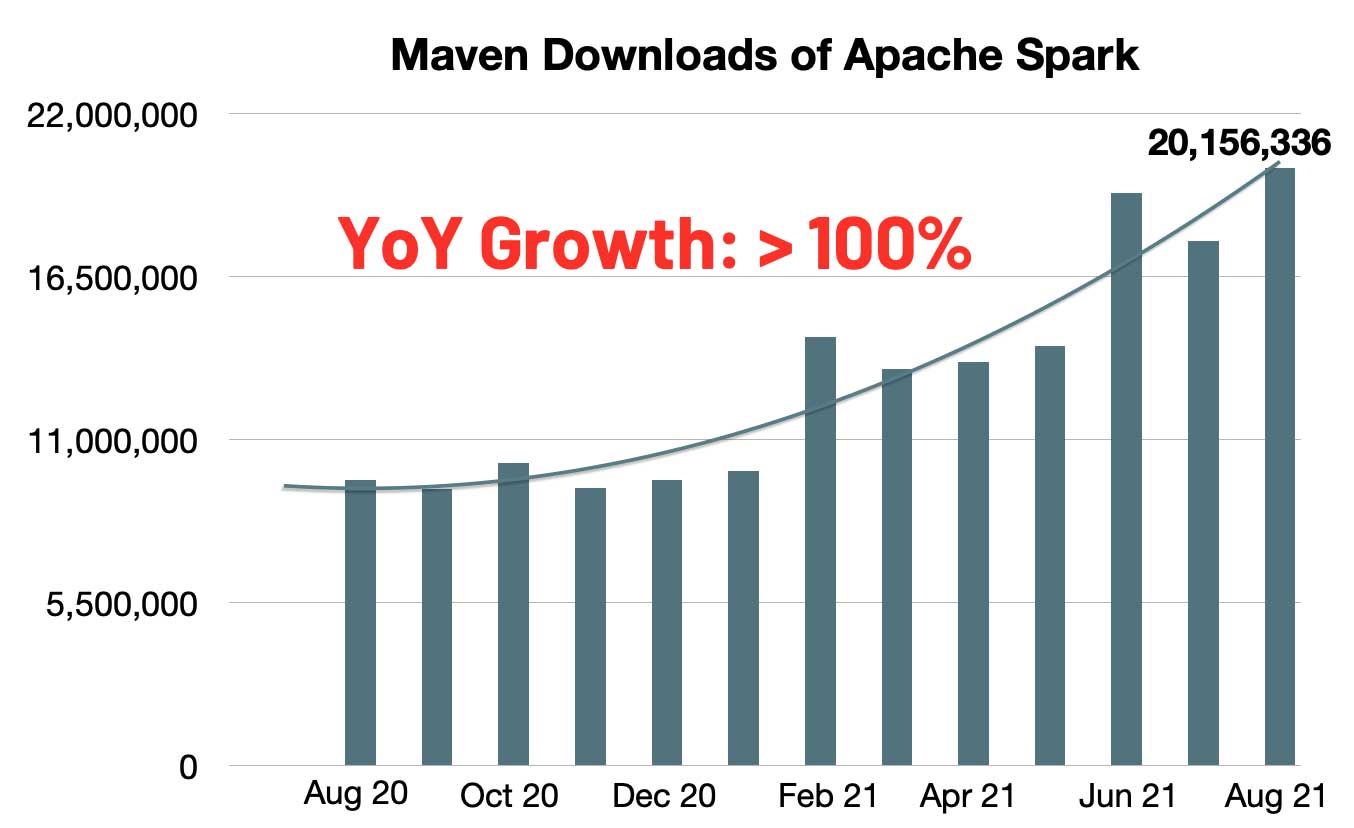
经过七轮投票, Apache Spark™ 3.2 终于在昨天正式发布了。Apache Spark™ 3.2 已经是 Databricks Runtime 10.0 的一部分,感兴趣的同学可以去试用一下。按照惯例,这个版本应该不是稳定版,所以建议大家不要在生产环境中使用。Spark 的每月 Maven 下载数量迅速增长到 2000 万,与去年同期相比,Spark 的月下载量翻了一番。Spark 已成为在单节 3年前 (2021-10-20) 1402℃ 0评论3喜欢
引言:把基于mapreduce的离线hiveSQL任务迁移到sparkSQL,不但能大幅缩短任务运行时间,还能节省不少计算资源。最近我们也把组内2000左右的hivesql任务迁移到了sparkSQL,这里做个简单的记录和分享,本文偏重于具体条件下的方案选择。迁移背景 SQL任务运行慢Hive SQL处理任务虽然较为稳定,但是其时效性已经达瓶颈,无法再进一 3年前 (2021-10-19) 935℃ 0评论2喜欢
到这个页面(https://hub.docker.com/_/centos?tab=tags)查看自己要下载的 Centos 版本:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop将指定版本的 CentOS 镜像拉到本地在本地使用下面命令进行拉取:[code lang="bash"][iteblog@iteblog.com]$ docker pull centos:centos7centos7: Pulling from library/centos6717b8ec66cd: Pull comp 3年前 (2021-10-17) 178℃ 0评论1喜欢
在即将发布的 Apache Spark™ 3.2 版本中 pandas API 将会成为其中的一部分。Pandas 是一个强大、灵活的库,并已迅速发展成为标准的数据科学库之一。现在,pandas 的用户将能够在他们现有的 Spark 集群上利用 pandas API。几年前,我们启动了 Koalas 这个开源项目,它在 Spark 之上实现了 Pandas DataFrame API,并被数据科学家广泛采用。最近,Koala 3年前 (2021-10-13) 877℃ 0评论3喜欢
