Apache Kafka 的核心设计是日志(Log)—— 一个简单的数据结构,使用顺序操作。以日志为中心的设计带来了高效的磁盘缓冲和 CPU 缓存使用、预取、零拷贝数据传输和许多其他好处,从而使 Kafka 能够提供高效率和吞吐量的功能。对于那些刚接触 Kafka 的人来说,主题(topic)以及提交日志的底层实现通常是他们学习的第一件事。但 4年前 (2021-04-11) 795℃ 0评论4喜欢
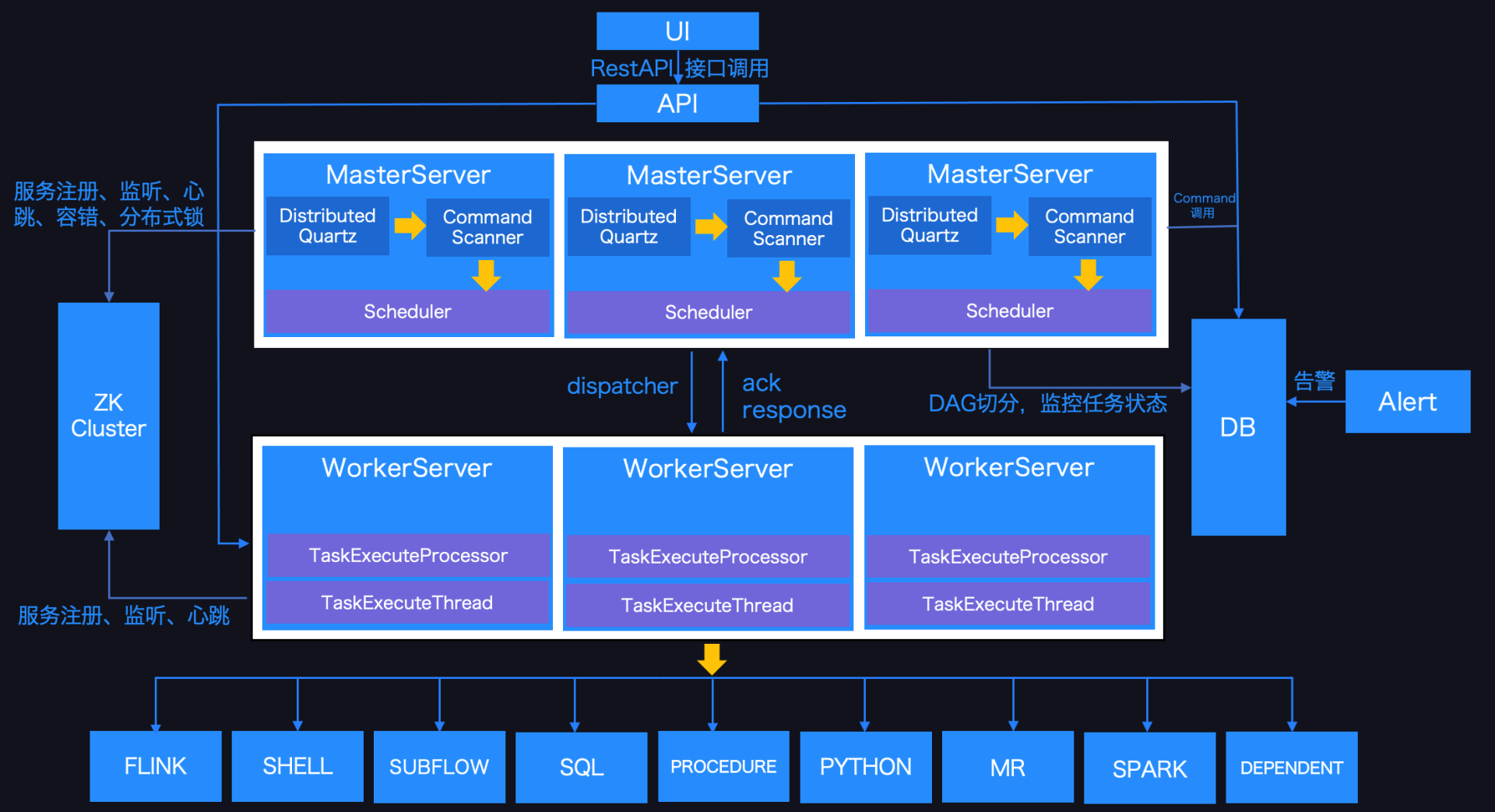
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 4年前 (2021-04-09) 1882℃ 0评论3喜欢
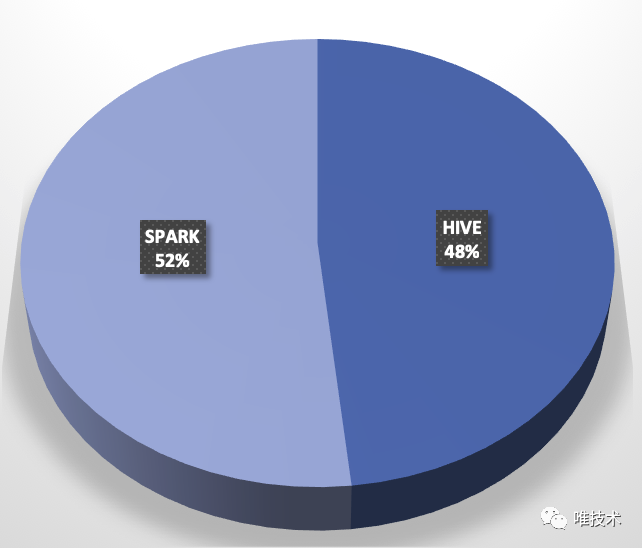
