

文章目录
越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
Apache Flink 非常适用于流分析应用程序,因为它支持事件时间语义,确保只处理一次,以及同时实现了高吞吐量和低延迟。因为这些特性,Flink 能够近实时对大量的输入数据计算出一个确定和精确的结果,并且在发生故障的时候提供一次性语义。
Flink 的核心流处理 API,DataStream API,非常具有表现力,并且为许多常见操作提供了原语。在其他特性中,它提供了高度可定制的窗口逻辑,不同表现特征下的不同状态原语,注册和响应定时器的钩子,以及高效的异步请求外部系统的工具。另一方面,许多流分析应用遵循相似的模式,并不需要 DataStream API 提供的表现力级别。他们可以使用领域特定的语言来使用更自然和简洁的方式表达。众所周知,SQL 是数据分析的事实标准。对于流分析,SQL 可以让更多的人在数据流的特定应用中花费更少的时间。然而,目前还没有开源的流处理器提供令人满意的 SQL 支持。
为什么流中的 SQL 很重要
SQL 是数据分析使用最广泛的语言,有很多原因:
- SQL 是声明式的:你指定你想要的东西,而不是如何去计算;
- SQL 可以进行有效的优化:优化器计估算有效的计划来计算结果;
- SQL 可以进行有效的评估:处理引擎准确的知道计算内容,以及如何有效的执行;
- 最后,所有人都知道的,许多工具都理解 SQL。
因此,使用 SQL 处理和分析数据流,可以为更多人提供流处理技术。此外,因为 SQL 的声明性质和潜在的自动优化,它可以大大减少定义高效流分析应用的时间和精力。
但是,SQL(以及关系数据模型和代数)并不是为流数据设计的。关系是(多)集合而不是无限序列的元组。当执行 SQL 查询时,传统数据库系统和查询引擎读取和处理完整的可用数据集,并产生固定大小的结果。相比之下,数据流持续提供新的记录,使数据随着时间到达。因此,流查询需要不断的处理到达的数据,从来都不是“完整的”。
话虽如此,使用 SQL 处理流并不是不可能的。一些关系型数据库系统维护了物化视图,类似于在流数据中评估 SQL 查询。物化视图被定义为一个 SQL 查询,就像常规(虚拟)视图一样。但是,查询的结果实际上被保存(或者是物化)在内存或硬盘中,这样视图在查询时不需要实时计算。为了防止物化视图的数据过时,数据库系统需要在其基础关系(定义的 SQL 查询引用的表)被修改时更新更新视图。如果我们将视图的基础关系修改视作修改流(或者是更改日志流),物化视图的维护和流中的 SQL 的关系就变得很明确了。
Flink 的关系 API:Table API 和 SQL
从 1.1.0 版本(2016 年 8 月发布)以来,Flink 提供了两个语义相当的关系 API,语言内嵌的 Table API(用于 Java 和 Scala)以及标准 SQL。这两种 API 被设计用于在线流和遗留的批处理数据 API 的统一,这意味着无论输入是静态批处理数据还是流数据,查询产生完全相同的结果。
统一流和批处理的 API 非常重要。首先,用户只需要学习一个 API 来处理静态和流数据。此外,可以使用同样的查询来分析批处理和流数据,这样可以在同一个查询里面同时分析历史和在线数据。在目前的状况下,我们尚未完全实现批处理和流式语义的统一,但社区在这个目标上取得了很大的进展。
下面的代码片段展示了两个等效的 Table API 和 SQL 查询,用来在温度传感器测量数据流中计算一个简单的窗口聚合。SQL 查询的语法基于 Apache Calcite 的分组窗口函数样式,并将在 Flink 1.3.0 版本中得到支持。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tEnv = TableEnvironment.getTableEnvironment(env)
// define a table source to read sensor data (sensorId, time, room, temp)
val sensorTable = ??? // can be a CSV file, Kafka topic, database, or ...