在《ASM 与 Presto 动态代码生成简介》这篇文章中,我们简单介绍了 Presto 动态代码生成的原理以及 Presto 在计算表达式的地方会使用到动态代码生成技术。为了加深理解,本文将以两个例子介绍 Presto 里面动态代码生成的使用。EmbedVersion我们往 Presto 提交 SQL 查询以及 TaskExecutor 启动 TaskRunner 执行 Task 的时候都会使用到 EmbedVersion 类 3年前 (2021-10-12) 730℃ 0评论1喜欢
全新美国区 Apple ID 注册教程参见:2021年最新美区 Apple ID 注册教程使用苹果手机的有可能知道,国内使用的 App Store 只能下载国内的一些 APP 应用。有一些 APP 并没有在国内 App Store 上架,这时候就无法下载。我们需要使用一个国外的 Apple ID 账号,但是很多人手上一般都是只有国内的账号,这篇文章就来教大家如何把一个中国区的 3年前 (2021-10-10) 1661℃ 0评论2喜欢
Presto 是由 Facebook 开发并开源的分布式 SQL 交互式查询引擎,很多公司都是用它实现 OLAP 业务分析。本文列出了 Presto 常用的函数列表。数学函数数学函数作用于数学公式。下表给出了详细的数学函数列表。abs(x)返回 x 的绝对值。使用如下:[code lang="bash"]presto:default> select abs(1.23) as absolute; absolute ---------- 1.23[/code] 3年前 (2021-10-07) 5925℃ 0评论1喜欢
代码生成是很多计算引擎中常用的执行优化技术,比如我们熟悉的 Apache Spark 和 Presto 在表达式等地方就使用到代码生成技术。这两个计算引擎虽然都用到了代码生成技术,但是实现方式完全不一样。在 Spark 中,代码生成其实就是在 SQL 运行的时候根据相关算子动态拼接 Java 代码,然后使用 Janino 来动态编译生成相关的 Java 字节码并 4年前 (2021-09-28) 713℃ 0评论3喜欢
Apache Kafka 3.0 于2021年9月21日正式发布。本文将介绍这个版本的新功能。以下文章翻译自 《What's New in Apache Kafka 3.0.0》。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据我很高兴地代表 Apache Kafka® 社区宣布 Apache Kafka 3.0 的发布。 Apache Kafka 3.0 是一个大版本,其引入了各种新功能、API 发生重 4年前 (2021-09-24) 647℃ 0评论2喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn 4年前 (2021-09-23) 915℃ 0评论4喜欢