

Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。
Apache Hivemall提供了各种功能包括:回归(regression)、分类(classification)、推荐(recommendation)异常检测(anomaly detection)、k-最近邻(k-nearest neighbor)以及特征工程(feature engineering)。同时它还支持最先进的机器学习算法,如软信度加权(Soft Confidence Weighted)、权重向量的自适应正则化(Adaptive Regularization of Weight Vectors)、因式分解机(Factorization Machines)和AdaDelta。
为什么要设计Apache Hivemall
我们一般进行ML工作的时候,通常使用Hive预先处理数据,然后使用Python来进行机器学习相关的工作。这些工作非常的不高效并且烦人,最重要的是,Python不能像Hive一样扩展。所以为什么不能直接在Hive上运行ML算法呢?这样我们可以维护更少的组件,而且可以使用MR的扩展性。
目前也存在很多分布式的机器学习框架,比如Mahout、Spark MLlib、H2O、Cloudera Oryx以及Vowpal Wabbit等,但是这些框架使用起来不是很方便,因为这需要我们进行大量的编程。为什么不能直接在SQL中使用机器学习算法呢?基于这些理由,Apache Hivemall诞生了。
Architecture
Apache Hivemall的体系结构设计如下:
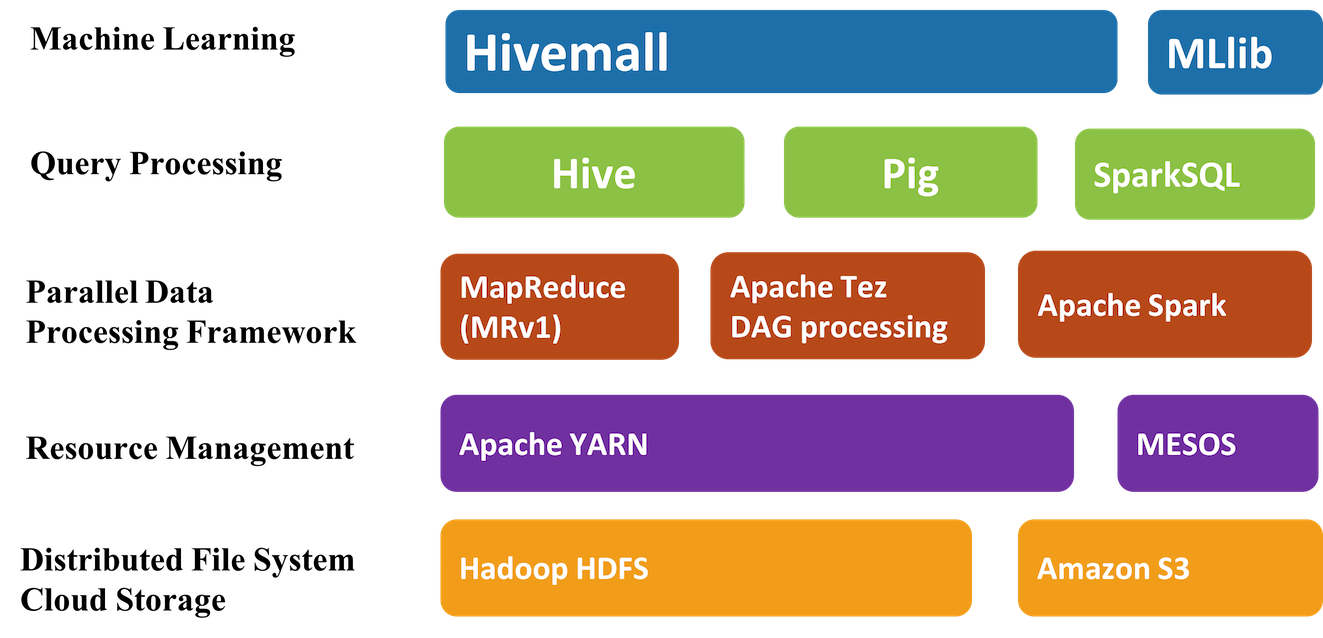
Apache Hivemall 设计主要是运行在Apache Hive之上,但是还支持在Apache Pig 和 Apache Spark 上运行。所以我们也可以把它当做是一个跨平台的机器学习类库。我们可以通过Apache Hive构建预测模型然后在Apache Spark/Pig上使用;反之也是可以的。
如何使用
安装
正如前面所说,Apache Hivemall其实是一些UDF / UDAF / UDTF 集合,所以我们可以把它当做普通的jar包处理即可,我们可以在$HOME/.hiverc文件里面添加下面的配置:
add jar /home/iteblog/hivemall/hivemall-core-xxx-with-dependencies.jar; source /home/iteblog/hivemall/define-all.hive;
然后每当我们启动Hive的时候,都会加载上面的jar包。
一些实例
1、求top N
假如我们有一张名为iteblog的表格数据:
| student | class | score |
|---|---|---|
| 1 | b | 70 |
| 2 | a | 80 |
| 3 | a | 90 |
| 4 | b | 50 |
| 5 | a | 70 |
| 6 | b | 60 |
我们期待计算出每个class中得分最高的2位同学的信息,如果我们使用正常的Hive SQL编写,可以实现如下:
select * from ( select *, rank() over (partition by class order by score desc) as rank from iteblog ) t where rank <= 2
Hivemall为我们提供了 each_top_k UDTF函数,其使用如下:each_top_k(int k, ANY group, double value, arg1, arg2, ..., argN),它将返回为每个 group 返回前 k 个记录;所以我们现在使用 each_top_k UDTF函数来实现这个功能:
select each_top_k(2, classs, score, class, student) as (rank, score, class, student) from ( select * from iteblog distribute by class sort by class )t
each_top_k 函数相比 rank 更加高效,特别是在数据量非常大的时候,其时间复杂度为O(nm)。更多关于each_top_k 函数的使用请参见 https://github.com/myui/hivemall/wiki/Efficient-Top-k-computation-on-Apache-Hive-using-Hivemall-UDTF。
2、最大最小值
可以直接使用min、max:
select min(target), max(target) from iteblog
3、平均值
select avg(target) from iteblog
更多关于Apache Hivemall的使用请参见 http://hivemall.incubator.apache.org/userguide/。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Apache Hivemall:可运行在Hive, Spark 和 Pig 上的可扩展机器学习库】(https://www.iteblog.com/archives/2088.html)







还不错,顶一个