,为了 CPU cache 效率,每条 Normalized Key 还需要和8字节对齐,比如 Normalized Key 长度为 11,那么和8字节对齐后长度为 16,补齐字节用0补上。
这样第一行数据经过规范化后,得到的二进制字符串(Normalized Key)为 69 74 65 62 6c 6f 67 80 00 00 12 00 00 00 00 00;类似的,第二行数据经过规范化后,得到的二进制字符串(Normalized Key)为 76 65 6c 6f 78 00 00 80 00 00 1e 00 00 00 00 00。在 Velox 里面,考虑到 little endian 内存布局,以及 std::memcmp 可能不支持 SIMD 指令,所以为了比较 rowA 以及 rowB 的数据,Velox 还会对 Normalized Key 按每8字节进行反转(使用 __builtin_bswap64 实现),这样第一行排序的key经过反转后的 Normalized Key 就变成 80 67 6f 6c 62 65 74 69 00 00 00 00 00 12 00 00;类似的,第二行数据经过反转后的 Normalized Key 就变成 80 00 00 78 6f 6c 65 76 00 00 00 00 00 1e 00 00。
当 key 中有些列不支持规范化,而且两行数据的 Normalized Key 比较结果一样,那么我们还是需要退化到通过 rowContainer#compare 来比较剩下 key。为了达到这个目的,我们需要在每行 Normalized Key 后面加上此行在 rowContainer 里面的指针地址,这个地址指针占用8个字节,所以最终每行 key 经过 Key normalization 后得到的 Normalized Key 如下所示:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
图中 entrySize = normalizedBufferSize + 8。我们前面说过,每行数据的 Normalized Key 在内存是连续存储的,以下就是这三行数据经过 Key normalization 的内存表示:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
比较两行数据时,我们可以先比较两行数据的 Normalized Key 。为了提升比较性能,Normalized Key 中每8个字节比较,如果这8个字节比较结果为0,代表数据一样,接着比较下一个8字节即可,直到比较结果不为0即可。
FOLLY_ALWAYS_INLINE int
compareByWord(uint64_t* left, uint64_t* right, int32_t bytes) {
while (bytes != 0) {
if (*left == *right) {
++left;
++right;
bytes -= kAlignment;
continue;
}
if (*left > *right) {
return 1;
} else {
return -1;
}
}
return 0;
}
如果有 key 不支持规范化,且对比两行数据的 Normalized Key 一样,我们还需要通过 rowContainer#compare 来比较剩下 key:
int PrefixSort::comparePartNormalizedKeys(char* left, char* right) {
int result = compareAllNormalizedKeys(left, right);
if (result != 0) {
return result;
}
// If prefixes are equal, compare the remaining sort keys with rowContainer.
char* leftRow = getRowAddrFromPrefixBuffer(left);
char* rightRow = getRowAddrFromPrefixBuffer(right);
for (auto i = sortLayout_.nonPrefixSortStartIndex; i < sortLayout_.numKeys;
++i) {
result = rowContainer_->compare(
leftRow, rightRow, i, sortLayout_.compareFlags[i]);
if (result != 0) {
return result;
}
}
