Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。更多特点请参见 一篇文章了解 Apache Cassandra 是什么。
由于 Cassandra 数据库的众多优点,在国内外多达 1500+ 家公司使用,这里包括 Apple、Constant Contact, CERN, Comcast, eBay, GitHub, GoDaddy, Hulu, Instagram, Intuit, Netflix, Reddit, 以及国内的 360、京东、饿了么、宜搜、三一重工、国家气象局等。其中 Apple 在2018年12月于 DevOpsDays India 会议公布其 Cassandra 集群规模达到 16W+ 个实例,存储超过 100PB 的数据,超过 1000个集群,如下

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在今年的 Qcon 北京2019 大会上,京东的赵玉开在名为《支撑亿级运单的配运平台架构实践》演讲中也显示出京东的运单技术平台的存储中间件使用到 Cassandra。

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop
虽然有这么多公司使用 Cassandra ,但是国内外关于 Cassandra 的资料非常少,而且很旧。为了让大家更好的了解和使用 Cassandra,我们发动了 Cassandra 中国技术社区,并且申请了公众号以及钉钉交流群(如下),社区网站我们在筹备中。后续我们会在钉钉群安排直播,并且也会计划一些线下 Cassandra Meetup,欢迎大家关注下面 Cassandra技术社区公众号以及钉钉群。
Cassandra技术社区微信公众号:

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop
钉钉群

如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop
钉钉群入群链接:https://c.tb.cn/F3.ZRTY0o
我们也在编写 《Cassandra 从入门到精通》专栏(https://yq.aliyun.com/articles/699492),如下:
1、基础篇
1.1 Cassandra简单介绍(已完成)
1.2 为什么选择Cassandra进行大数据管理?(已完成)
1.3 Cassandra quick start(已完成)
1.4 Apache Cassandra Composite KeyPartition keyClustering key 介绍(已完成)
1.5 Apache Cassandra static column 介绍与实战(已完成)
1.6 多语言客户端
1.7 Cassandra 数据类型(已完成)
1.8 Cassandra 配置介绍(已完成)
2、进阶篇
2.1 架构、基本原理、核心技术等
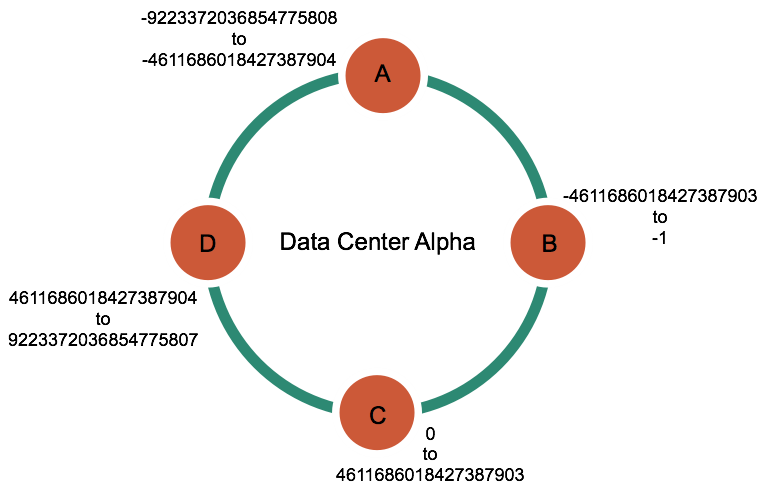
2.1.1 一致性哈希
2.1.2 Gossip
2.1.3 全球容灾
2.1.4 xxxx
2.2 读写io流程
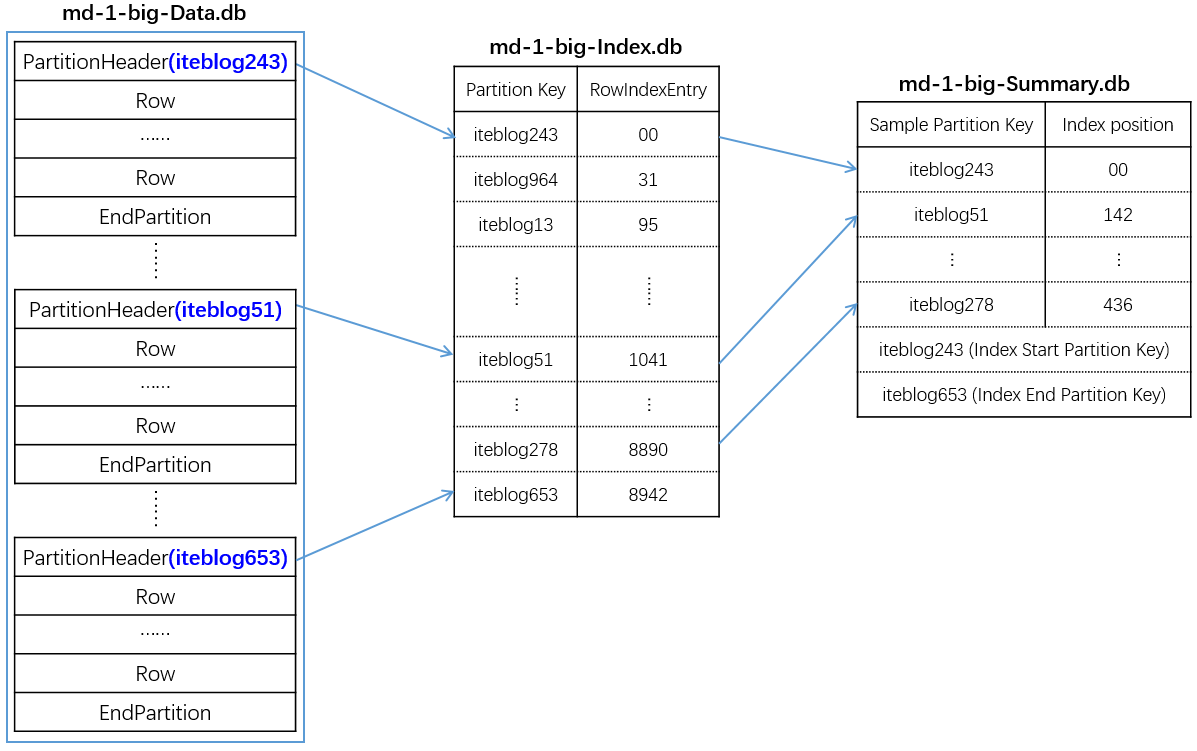
2.3 数据存储模型(已完成)
2.4 数据 Compaction
2.5 数据 Flush 流程
2.6 二级索引 & sasi index & 物化视图
2.7 Cassandra 启动流程
2.8 基本运维指令和原理介绍
3、案例实战
3.1 Cassandra 运维
3.2 Cassandra 监控
3.3 性能调优
3.4 Dynamo 迁移 Cassandra 实战
3.5 Cassandra 业界案例
同时,Cassandra 技术社区也在招募 Cassandra 发展委员,作为委员您将与阿里巴巴、360等诸位产品和技术人员一同共事交流。如果想成为 Cassandra 发展委员,可以加我个人微信 iteblog,备注 Cassandra。
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【欢迎加入中国 Cassandra 技术社区】(https://www.iteblog.com/archives/2553.html)