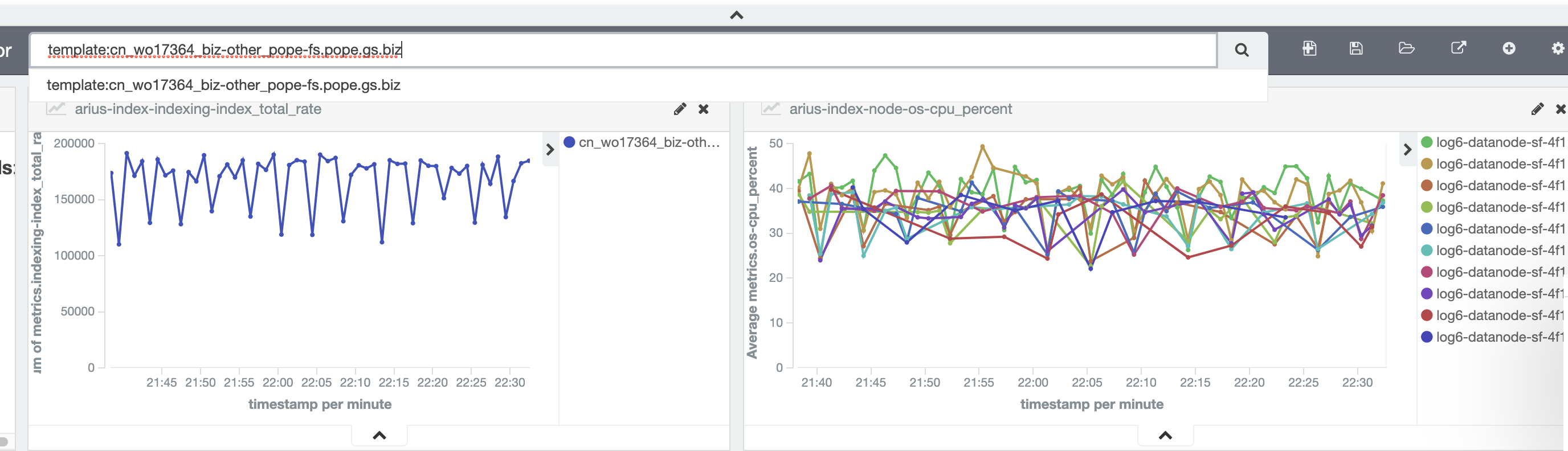
使用 ElasticSearch 我们可以构建一个功能完备的搜索服务器。这一切实现起来都很简单,本文将花五分钟向你介绍如何实现。
安装和运行Elasticsearch
这篇文章的操作环境是 Linux 或者 Mac,在安装 ElasticSearch 之前,确保你的系统上已经安装好 JDK 6 或者以上版本。
wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.tar.gz tar -zxvf elasticsearch-1.7.2.tar.gz cd elasticsearch-1.7.2 bin/elasticsearch
然后你将在终端看到如下输出:
[2015-09-14 15:32:52,278][INFO ][node ] [Big Man] version[1.7.2], pid[10907], build[e43676b/2015-09-14T09:49:53Z]
[2015-09-14 15:32:52,279][INFO ][node ] [Big Man] initializing ...
[2015-09-14 15:32:52,376][INFO ][plugins ] [Big Man] loaded [], sites []
[2015-09-14 15:32:52,426][INFO ][env ] [Big Man] using [1] data paths, mounts [[/ (/dev/sdc1)]], net usable_space [8.7gb], net total_space [219.9gb], types [ext3]
Java HotSpot(TM) Server VM warning: You have loaded library /tmp/es/elasticsearch-1.7.2/lib/sigar/libsigar-x86-linux.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
[2015-09-14 15:32:55,294][INFO ][node ] [Big Man] initialized
[2015-09-14 15:32:55,294][INFO ][node ] [Big Man] starting ...