// register the table source
tEnv.registerTableSource("sensors", sensorTable)
// Table API
val tapiResult: Table = tEnv.scan("sensors") // scan sensors table
.window(Tumble over 1.hour on 'rowtime as 'w) // define 1-hour window
.groupBy('w, 'room) // group by window and room
.select('room, 'w.end, 'temp.avg as 'avgTemp) // compute average temperature
// SQL
val sqlResult: Table = tEnv.sql("""
|SELECT room, TUMBLE_END(rowtime, INTERVAL '1' HOUR), AVG(temp) AS avgTemp
|FROM sensors
|GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), room
|""".stripMargin)
就像你看到的,两种 API 以及 Flink 主要的的 DataStream 和 DataSet API 是紧密结合的。Table 可以和 DataSet 或 DataStream 相互转换。因此,可以很简单的去扫描一个外部的表,例如数据库或者是 Parquet 文件,使用 Table API 查询做一些预处理,将结果转换为 DataSet,并对其运行 Gelly 图形算法。上述示例中定义的查询也可以通过更改执行环境来处理批量数据。
在内部,两种 API 都被转换成相同的逻辑表示,由 Apache Calcite 进行优化,并被编译成 DataStream 或是 DataSet 程序。实际上,优化和转换程序并不知道查询是通过 Table API 还是 SQL 来定义的。如果你对优化过程的细节感兴趣,可以看看我们去年发布的一篇博客文章。由于 Table API 和 SQL 在语义方面等同,只是在样式上有些区别,在这篇文章中当我们谈论 SQL 时我们通常引用这两种 API。
在当前的 1.2.0 版本中,Flink 的关系 API 在数据流中,支持有限的关系操作,包括投影、过滤和窗口聚合。所有支持的操作有一个共同点,就是它们永远不会更新已经产生的结果记录。这对于时间记录操作,例如投影和过滤显然不是问题。但是,它会影响收集和处理多条记录的操作,例如窗口聚合。由于产生的结果不能被更新,在 Flink 1.2.0 中,输入的记录在产生结果之后不得不被丢弃。
当前版本的限制对于将产生的数据发往 Kafka 主题、消息队列或者是文件这些存储系统的应用是可以被接受的,因为它们只支持追加操作,没有更新和删除。遵循这种模式的常见用例是持续的 ETL 和流存档应用,将流进行持久化存档,或者是准备数据用于进一步的在线(流)或者是离线分析。由于不可能更新之前产生的结果,这一类应用必须确保产生的结果是正确的,并且将来不需要更正。下图说明了这样的应用。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
