SQL Join 是最重要和最昂贵的 SQL 操作之一,需要数据库工程师深入理解才能编写高效的 SQL 查询。 从数据库工程师的角度来看,了解 JOIN 操作的工作原理有助于他们优化 JOIN 以实现高效执行。 本文介绍了开源分布式计算引擎 Presto SQL 支持的 join 操作。几乎所有众所周知的数据库都支持以下五种类型的 JOIN 操作:Cross Join, Inner Join, L 3年前 (2021-11-01) 1650℃ 0评论1喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca 3年前 (2021-11-01) 859℃ 0评论3喜欢
TPC-H是事务处理性能委员会( Transaction ProcessingPerformance Council )制定的基准程序之一,TPC- H 主要目的是评价特定查询的决策支持能力,该基准模拟了决策支持系统中的数据库操作,测试数据库系统复杂查询的响应时间,以每小时执行的查询数(TPC-H QphH@Siz)作为度量指标。我们在很多大数据系统上线或者产品上线的时候一般都会测 3年前 (2021-10-29) 1752℃ 0评论6喜欢
前言 OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。OPPO大数据离线计算发展历史大数据行业发展阶段 一家公司的技术发展,离不开整个行业的发展背景。我们简短回归 3年前 (2021-10-29) 785℃ 0评论2喜欢
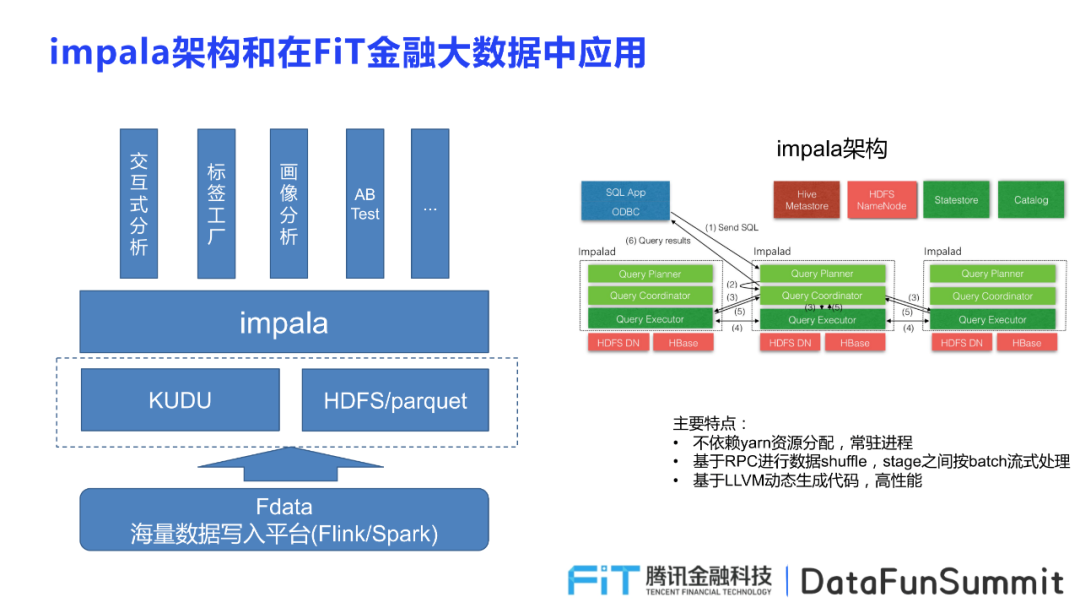
导读:在腾讯金融场景,我们每天都会产生大量的数据,为了提升分析的交互性,让决策更加敏捷,我们引入了Impala来解决我们的分析需求。所以,本文将和大家分享Impala在腾讯金融大数据场景中的应用架构,Impala的原理,落地过程的案例和优化以及总结思考。Impala的架构 首先介绍Impala的整体架构,帮助大家从宏观角度理 3年前 (2021-10-28) 443℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Best Practice in Accelerating Data Applications with Spark+Alluxio》的分享,作者来自 Alluxio 的 David Zhu。本次演讲将分享 Alluxio 和 Spark 集成解决方案的设计和用例,以及在设计和实现 Alluxio分 布式系统时的最佳实践以及不要做什么。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信 3年前 (2021-10-28) 590℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Enabling Presto Caching at Uber with Alluxio》的分享,作者来自 Uber 的 Zhongting Hu 和 Alluxio 发 Dr. Beinan Wang。Zhongting Hu is Tech Lead Manager of the Interactive Analytics Team at Uber. He is leading and managing Presto ecosystems inside Uber.Dr. Beinan Wang is a software engineer from Alluxio and is the committer of PrestoDB. Prior to Alluxio, he 3年前 (2021-10-27) 260℃ 0评论0喜欢
国内区 Apple ID 转美国区的教程参见:2021年最新中国区 Apple ID 转美国区教程注意:下面的操作步骤是在2021年10月29日进行的,过程中都没有使用到 VPN 软件。使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple I 3年前 (2021-10-22) 4488℃ 0评论7喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 3年前 (2021-10-21) 479℃ 0评论3喜欢
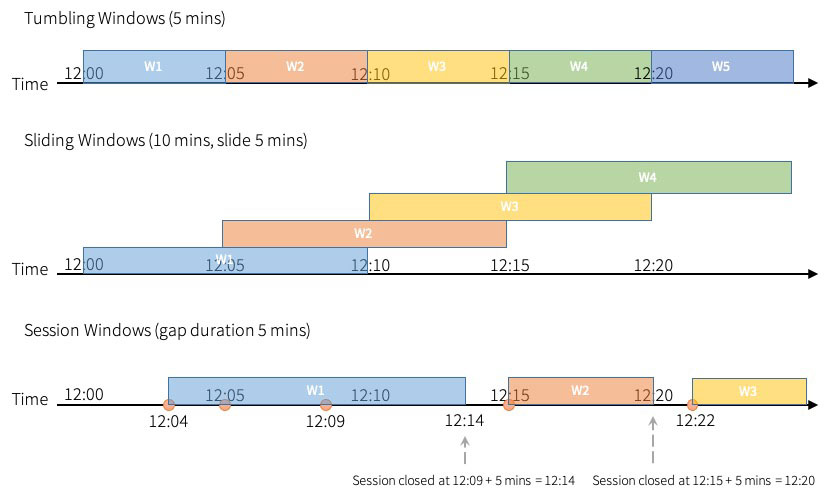
Apache Spark™ Structured Streaming 允许用户在事件时间的窗口上进行聚合。 在 Apache Spark 3.2™ 之前,Spark 支持滚动窗口(tumbling windows)和滑动窗口( sliding windows)。在已经发布的 Apache Spark 3.2 中,社区添加了“会话窗口(session windows)”作为新支持的窗口类型,它适用于流查询和批处理查询什么是会话窗口如果想及时了解Spark、Had 3年前 (2021-10-21) 887℃ 0评论0喜欢