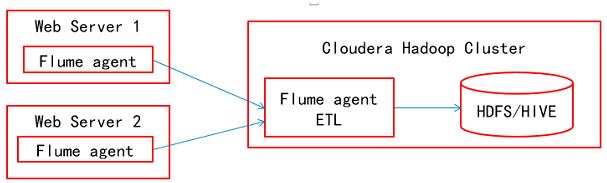
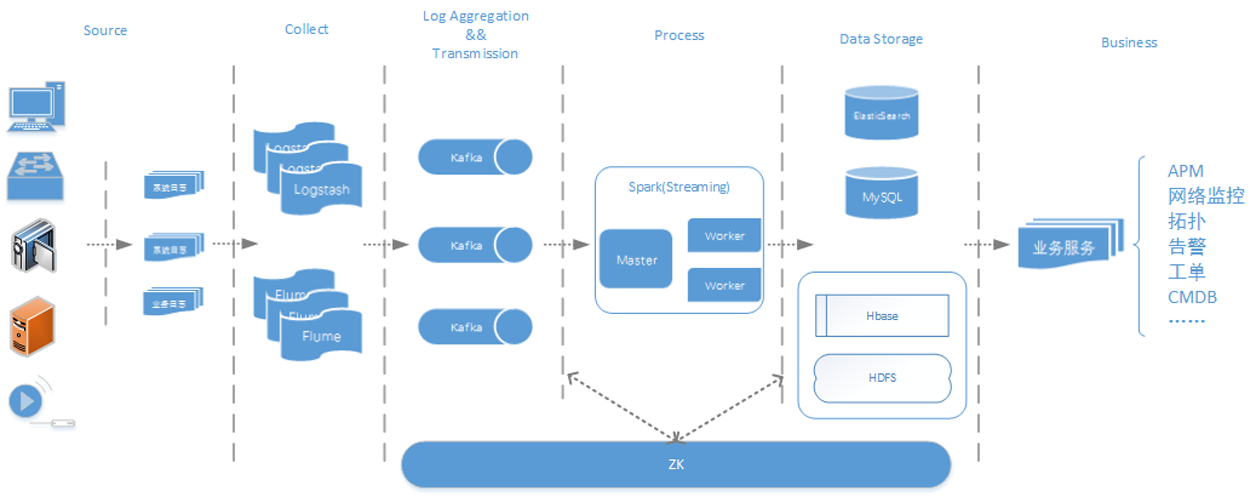
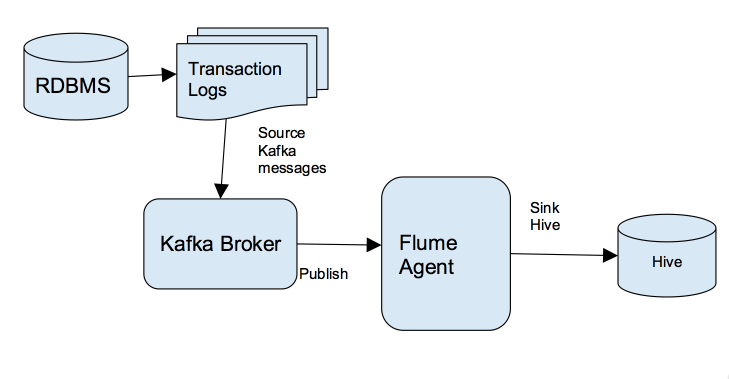
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
Flume主要有以下几类组件:
(1)、Master: 负责配置及通信管理,是集群的控制器,并支持多master节点;
(2)、Agent: 采集数据,Agent是flume中产生数据流的地方,同时Agent会将产生的数据流传输到Collector;
(3)、Collector: 用于对数据进行聚合(数据收集器),往往会产生一个更大的数据流,然后加载到storage(存储)中 。
简单地来说,就是Agent把采集到的数据定时发送给Collector,Collector接收Agent发送的数据并把数据写到指定的位置(比如文本、HDFS、Hbase等)。
这篇文章主要简单介绍如何部署Flume-0.9.4分布式环境,涉及到三台机器。它们的hostname分别为master,agent,collector。
1、到官网下载Flume-0.9.4,并解压:
[wyp@master ~]$ wget https://repository.cloudera.com/content/ \
repositories/releases/com/cloudera/flume-distribution/0.9.4-cdh4.0.0/ \
flume-distribution-0.9.4-cdh4.0.0-bin.tar.gz \
[wyp@master ~]$ tar -zxvf flume-distribution-0.9.4-cdh4.0.0-bin.tar.gz
[wyp@master ~]$ cd flume-0.9.4-cdh3u3
[wyp@master flume-0.9.4-cdh3u3]$
2、进入$FLUME_HOMNE/bin目录,将flume-env.sh.template重命名为flume-env.sh,并在flume-env.sh文件里面设置如下变量:
[wyp@master flume-0.9.4-cdh3u3]$ cd bin [wyp@master bin]$ cp flume-env.sh.template flume-env.sh [wyp@master bin]$ vim flume-env.sh export FLUME_HOME=/home/q/flume-0.9.4-cdh3u3 export FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$PATH:$FLUME_HOME/bin export JAVA_HOME=/usr/lib/jvm/java-6-sun
3、进入$FLUME_HOMNE/conf目录,将flume-site.xml.template重命名为flume-site.xml,并修改flume-site.xml配置文件
[wyp@master bin]$ cd ../conf
[wyp@master conf]$ cp flume-site.xml.template flume-site.xml
[wyp@master conf]$ vim flume-site.xml
<property>
<name>flume.master.servers</name>
<value>master</value>
<description>This is the address for the config servers status
server (http)
</description>
</property>
<property>
<name>flume.collector.output.format</name>
<value>raw</value>
<description>The output format for the data written by a Flume
collector node. There are several formats available:
syslog - outputs events in a syslog-like format