虽然只支持追加查询对有些类型的应用和存储系统有用,但是还是有一些流分析的用例需要更新结果。这些流应用包括不能丢弃延迟到达的记录,需要早期的结果用于(长期运行)窗口聚合,或者是需要非窗口的聚合。在每种情况下,之前产生的结果记录都需要被更新。结果更新查询通常将其结果保存在外部数据库或者是键值存储,使其可以让外部应用访问或者是查询。实现这种模式的应用有仪表板、报告应用或者是其他的应用,它们需要及时的访问持续更新的结果。下图说明了这一类应用。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
动态表的持续查询
支持查询更新之前产生的结果是 Flink 的关系 API 的下一个重要步骤。这个功能非常重要,因为它大大增加了 API 支持的用例的范围和种类。此外,一些新的用例可以采用 DataStream API 来实现。
因此,当添加对结果更新查询的支持时,我们必须保留之前的流和批处理输入的语义。我们通过动态表的概念来实现。动态表是持续更新,并且能够像常规的静态表一样查询的表。但是,与批处理表查询终止后返回一个静态表作为结果不同的是,动态表中的查询会持续运行,并根据输入表的修改产生一个持续更新的表。因此,结果表也是动态的。这个概念非常类似我们之前讨论的物化视图的维护。
假设我们可以在动态表中运行查询并产生一个新的动态表,那会带来一个问题,流和动态表如何相互关联?答案是流和动态表可以相互转换。下图展示了在流中处理关系查询的概念模型。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
首先,流被转换为动态表,动态表使用一个持续查询进行查询,产生一个新的动态表。最后,结果表被转换成流。要注意,这个只是逻辑模型,并不意味着查询是如何实际执行的。实际上,持续查询在内部被转换成传统的 DataStream 程序。
随后,我们描述了这个模型的不同步骤:
- 在流中定义动态表
- 查询动态表
- 生成动态表
在流中定义动态表
评估动态表上的 SQL 查询的第一步是在流中定义一个动态表。这意味着我们必须指定流中的记录如何修改动态表。流携带的记录必须具有映射到表的关系模式的模式。在流中定义动态表有两种模式:附加模式和更新模式。
在附加模式中,流中的每条记录是对动态表的插入修改。因此,流中的所有记录都附加到动态表中,使得它的大小不断增长并且无限大。下图说明了附加模式。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
在更新模式中,流中的记录可以作为动态表的插入、更新或者删除修改(附加模式实际上是一种特殊的更新模式)。当在流中通过更新模式定义一个动态表时,我们可以在表中指定一个唯一的键属性。在这种情况下,更新和删除操作会带着键属性一起执行。更新模式如下图所示。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
查询动态表
一旦我们定义了动态表,我们可以在上面运行查询。由于动态表随着时间进行改变,我们必须定义查询动态表的意义。假定我们有一个特定时间的动态表的快照,这个快照可以作为一个标准的静态批处理表。我们将动态表 A 在点 t 的快照表示为 A[t],可以使用人意的 SQL 查询来查询快照,该查询产生了一个标准的静态表作为结果,我们把在时间 t 对动态表 A 做的查询 q 的结果表示为 q(A[t])。如果我们反复在动态表的快照上计算查询结果,以获取进度时间点,我们将获得许多静态结果表,它们随着时间的推移而改变,并且有效的构成一个动态表。我们在动态表的查询中定义如下语义。
查询 q 在动态表 A 上产生了一个动态表 R,它在每个时间点 t 等价于在 A[t] 上执行 q 的结果,即 R[t]=q(A[t])。该定义意味着在批处理表和流表上执行相同的查询 q 会产生相同的结果。在下面的例子中,我们给出了两个例子来说明动态表查询的语义。
