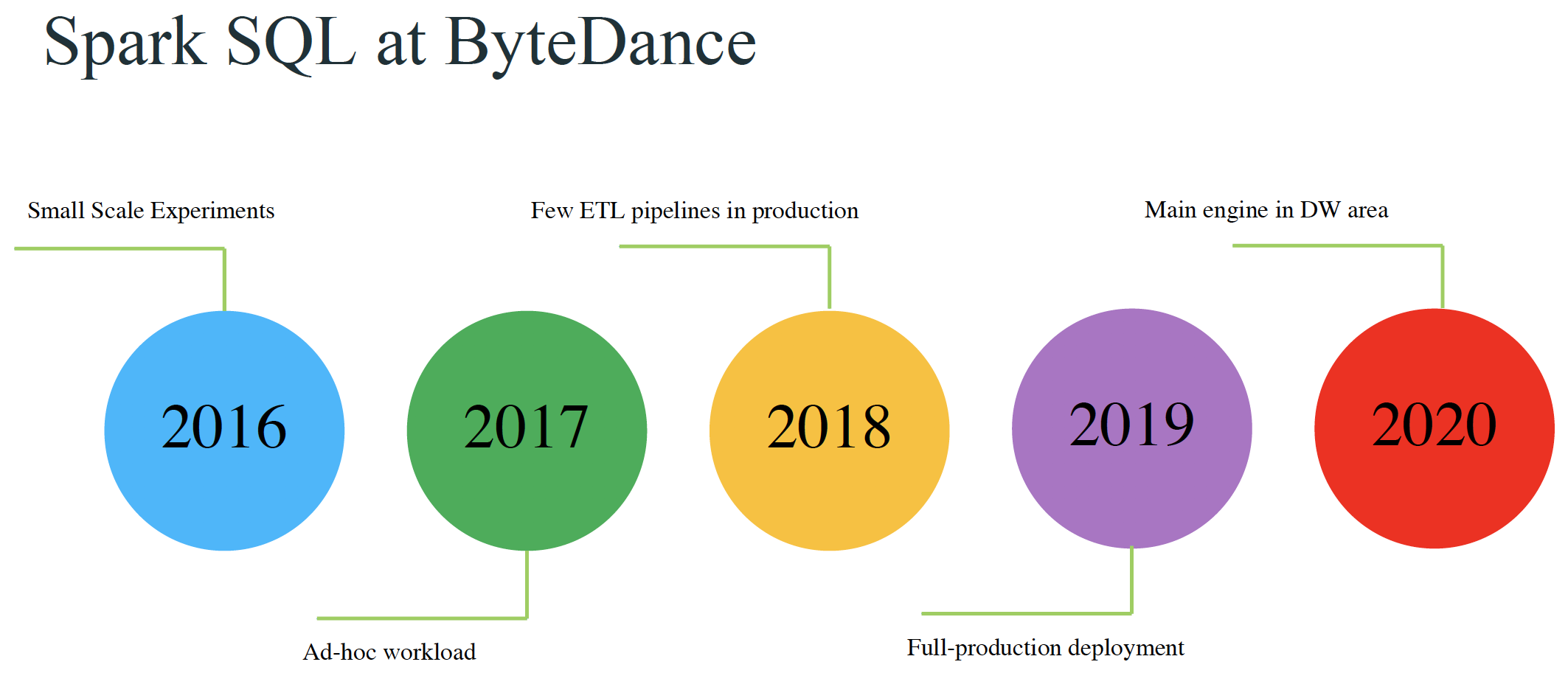
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 4年前 (2020-12-13) 905℃ 0评论3喜欢
2020年12月01日,IntelliJ IDEA 2020.3 正式发布,这是2020年的第三个里程碑版本。2020年其他两个版本可以参见IntelliJ IDEA 2020.2 稳定版发布 和 IntelliJ IDEA 2020.1 稳定版发布。本文主要介绍 IntelliJ IDEA 2020.3 的新功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop用户体验重新设置欢迎界面这个 4年前 (2020-12-10) 1104℃ 0评论0喜欢
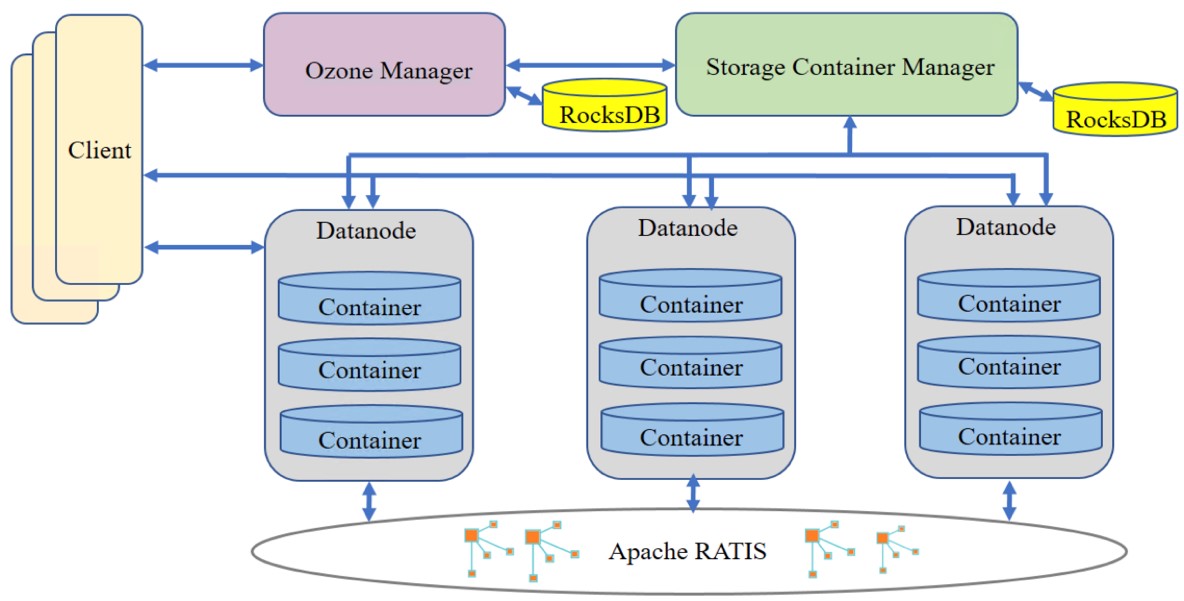
刚刚获悉,Apache基金董事会通过一致表决,正式批准分布式文件对象存储Ozone从Hadoop社区孵化成功,成为独立的Apache顶级开源项目。这意味着,作为腾讯大数据团队首个参与和主导的开源项目,Ozone已得到全球Apache技术专家的一致认可,成为世界顶级的存储开源项目之一。Ozone 是Apache Hadoop社区推出的面向大数据领域的新一代分布 4年前 (2020-12-09) 1134℃ 0评论7喜欢
Data + AI Summit Europe 2020 原 Spark + AI Summit Europe 于2020年11月17日至19日举行。由于新冠疫情影响,本次会议和六月份举办的会议一样在线举办,一共为期三天,第一天是培训,第二天和第三天是正式会议。会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习框架来 4年前 (2020-12-06) 1191℃ 0评论2喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I 4年前 (2020-11-29) 3759℃ 0评论4喜欢
背景数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概念上的翻新(新瓶装旧酒)呢?它到底解决了什么问题,拥有什么样新的特性呢?它的现状是什么,还存在什么问题呢? 4年前 (2020-11-28) 5741℃ 0评论7喜欢
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: Flink 与 Hive 集成的 4年前 (2020-11-26) 2389℃ 0评论11喜欢
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 4年前 (2020-11-25) 1727℃ 0评论5喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 4年前 (2020-11-24) 1184℃ 0评论4喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件 4年前 (2020-11-24) 1413℃ 0评论2喜欢