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, 4年前 (2021-04-05) 1354℃ 0评论4喜欢
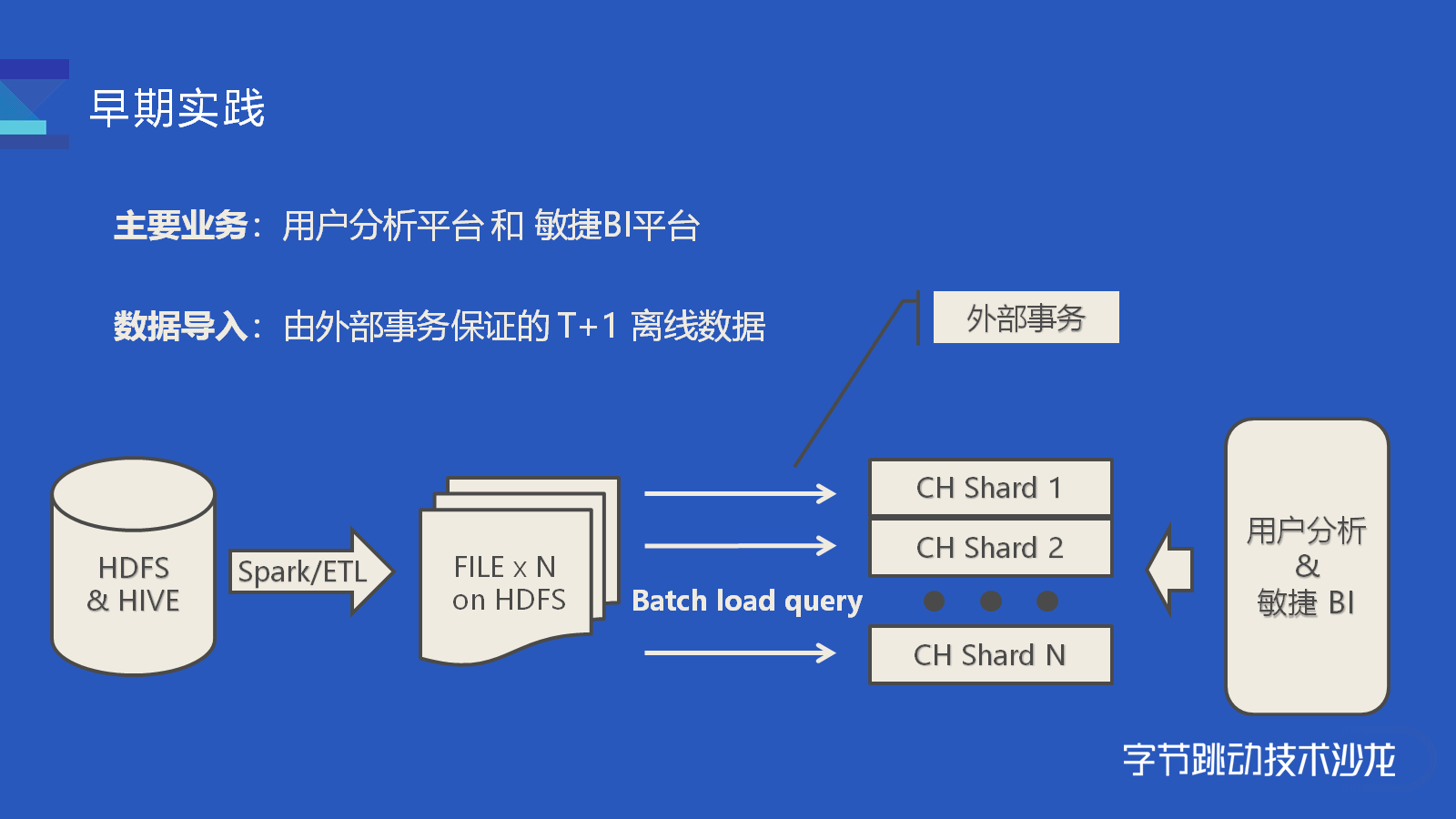
讲师:郭映中 字节跳动 ClickHouse 研发工程师此次分享分为三部分内容,第一部分通过讲解推荐和广告业务的两个典型案例,穿插介绍字节内部相应的改进。第二部分会介绍典型案例中未覆盖到的改进和经验。第三部分会提出目前的不足和未来的改进计划。早期实践如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注 4年前 (2021-03-05) 4788℃ 0评论5喜欢
Hive 设计之初,就被定位一款离线数仓产品,虽然Hortonworks喊出了Make Apache Hive 100x Faster的牛逼口号,也在上面做了大量的优化,然而性能提升依旧不大。