在下图中,我们看到左侧的动态输入表 A,定义成追加模式。在时间 t=8 时,A 由 6 行(标记成蓝色)组成。在时间 t=9 和 t=12 时,有一行追加到 A(分别用绿色和橙色标记)。我们在表 A 上运行一个如图中间所示的简单查询,这个查询根据属性 k 分组,并统计每组的记录数。在右侧我们看到了 t=8(蓝色),t=9(绿色)和 t=12(橙色)时查询 q 的结果。在每个时间点 t,结果表等价于在时间 t 时再动态表 A 上执行批查询。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
这个例子中的查询是一个简单的分组(但是没有窗口)聚合查询。因此,结果表的大小依赖于输入表的分组键的数量。此外,值得注意的是,这个查询会持续更新之前产生的结果行,而不只是添加新行。
第二个例子展示了一个类似的查询,但是有一个很重要的差异。除了对属性 k 分组以外,查询还将记录每 5 秒钟分组为一个滚动窗口,这意味着它每 5 秒钟计算一次 k 的总数。再一次的,我们使用 Calcite 的分组窗口函数来指定这个查询。在图的左侧,我们看到输入表 A ,以及它在附加模式下随着时间而改变。在右侧,我们看到结果表,以及它随着时间演变。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
与第一个例子的结果不同的是,这个结果表随着时间增长,例如每 5 秒钟计算出新的结果行(考虑到输入表在过去 5 秒收到更多的记录)。虽然非窗口查询(主要是)更新结果表的行,但是窗口聚合查询只追加新行到结果表中。
虽然这篇博客专注于动态表的 SQL 查询的语义,而不是如何有效的处理这样的查询,但是我们要指出的是,无论输入表什么时候更新,都不可能计算查询的完整结果。相反,查询编译成流应用,根据输入的变化持续更新它的结果。这意味着不是所有的有效 SQL 都支持,只有那些持续性的、递增的和高效计算的被支持。我们计划在后续的博客文章中讨论关于评估动态表的 SQL 查询的详细内容。
生成动态表
查询动态表生成的动态表,其相当于查询结果。根据查询和它的输入表,结果表会通过插入、更新和删除持续更改,就像普通的数据表一样。它可能是一个不断被更新的单行表,一个只插入不更新的表,或者介于两者之间。
传统的数据库系统在故障和复制的时候,通过日志重建表。有一些不同的日志技术,比如 UNDO、REDO 和 UNDO/REDO 日志。简而言之,UNDO 日志记录被修改元素之前的值来回滚不完整的事务,REDO 日志记录元素修改的新值来重做已完成事务丢失的改变,UNDO/REDO 日志同时记录了被修改元素的旧值和新值来撤销未完成的事务,并重做已完成事务丢失的改变。基于这些日志技术的原理,动态表可以转换成两类更改日志流:REDO 流和 REDO+UNDO 流。
通过将表中的修改转换为流消息,动态表被转换为 redo+undo 流。插入修改生成一条新行的插入消息,删除修改生成一条旧行的删除消息,更新修改生成一条旧行的删除消息以及一条新行的插入消息。行为如下图所示。
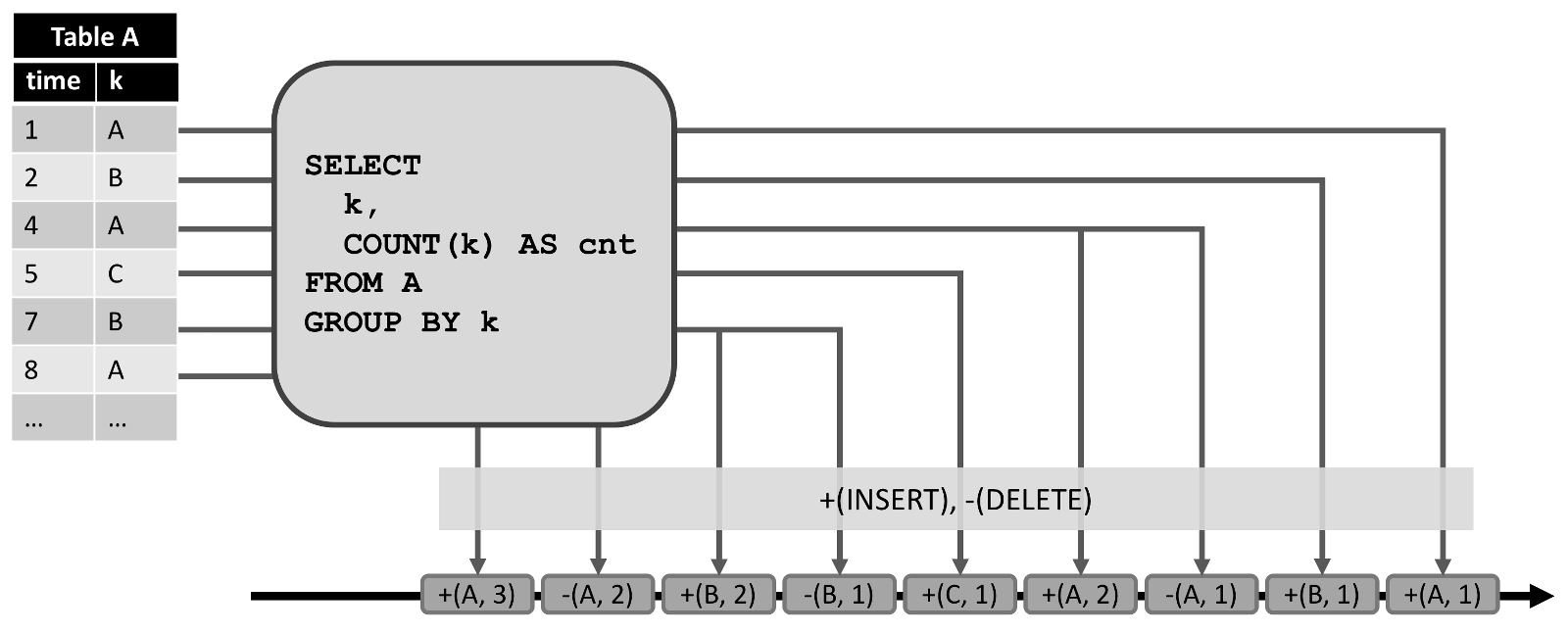
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
左侧显示了一个维护在附加模式下的动态表,作为中间查询的输入。查询的结果转换为显示在底部的 redo+undo 流。输入表的第一条记录 (1,A) 作为结果表的一条新纪录,因此插入了一条消息 +(A,1) 到流中。第二条输入记录 k=‘A’(4,A) 导致了结果表中 (A,1) 记录的更新,从而产生了一条删除消息 -(A,1) 和一条插入消息 +(A,2)。所有的下游操作或数据汇总都需要能够正确处理这两种类型的消息。