return result;
}
NULL 值处理
如果我们比较的数据里面还有 NULL 怎么处理呢?我们在算 normalizedBufferSize 的时候,还需要额外一个字节来表示当前行是否为NULL,并结合 nullsFirst 来赋值0或1,具体规则如下:
- nullsFirst:null 的数据设置为 0, 非空的数据为 1;
- nullsLast:null 的数据设置为 1, 非空的数据为 0。
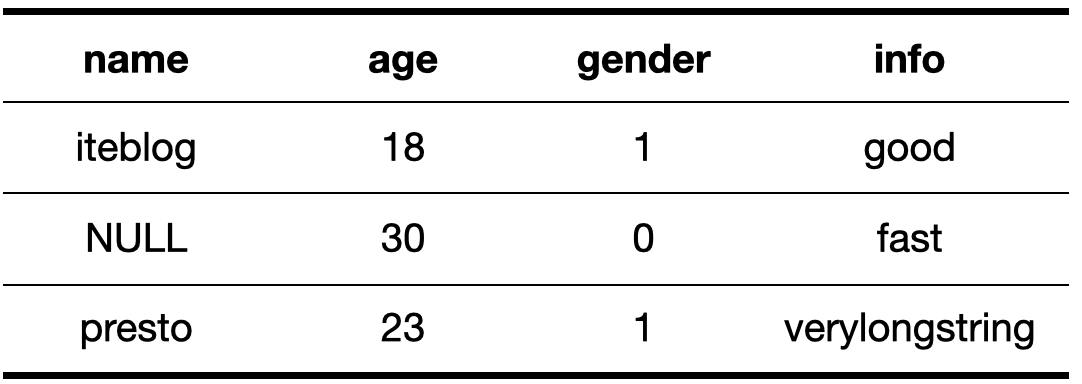
我还是以一个例子来介绍。比如现在表的数据如下:
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
查询还是 select * from iteblog order by name, age。经过 Key normalization 后得到的 Normalized Key 如下:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
除了 name 这列规划化第一个位置多了一个 01 或 00,以及第二行为 NULL 的数据全部用0补上,其他步骤和前面介绍的一样,就不再介绍了。
DESC 排序
我们前面介绍的例子都是使用 ASC 排序的,也就是升序排序。那如果我们要求按降序排,该如何处理。这个也很简单,假设我们是两个整数比较,因为前面我们说了有符号的整数都会转换成无符号的整数,如果 a < b,那么我们可以推断出 ~a > ~b,证明过程如下:
~a = 2ⁿ - 1 - a 且 ~b = 2ⁿ - 1 - b
由于 a < b,可得:
~a - ~b = (2ⁿ - 1 - a) - (2ⁿ - 1 - b) = b -a >0
因此:~a > ~b
因为我们规范化的时候,字符串长度是要对齐的(不足的位补上0),所以这个结论也可以推到字符串中,我们只需要对字符串的每个字符取反,得到的取反后的字符串就可以按 DESC 排序。
~c = 255−c (假设为 8 位字符),因此,对于任意两个字符 c1 和 c2,可以推断出:c1 < c2 ⟺ ~c1 > ~c2
设字符串 a 和 b 长度均为 n,且在位置 i 处首次出现不同字符(即 a[0..i−1]=b[0..i−1],且 a[i] <> b[i])。
根据字典序:
a < b ⟺ a[i] < b[i]
取反后的字符串 ~a 和 ~b 满足:
对于前 i 个字符:~a[0..i−1] = ~b[0..i−1](因原字符相同)。
在位置 i:~a[i] = 255 - a[i], ~b[i] = 255 − b[i]。
根据字符取反的逆序性:
a[i] < b[i] ⟺ ~a[i] > ~b[i]
因此:~a > ~b(因为 ~a[i] > ~b[i])
所以,对于长度相同的字符串,以下等价关系成立:a < b ⟺ ~a > ~b。
如果是某列是按 DESC 排序,那么我们只需要规范化对应的列数据时,给它取反即可,后面处理的步骤就和前面一样。
2.3.2 排序算法(sorting algorithm)
我们前面已经花了大部分篇幅介绍了如何对排序的列进行规范化,并对规范化后的字符串进行比较,从而得到正确的排序结果。现在我们已经有了比较器,我们就可以实现一个排序算法来快速排序每行数据。Velox 的排序算法和 Presto 一样,都是实现了 Engineering a Sort Function 论文描述的算法。具体思路可以参加论文的描述,我这就不介绍了。
3 结论
Velox 里面的 PrefixSort 排序算法整体性能比之前默认的排序算法,性能有大幅提升。其二进制字符比较的逻辑实现大量参考了 DuckDB 的思路,虽然有一堆繁琐的 key 规范化操作,但是规范化后的 Normalized Key 大大简化了多列的比较,通过内存连续访问实现向量化指令加速,提升了排序的总体性能。另外,当前 Velox 的 OrderBy 算子的实现是需要先把 Vector 里面的数据全部存放到 RowContainer 里面(列转行),然后再通过 rowContainer 里面的数据去构造 Normalized Key,Normalized Key 本身可能也会占用过多的内存,是否可以改造 RowContainer ,让 RowContainer 可以存储排序列的 Normalized Key,从而减少内存的使用呢?
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Velox Orderby PrefixSort 实现】(https://www.iteblog.com/archives/10243.html)