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆而随着OPPO数据量一步步的增多,动辄运行几个小时的hive再也满足不了交互查询的需求,因此我们 4年前 (2021-03-05) 1070℃ 0评论6喜欢
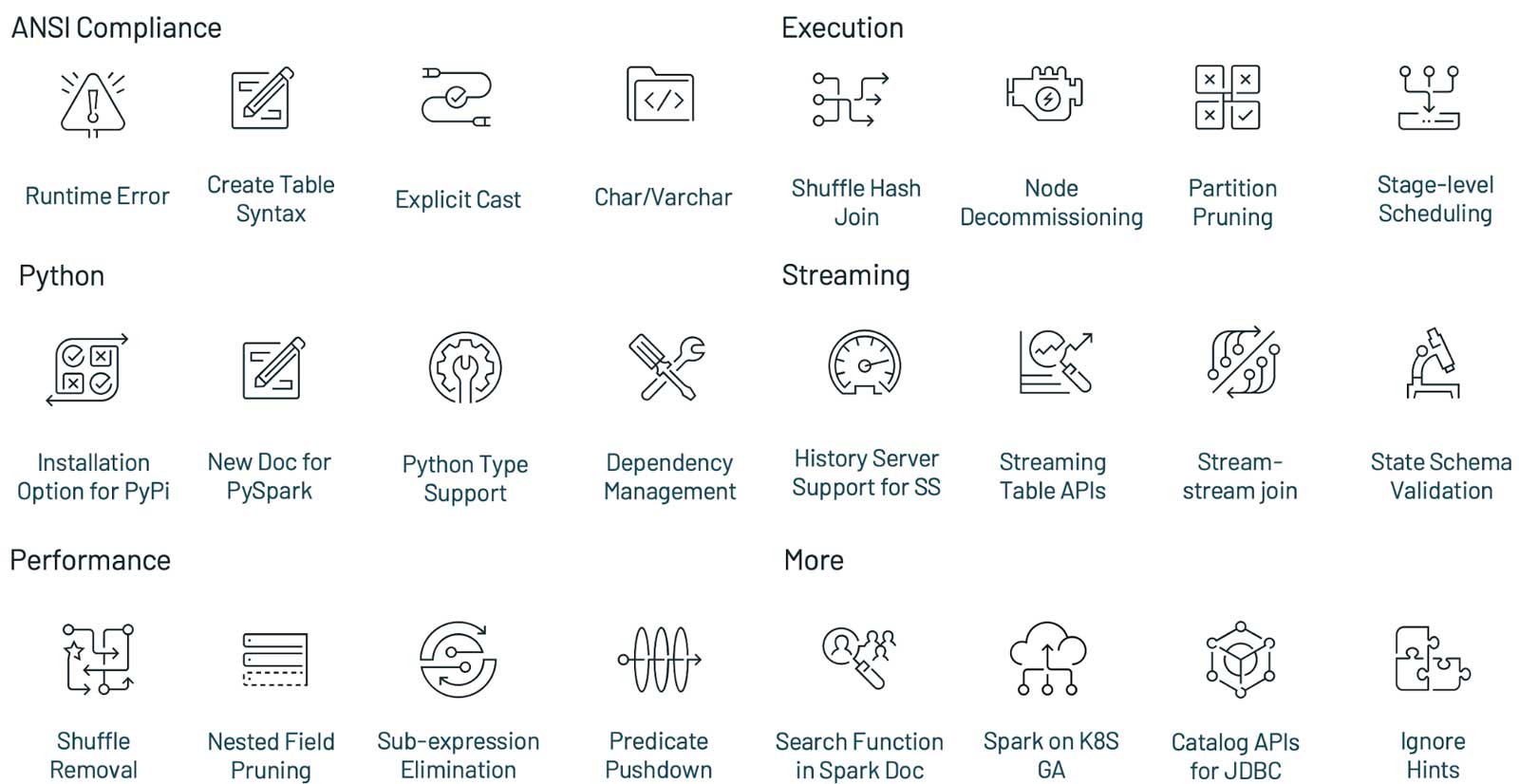
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 4年前 (2021-03-03) 2356℃ 0评论10喜欢
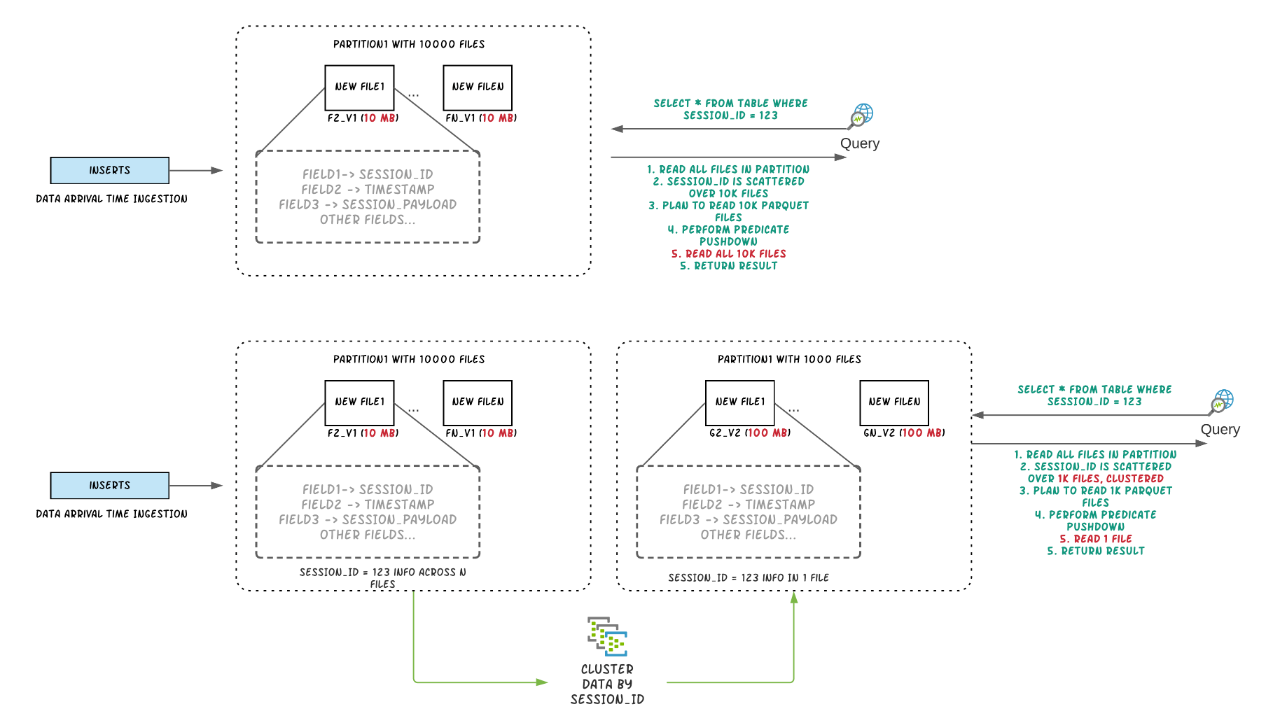
背景Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频 4年前 (2021-02-24) 1581℃ 0评论4喜欢
