

求解问题如下:
在本地磁盘里面有file1和file2两个文件,每一个文件包含500万条随机整数(可以重复),最大不超过2147483648也就是一个int表示范围。要求写程序将两个文件中都含有的整数输出到一个新文件中。
要求:
- 程序的运行时间不超过5秒钟。
- 没有内存泄漏。
- 代码规范,能要考虑到出错情况。
- 代码具有高度可重用性及可扩展性,以后将要在该作业基础上更改需求。
初一看,觉得很简单,不就是求两个文件的并集嘛,于是很快写出了下面的代码。
#include<iostream>
#include<vector>
#include<cstdlib>
#include<algorithm>
#include<fstream>
using namespace std;
void merge(const vector<int> &, const vector<int>&, vector<int> &);
// Author: 397090770
// Email: wyphao.2007@163.com
// blog:
// 仅用于学习交流,转载请务必留下这些注释。
int main(){
vector<int> v1, v2;
vector<int> result;
char buf[512];
FILE *fp;
fp = fopen("file1", "r");
if(fp < 0){
cout<<"Open file failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v1.push_back(atoi(buf));
}
sort(v1.begin(), v1.end());
fclose(fp);
fp = fopen("file2", "r");
if(fp < 0){
cout<<"Open file2 failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v2.push_back(atoi(buf));
}
sort(v2.begin(), v2.end());
cout<<v1[v1.size() - 1]<<endl;
cout<<v2[v2.size() - 1]<<endl;
fclose(fp);
merge(v1, v2, result);
cout<<result.size();
ofstream output;
output.open("result");
if(output.fail()){
cerr<<"crete file failed!\n";
exit(1);
}
vector<int>::const_iterator p = result.begin();
for(; p != result.end(); p++){
output<<*p<<endl;
}
output.close();
return 0;
}
void merge(const vector<int>& v1, const vector<int>& v2, vector<int> &result){
vector<int>::const_iterator p1, p2;
p1 = v1.begin();
p2 = v2.begin();
while((p1 != v1.end()) && p2 != v2.end()){
if(*p1 < *p2){
p1++;
}else if(*p1 > *p2){
p2++;
}else{
result.push_back(*p1);
p1++;
p2++;
}
}
}
编译运行:
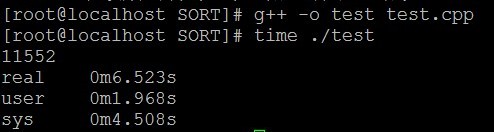
一看,不行,不满足上面的5秒之内,于是又想了很久,上面不是显示sys调用花了很长时间嘛,于是有写了一个程序,用快速排序+二分查找法实现,代码如下:
#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
#include <cstdio>
#define MAXLINE 32
using namespace std;
void qsort(vector<int>&, int, int);
int partition(vector<int>&, int, int);
bool binarySearch(const vector<int>&, int);
// Author: 397090770
// Email: wyphao.2007@163.com
// blog:
// 仅用于学习交流,转载请务必留下这些注释。
int main(){
vector<int> v1, result;
int temp;
char buf[MAXLINE];
FILE *fd;
fd = fopen("file1", "r");
if(fd == NULL){
cerr<<"Open file1 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
v1.push_back(atoi(buf));
}
fclose(fd);
//cout<<v1.size()<<endl;
qsort(v1, 0, v1.size() - 1);
/*vector<int>::const_iterator p = v1.begin();
for(; p != v1.end(); p++){
cout<<*p<<endl;
sleep(1);
}*/
fd = fopen("file2", "r");
if(fd == NULL){
cerr<<"open file2 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
temp = atoi(buf);
if(binarySearch(v1, temp)){
result.push_back(temp);
}
}
cout<<result.size();
return 0;
}
void qsort(vector<int> &v, int low, int hight){
if(low < hight){
int mid = partition(v, low, hight);
qsort(v, low, mid - 1);
qsort(v, mid + 1, hight);
}
}
int partition(vector<int> &v, int min, int max){
int temp = v[min];
while(min < max){
while(min < max && v[max] >= temp)
max--;
v[min] = v[max];
while(min < max && v[min] <= temp)
min++;
v[max] = v[min];
}
v[min] = temp;
return min;
}
bool binarySearch(const vector<int> &v, int key){
int low, hight, mid;
low = 0;
hight = v.size() - 1;
while(low <= hight){
mid = (low + hight) /2;
if(v[mid] == key){
return true;
}else if(v[mid] < key){
low = mid + 1;
}else{
hight = mid - 1;
}
}
return false;
}
正乐着呢,编译运行:
结果发现,user时间是2.194秒,整个时间还要比以前长,显然这种方法还是不行,原因就是两个文件太大了,500万条,不是一般小,且上面花的时间主要用在排序上面去了,于是就想,能不能不用排序完成?这时有个朋友和我说了一下位图法,灵感一来,自己又去改写了代码:
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
#define SHIFT 5
#define MAXLINE 32
#define MASK 0x1F
using namespace std;
// Author: 397090770
// Email: wyphao.2007@163.com
// blog:
// 仅用于学习交流,转载请务必留下这些注释。
void setbit(int *bitmap, int i){
bitmap[i >> SHIFT] |= (1 << (i & MASK));
}
bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
}
size_t getFileSize(ifstream &in, size_t &size){
in.seekg(0, ios::end);
size = in.tellg();
in.seekg(0, ios::beg);
return size;
}
char * fillBuf(const char *filename){
size_t size = 0;
ifstream in(filename);
if(in.fail()){
cerr<< "open " << filename << " failed!" << endl;
exit(1);
}
getFileSize(in, size);
char *buf = (char *)malloc(sizeof(char) * size + 1);
if(buf == NULL){
cerr << "malloc buf error!" << endl;
exit(1);
}
in.read(buf, size);
in.close();
buf[size] = '\0';
return buf;
}
void setBitMask(const char *filename, int *bit){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
//cout<<p<<endl;
setbit(bit, atoi(p));
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
void compareBit(const char *filename, int *bit, vector<int> &result){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
if(getbit(bit, atoi(p))){
result.push_back(atoi(p));
}
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
int main(){
vector<int> result;
unsigned int MAX = (unsigned int)(1 << 31);
unsigned int size = MAX >> 5;
int *bit1;
bit1 = (int *)malloc(sizeof(int) * (size + 1));
if(bit1 == NULL){
cerr<<"Malloc bit1 error!"<<endl;
exit(1);
}
memset(bit1, 0, size + 1);
setBitMask("file1", bit1);
compareBit("file2", bit1, result);
delete bit1;
cout<<result.size();
sort(result.begin(), result.end());
vector< int >::iterator it = unique(result.begin(), result.end());
ofstream of("result");
ostream_iterator<int> output(of, "\n");
copy(result.begin(), it, output);
return 0;
}
这是利用位图法实现的程序,编译运行
运行时间明显比前两个少,但是这个程序是以空间换取时间,程序运行的时候分配了几百兆的空间。可见在程序设计中,方法很重要。什么情况选用什么方法。但是还是觉得前面两个方法还行,因为需要的空间比较少。
(转载请注明:/archives/158,请不要用于商业目的。)
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【迅速在两个含有大量数据的文件中寻找相同的数据】(https://www.iteblog.com/archives/158.html)






I read your ponitsg and was jealous