[2015-09-14 15:32:55,411][INFO ][transport ] [Big Man] bound_address {inet[/0:0:0:0:0:0:0:0:9300]}, publish_address {inet[/192.168.43.172:9300]}
[2015-09-14 15:32:55,428][INFO ][discovery ] [Big Man] elasticsearch/VKL1HQmyT_KRtmTGznmQyg
[2015-09-14 15:32:59,210][INFO ][cluster.service ] [Big Man] new_master [Big Man][VKL1HQmyT_KRtmTGznmQyg][Happy][inet[/192.168.43.172:9300]], reason: zen-disco-join (elected_as_master)
[2015-09-14 15:32:59,239][INFO ][http ] [Big Man] bound_address {inet[/0:0:0:0:0:0:0:0:9200]}, publish_address {inet[/192.168.43.172:9200]}
[2015-09-14 15:32:59,239][INFO ][node ] [Big Man] started
[2015-09-14 15:32:59,284][INFO ][gateway ] [Big Man] recovered [0] indices into cluster_state
现在你的系统上成功运行了 Elasticsearch !你可以在浏览器里面访问 http://localhost:9200 ,这时候浏览器里面会返回以下内容:
{
"status" : 200,
"name" : "Big Man",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.2",
"build_hash" : "e43676b1385b8125d647f593f7202acbd816e8ec",
"build_timestamp" : "2015-09-14T09:49:53Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
索引数据
现在我们往 ElasticSearch 里面构建一些数据,我们假设有一个博客系统,里面有一些文章和评论相关的数据,现在将这些信息添加到 ElasticSearch 里面:
curl -XPUT 'http://localhost:9200/blog/user/dilbert' -d '{ "name" : "Dilbert Brown" }'
curl -XPUT 'http://localhost:9200/blog/post/1' -d '
{
"user": "dilbert",
"postDate": "2011-12-15",
"body": "Search is hard. Search should be easy." ,
"title": "On search"
}'
curl -XPUT 'http://localhost:9200/blog/post/2' -d '
{
"user": "dilbert",
"postDate": "2011-12-12",
"body": "Distribution is hard. Distribution should be easy." ,
"title": "On distributed search"
}'
curl -XPUT 'http://localhost:9200/blog/post/3' -d '
{
"user": "dilbert",
"postDate": "2011-12-10",
"body": "Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat" ,
"title": "Lorem ipsum"
}'
上面的每一步请求,你都会接受到一个响应,里面会证明你的请求成功,如下:
{"ok":true,"_index":"blog","_type":"post","_id":"1","_version":1}
现在我们来看看上面的请求是否正的成功了:
curl -XGET 'http://localhost:9200/blog/user/dilbert?pretty=true' curl -XGET 'http://localhost:9200/blog/post/1?pretty=true' curl -XGET 'http://localhost:9200/blog/post/2?pretty=true' curl -XGET 'http://localhost:9200/blog/post/3?pretty=true'
注意:往 ElasticSearch 里面添加数据主要有两种方式:
- 通过HTTP发送Json数据;
- 内置提供的客户端(Native client)。
搜索
我们来看看我们是否可以检索我们刚刚通过搜索添加的文档,下面的例子是找出所有 Dilbert 作者的文章:
curl 'http://localhost:9200/blog/post/_search?q=user:dilbert&pretty=true'
上面的请求将会返回以下的Json结果:
{
"took": 85,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "blog",
"_type": "post",
"_id": "1",
"_score": 1,
"_source": {
"user": "dilbert",
"postDate": "2011-12-15",
"body": "Search is hard. Search should be easy.",
"title": "On search"
}
},
{
"_index": "blog",
"_type": "post",
"_id": "2",
"_score": 0.30685282,
"_source": {
"user": "dilbert",
"postDate": "2011-12-12",
"body": "Distribution is hard. Distribution should be easy.",
"title": "On distributed search"
}
},
{
"_index": "blog",
"_type": "post",
"_id": "3",
"_score": 0.30685282,
"_source": {
"user": "dilbert",
"postDate": "2011-12-10",
"body": "Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat",
"title": "Lorem ipsum"
}
}
]
}
}
下面例子搜索标题不含 search 的文章
curl 'http://localhost:9200/blog/post/_search?q=-title:search&pretty=true'
下面例子搜索标题包含 search 但是不包含 distributed 的文章:
curl 'http://localhost:9200/blog/post/_search?q=+title:search%20-title:distributed&pretty=true&fields=title'
下面例子通过 postDate 字段搜索一定时间范围内的文章:
curl -XGET 'http://localhost:9200/blog/_search?pretty=true' -d '
{
"query" : {
"range" : {
"postDate" : { "from" : "2011-12-10", "to" : "2011-12-12" }
}
}
}'
好了,现在我们已经学习了 ElasticSearch 的一些基本的使用情况。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【五分钟了解Elasticsearch】(https://www.iteblog.com/archives/1859.html)