log4j - outputs events in a pattern similar to Hadoop's log4j pattern
raw - Event body only. This is most similar to copying a file but
does not preserve any uniqifying metadata like host/timestamp/nanos.
avro - Avro Native file format. Default currently is uncompressed.
avrojson - this outputs data as json encoded by avro
avrodata - this outputs data as a avro binary encoded data
debug - used only for debugging
</description>
</property>
<property>
<name>flume.collector.roll.millis</name>
<value>300000</value>
<description>The time (in milliseconds)
between when hdfs files are closed and a new file is opened
(rolled).
</description>
</property>
<property>
<name>flume.agent.logdir.maxage</name>
<value>10000</value>
<description> number of milliseconds before a local log file is
considered closed and ready to forward.
</description>
</property>
<property>
<name>flume.agent.logdir.retransmit</name>
<value>60000</value>
<description>The time (in milliseconds) before a sent event is
assumed lost and needs to be retried in end-to-end reliability
mode again. This should be at least 2x the
flume.collector.roll.millis.
</description>
</property>
4、将配置好的Flume整个文件夹打包,并发送到agent和collector的机器上:
[wyp@master ~]$ tar -zcvf flume-0.9.4-cdh3u3.tar.gz flume-0.9.4-cdh3u3 [wyp@master ~]$ scp flume-0.9.4-cdh3u3.tar.gz agent:/home/wyp [wyp@master ~]$ scp flume-0.9.4-cdh3u3.tar.gz collector:/home/wyp
5、分别在agent和collector机器上解压上述包,并在master,agent和collector机器上分别启动以下进程:
[wyp@master ~]$ $FLUME_HOME/bin/flume master [wyp@agent ~]$ $FLUME_HOME/bin/flume node_nowatch –n agent [wyp@collector ~]$ $FLUME_HOME/bin/flume node_nowatch –n collector
这样master机器就充当master角色;agent 机器充当agent角色;collector机器充当collector角色。
6、打开http://master:35871,看看能否进去,并看到agent和collector进程成功启动,则说明Flume安装完成!
在接下来的文章我将介绍如何使用Hbase sink的配置,欢迎关注。
原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【Flume-0.9.4分布式安装与配置手册】(https://www.iteblog.com/archives/911.html)