

Hive 除了为我们提供一个 CLI 方式来查询数据之外,还给我们提供了基于 JDBC/ODBC 的方式来连接 Hive,这就是 HiveServer2(HiveServer)。但是默认情况下通过 JDBC 连接 HiveServer2 不需要任何的权限认证(hive.server2.authentication = NONE);这意味着任何知道 ThriftServer 地址的人都可以连接我们的 Hive,并执行一些操作。更可怕的是,这些人甚至可以执行一些诸如 drop table xxx 之类的操作,这势必威胁到我们的数据安全。基于此,本文介绍如何通过自定义的方式来对连接 ThriftServer 的人进行有效的权限验证。
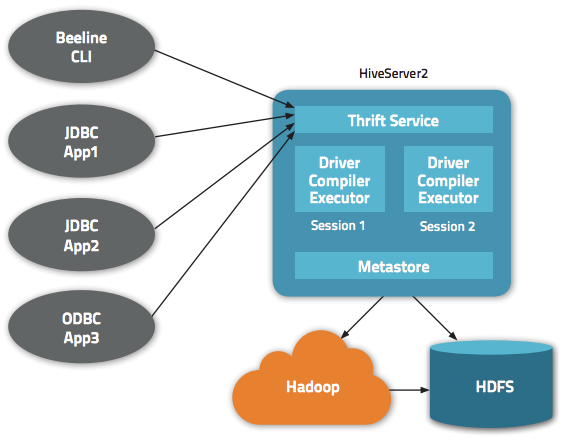
HiveServer2 支持多种用户安全认证方式:NONE, NOSASL, KERBEROS, LDAP, PAM ,CUSTOM 等等。我们可以通过 hive.server2.authentication 参数进行配置。这篇文章我们涉及到的配置是 hive.server2.authentication=CUSTOM,这时候我们需要通过 hive.server2.custom.authentication.class 参数配置我们自定义的权限认证类,这个类必须实现 org.apache.hive.service.auth.PasswdAuthenticationProvider 接口,org.apache.hive.service.auth.PasswdAuthenticationProvider 接口的定义如下:
package org.apache.hive.service.auth;
import javax.security.sasl.AuthenticationException;
public interface PasswdAuthenticationProvider {
/**
* The Authenticate method is called by the HiveServer2 authentication layer
* to authenticate users for their requests.
* If a user is to be granted, return nothing/throw nothing.
* When a user is to be disallowed, throw an appropriate {@link AuthenticationException}.
* <p/>
* For an example implementation, see {@link LdapAuthenticationProviderImpl}.
*
* @param user The username received over the connection request
* @param password The password received over the connection request
*
* @throws AuthenticationException When a user is found to be
* invalid by the implementation
*/
void Authenticate(String user, String password) throws AuthenticationException;
}
从上可知,我们需要实现 Authenticate 方法(为啥这个方法第一个字母大写?不应该是 authenticate 吗?)。现在我们来定义一个自己的授权认证类 IteblogPasswdAuthenticationProvider。为了简便,我把用户名和密码等数据写到了文件中;你要是愿意,你可以将这些信息存储到数据库中。实现代码非常简单,如下:
package com.iteblog.hive;
import com.google.common.base.Charsets;
import com.google.common.collect.Maps;
import com.google.common.io.Files;
import com.google.common.io.LineProcessor;
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hive.service.auth.PasswdAuthenticationProvider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.security.sasl.AuthenticationException;
import java.io.File;
import java.io.IOException;
import java.util.Map;
public class IteblogPasswdAuthenticationProvider implements PasswdAuthenticationProvider {
private static Logger logger = LoggerFactory.getLogger("IteblogPasswdAuthenticationProvider");
private static Map<String, String> lines = null;
static {
HiveConf hiveConf = new HiveConf();
String filePath = hiveConf.get("hive.server2.custom.authentication.passwd.filepath");
logger.warn("Start init configuration file: {}.", filePath);
try {
File file = new File(filePath);
lines = Files.readLines(file, Charsets.UTF_8, new LineProcessor<Map<String, String>>() {
Map<String, String> map = Maps.newHashMap();
public boolean processLine(String line) {
String arr[] = line.split(",");
if (arr.length != 2) {
logger.error("Configuration error: {}", line);
return false;
}
map.put(arr[0], arr[1]);
return true;
}
public Map<String, String> getResult() {
return map;
}
});
} catch (IOException e) {
logger.error("Read configuration file error: {}", e.getMessage());
System.exit(127);
}
}
public void Authenticate(String username, String password) throws AuthenticationException {
if (lines == null) {
throw new AuthenticationException("Configuration file parser error!");
}
String passwd = lines.get(username);
if (passwd == null) {
throw new AuthenticationException("Unauthorized user: " + username + ", please contact iteblog to add an account.");
} else if (!passwd.equals(password)) {
throw new AuthenticationException("Incorrect password for " + username + ", please try again.");
}
logger.warn("User[{}] authorized success.", username);
}
}
上面的代码逻辑非常简单,我就不介绍了。我们把用户名和密码信息写到了 /home/iteblog/hive-thrift-passwd 文件中,内容日下:
iteblog,123
并通过参数 hive.server2.custom.authentication.passwd.filepath 参数指定这个文件的路径。现在我们编译上面的类,得到的 jar 包放到 $HIVE_HOME/lib 路径下面(如果你是用 Spark,那你将这个 jar 包放到 $SPARK_HOME/jars 或 $SPARK_HOME/lib 目录下)。并在 hive-site.xml 文件里面加入以下的配置:
<property> <name>hive.server2.authentication</name> <value>CUSTOM</value> </property> <property> <name>hive.server2.custom.authentication.class</name> <value>com.iteblog.hive.IteblogPasswdAuthenticationProvider</value> </property> <property> <name>hive.server2.custom.authentication.passwd.filepath</name> <value>/home/iteblog/hive-thrift-passwd</value> </property>
重启 thriftServer,现在我们来测试下这个设置是否生效:
