

在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。
数砖研发 Delta Engine 的目的
过去十年,存储的速度从 50MB/s(HDD)提升到 16GB/s(NvMe);网络的速度从 1Gbps 提升到 100Gbps;但是 CPU 的主频从 2010 年的 3GHz 到现在基本不变。

历史上,大多数 SSD 使用如 SATA、SAS 或光纤通道等接口与计算机接口的总线连接。随着固态硬盘在大众市场上的流行,SATA 已成为个人电脑中连接 SSD 的最典型方式;但是,SATA 的设计主要是作为机械硬盘驱动器(HDD)的接口,并随着时间的推移越来越难满足速度日益提高的 SSD。随着在大众市场的流行,许多固态硬盘的数据速率提升已经放缓。不同于机械硬盘,部分 SSD 已受到 SATA 最大吞吐量的限制。
在 NVMe 出现之前,高端 SSD 只得以采用 PCI Express 总线制造,但需使用非标准规范的接口。若使用标准化的 SSD 接口,操作系统只需要一个驱动程序就能使用符合规范的所有 SSD。这也意味着每个 SSD 制造商不必用额外的资源来设计特定接口的驱动程序。
摘抄自 https://zh.wikipedia.org/zh-hans/NVM_Express
从上图可以看出,CPU 主频是目前数据分析的重要瓶颈。
另外,随着业务速度的加快,数据团队用于正确建模数据的时间越来越少。为了更好的业务敏捷性而进行的较差的建模会导致较差的查询性能。比如
- 大多数列没有定义 "NOT NULL";
- String 时候起来很方便,所以很多人使用 String 来存储日期;
- 数据越来越不规范,而且数据还在不断的持续生成。
Delta Engine:高性能的查询引擎
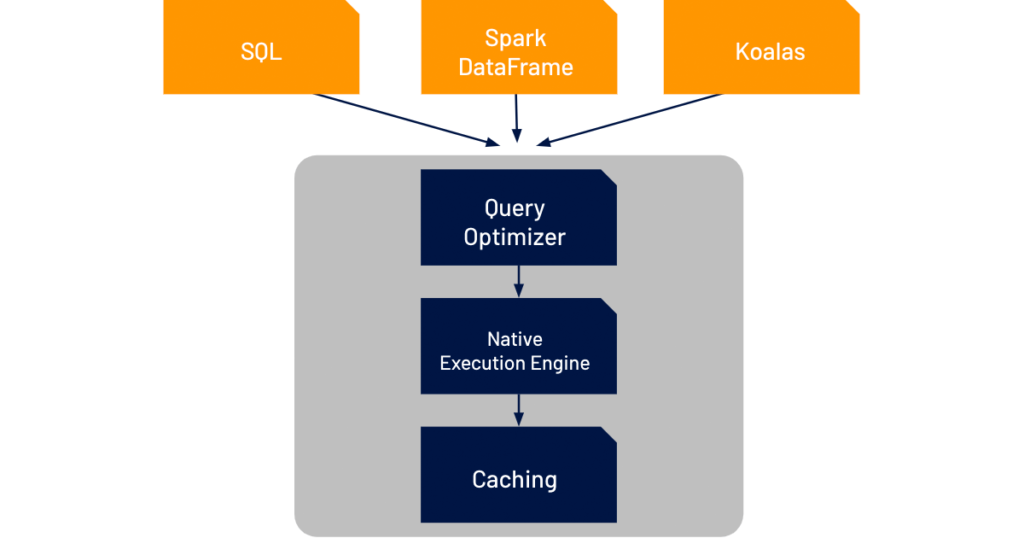
为了解决上面的一些问题,数砖专门开发了 Delta Engine,这个引擎专门用于数据分析的加速以及灵活适应多种工作负载。从下图可以看出 Delta Engine 主要包括三个组件:改进的查询优化器、位于执行层和云对象存储之间的缓存层,以及用 C++ 编写的原生向量化执行引擎(Photon),这个引擎可以加速使用 SQL 和 DataFrame 分析 Delta Lake 的工作负载。
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
Delta Engine 的查询优化器扩展了 Spark 3.0 中已有的功能,包括基于成本的优化器(CBO)、自适应查询执行(adaptive query execution)和动态运行时过滤器(dynamic runtime filters),提供了更高级的统计信息,在星型模式工作负载中提供了高达18倍的性能提升。
Delta Engine 的缓存层自动选择要为用户缓存的输入数据,并以一种 CPU 高效的格式对其进行代码转换,以更好地利用 NVMe SSDs 提高的存储速度。这几乎为所有工作负载提供了高达5倍的扫描性能。
Delta Engine 在解决数据团队面临的挑战方面最大的创新是原生执行引擎,这个引擎称为 Photon。这个引擎是完全重写的,目的是充分利用现代云硬件来最大化计算性能。这个引擎为所有类型的工作负载带来了性能改进,重要的是,这个引擎和开源的 Spark API 是完全兼容的。
Photon:原生向量化执行引擎
Delta Engine 中最重要的 Photon 是完全使用 C++ 实现的,其通过利用数据级并行和指令级并行大大提升计算能力,大大提升了 Delta Engine 上的 Spark SQL 查询,并且对结构化和非结构化的工作负载都有不同程度的优化。
尽管这么多年 CPU 的主频并没有什么变化,但是并行度却有不同程度的提升,主要包括 data-level 层面上的并行度和指令层面上的并行度。
比如我们的查询为 select sum(value) from table group by key,这个查询底层的实现变成下面的代码:
for (int32_t i = 0; i < batchSize; ++i) {
int32_t bucket = hash(keyCol[i]) % ht->size;
if (ht[bucket].key == keyCol[i]) {
ht[bucket].value += valueCol[i];
}
}
上面的代码访问内存(ht[bucket])的指令与计算哈希码(int32_t bucket = hash(keyCol[i]) % ht->size;)、比较键(key == keyCol[i])和加法(ht[bucket].value += valueCol[i];)的指令混合在一起。而且上面的循环体非常大,导致 CPU 很少看到内存访问指令。解决上面的问题是将上面大的循环体修改成更小的循环体,如下:
for (int32_t i = 0; i < batchSize; ++i) {
buckets[i] = hash(keyCol[i]) % ht->size;
}
for (int32_t i = 0; i < batchSize; ++i) {
keys[i] = ht[bucket].key;
}
for (int32_t i = 0; i < batchSize; ++i) {
if (keys[i] == keyCol[i]) {
ht[buckets[i]].value += valueCol[i];
}
}
经过上面指令层面的修改,带有 Photon 的 Delta Engine 比传统的引擎提升很多性能,

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
在 TPC-DS 30TB 数据量的测试下的表现提升了 3.3 倍。

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
String 优化
另外,在 String 的处理 Photon 也做了大量的优化。比如在使用 C++ 实现执行引擎之后,String 的 UPPER 和 SUBSTRING 函数操作性能相对 JVM 的实现有了大幅提升,如下:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
虽然 C++ 实现之后 string 的性能相对 JVM 的性能有所提升,但是数砖团队对这个进一步优化,结合 UTF-8 可变长度的编码和 ASCII 定长的编码,使得 Photon 引擎对字符串的操作进一步提升:

如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop
本文参考:Introducing Delta Engine:Maximum performance for traditional analytics workloads on Delta Lake
本博客文章除特别声明,全部都是原创!原创文章版权归过往记忆大数据(过往记忆)所有,未经许可不得转载。
本文链接: 【深入理解数砖的 Delta Engine】(https://www.iteblog.com/archives/9833.html)