在两种情况下,动态表会转换成 redo 流:要么它只是一个附加表(即只有插入修改),要么它有一个唯一的键属性。动态表上的每一个插入修改会产生一条新行的插入消息到 redo 流。由于 redo 流的限制,只有带有唯一键的表能够进行更新和删除修改。如果一个键从动态表中删除,要么是因为行被删除,要么是因为行的键属性值被修改了,所以一条带有被移除键的删除消息发送到 redo 流。更新修改生成带有更新的更新消息,比如新行。由于删除和更新修改根据唯一键来定义,下游操作需要能够根据键来访问之前的值。下图展示了如何将上述相同查询的结果表转换为 redo 流。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
插入到动态表的 (1,A) 产生了 +(A,1) 插入消息。产生更新的 (4,A) 生成了 *(A,2) 的更新消息。
Redo 流的通常做法是将查询结果写到仅附加的存储系统,比如滚动文件或者 Kafka 主题,或者是基于键访问的数据存储,比如 Cassandra、关系型 DBMS 以及压缩的 Kafka 主题。还可以实现将动态表作为流应用的关键的内嵌部分,来评价持续查询和对外部系统的查询能力,例如一个仪表盘应用。
切换到动态表发生的改变
在 1.2 版本中,Flink 关系 API 的所有流操作,例如过滤和分组窗口聚合,只会产生新行,并且不能更新先前发布的结果。 相比之下,动态表能够处理更新和删除修改。 现在你可能会问自己,当前版本的处理模式如何与新的动态表模型相关? API 的语义会完全改变,我们需要从头开始重新实现 API,以达到所需的语义?
所有这些问题的答案很简单。当前的处理模型是动态表模型的一个子集。 使用我们在这篇文章中介绍的术语,当前的模型通过附加模式将流转换为动态表,即一个无限增长的表。 由于所有操作仅接受插入更改并在其结果表上生成插入更改(即,产生新行),因此所有在动态附加表上已经支持的查询,将使用重做模型转换回 DataStreams,仅用于附加表。 因此,当前模型的语义被新的动态表模型完全覆盖和保留。
结论与展望
Flink 的关系 API 在任何时候都非常适合用于流分析应用,并在不同的生产环境中使用。在这篇博文中,我们讨论了 Table API 和 SQL 的未来。 这一努力将使 Flink 和流处理更易于访问。 此外,用于查询历史和实时数据的统一语义以及查询和维护动态表的概念,将能够显着简化许多令人兴奋的用例和应用程序的实现。 由于这篇文章专注于流和动态表的关系查询的语义,我们没有讨论查询执行的细节,包括内部执行撤销,处理后期事件,支持结果预览,以及边界空间要求。 我们计划在稍后的时间点发布有关此主题的后续博客文章。
近几个月来,Flink 社区的许多成员一直在讨论和贡献关系 API。 到目前为止,我们取得了很大的进步。 虽然大多数工作都专注于以附加模式处理流,但是日程上的下一步是处理动态表以支持更新其结果的查询。 如果您对使用 SQL 处理流程的想法感到兴奋,并希望为此做出贡献,请提供反馈,加入邮件列表中的讨论或获取 JIRA 问题。
本文转载自:在数据流中使用SQL查询:Apache Flink中的动态表的持续查询
英文原文:Continuous Queries on Dynamic Tables
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Flink动态表的连续查询(Continuous Queries on Dynamic Tables)】(https://www.iteblog.com/archives/2204.html)