beeline> !connect jdbc:hive2://www.iteblog.com:10000 Connecting to jdbc:hive2://www.iteblog.com:10000 Enter username for jdbc:hive2://www.iteblog.com:10000: Enter password for jdbc:hive2://www.iteblog.com:10000: Error: Could not open client transport with JDBC Uri: jdbc:hive2://www.iteblog.com:10000: Peer indicated failure: Error validating the login (state=08S01,code=0) 0: jdbc:hive2://www.iteblog.com:10000 (closed)>
上面测试我们登录的时候没有设置用户名和密码,如果你没有输入用户名系统默认会用 anonymous 用户进行登录,但是我们并没有配置这个用户登录,这时候应该是不能登录的。从上面终端输出也可以看出登录失败,而且日志里面有如下异常输出
18/01/10 16:50:40 WARN IteblogPasswdAuthenticationProvider: Start init configuration file: /home/iteblog/hive-thrift-passwd. 18/01/10 16:50:40 ERROR TSaslTransport: SASL negotiation failure javax.security.sasl.SaslException: Error validating the login [Caused by javax.security.sasl.AuthenticationException: Unauthorized user: anonymous, please contact iteblog to add an account.] at org.apache.hive.service.auth.PlainSaslServer.evaluateResponse(PlainSaslServer.java:109) at org.apache.thrift.transport.TSaslTransport$SaslParticipant.evaluateChallengeOrResponse(TSaslTransport.java:539) at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:283) at org.apache.thrift.transport.TSaslServerTransport.open(TSaslServerTransport.java:41) at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:216) at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:269) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: javax.security.sasl.AuthenticationException: Unauthorized user: anonymous, please contact iteblog to add an account. at com.iteblog.hive.IteblogPasswdAuthenticationProvider.Authenticate(IteblogPasswdAuthenticationProvider.java:58) at org.apache.hive.service.auth.CustomAuthenticationProviderImpl.Authenticate(CustomAuthenticationProviderImpl.java:47) at org.apache.hive.service.auth.PlainSaslHelper$PlainServerCallbackHandler.handle(PlainSaslHelper.java:106) at org.apache.hive.service.auth.PlainSaslServer.evaluateResponse(PlainSaslServer.java:102) ... 8 more
现在我们用正确的用户登录,但是密码是错误的,看下结果:
beeline> !connect jdbc:hive2://www.iteblog.com:10000 Connecting to jdbc:hive2://www.iteblog.com:10000 Enter username for jdbc:hive2://www.iteblog.com:10000: iteblog Enter password for jdbc:hive2://www.iteblog.com:10000: *** Error: Could not open client transport with JDBC Uri: jdbc:hive2://www.iteblog.com:10000: Peer indicated failure: Error validating the login (state=08S01,code=0)
从上面的结果可以看出,登录同样失败,日志里面也会有以下的异常信息:
18/01/10 16:53:39 ERROR TSaslTransport: SASL negotiation failure javax.security.sasl.SaslException: Error validating the login [Caused by javax.security.sasl.AuthenticationException: Incorrect password for iteblog, please try again.] at org.apache.hive.service.auth.PlainSaslServer.evaluateResponse(PlainSaslServer.java:109) at org.apache.thrift.transport.TSaslTransport$SaslParticipant.evaluateChallengeOrResponse(TSaslTransport.java:539) at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:283) at org.apache.thrift.transport.TSaslServerTransport.open(TSaslServerTransport.java:41) at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:216) at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:269) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: javax.security.sasl.AuthenticationException: Incorrect password for iteblog, please try again. at com.iteblog.hive.IteblogPasswdAuthenticationProvider.Authenticate(IteblogPasswdAuthenticationProvider.java:60) at org.apache.hive.service.auth.CustomAuthenticationProviderImpl.Authenticate(CustomAuthenticationProviderImpl.java:47) at org.apache.hive.service.auth.PlainSaslHelper$PlainServerCallbackHandler.handle(PlainSaslHelper.java:106) at org.apache.hive.service.auth.PlainSaslServer.evaluateResponse(PlainSaslServer.java:102) ... 8 more
最后如果用户名和密码都输入正确,将会成功登录:
beeline> !connect jdbc:hive2://www.iteblog.com:10000 Connecting to jdbc:hive2://www.iteblog.com:10000 Enter username for jdbc:hive2://www.iteblog.com:10000: iteblog Enter password for jdbc:hive2://www.iteblog.com:10000: *** Connected to: Spark SQL (version 2.2.1) Driver: Hive JDBC (version 1.2.1.hive2) Transaction isolation: TRANSACTION_REPEATABLE_READ 1: jdbc:hive2://www.iteblog.com:10000>
并且日志里面有以下的输出:
18/01/10 16:52:00 WARN IteblogPasswdAuthenticationProvider: User[iteblog] authorized success.本博客文章除特别声明,全部都是原创!
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【HiveServer2(Spark ThriftServer)自定义权限认证】(https://www.iteblog.com/archives/2318.html)







大佬,问个问题,spark sql可以使用ranger鉴权吗
你好,这个权限控制能够控制更加细粒度的权限吗?比如库级、表级、行级等
这个不行的,给的接口只能接收用户名和密码。库级、表级、行级这个可以看下 hive.security.authorization.enabled。
您好, 不同不同用户链接上后对数据库的权限是怎么定义的呢?
您好,请问一下这种方式的权限只是限制了thriftserver的连接,而不同用户连接上之后对库和表的权限都是超级用户?是不受hive控制的吗?希望您能在百忙之中抽出时间解答一下。 谢谢!