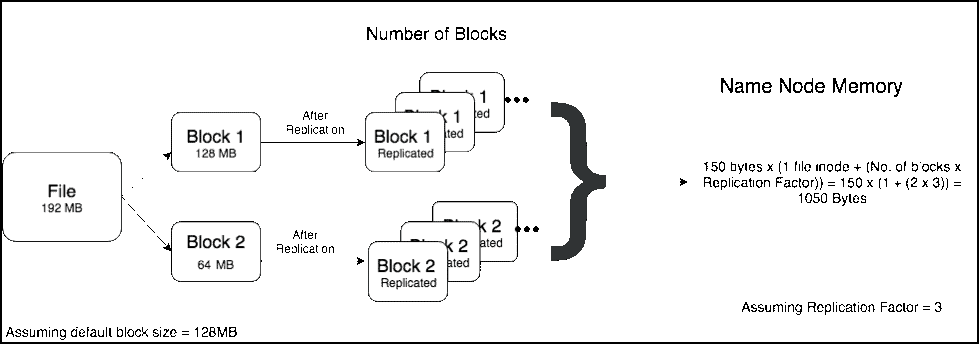
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 4年前 (2021-02-24) 1073℃ 0评论6喜欢
This topic describes tips for tuning parallelism and memory in Presto. The tips are categorized as follows:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopTuning Parallelism at a Task LevelThe number of splits in a cluster = node-scheduler.max-splits-per-node * number of worker nodes.The node-scheduler.max-splits-per-node denotes the target value for the total num 4年前 (2021-02-20) 1194℃ 0评论4喜欢
2021年2月15日,Apache Flink 创建者、Ververica 公司(前身 DataArtisans)的联合创始人 Fabian Hueske 在 Twitter 宣布其已经从 Ververica 离职, 不过离职原因不得而知。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop另外,Ververica 公司原 COO Holger Temme 将接替 Kostas Tzoumas 成为新的 CEO。Kostas Tzoumas (原 CEO) 4年前 (2021-02-18) 1130℃ 0评论5喜欢