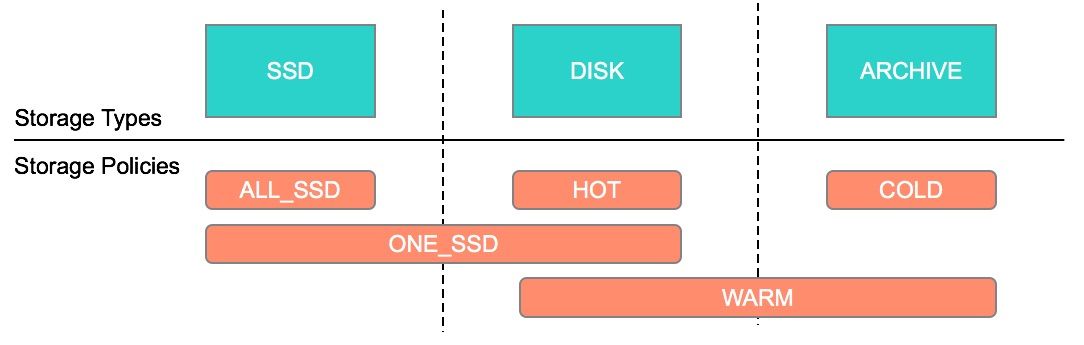
介绍HDFS 归档存储(Archival Storage)是从 Hadoop 2.6.0 开始引入的(参见 HDFS-6584)。归档存储是一种将增长的存储容量与计算容量解耦的解决方案。我们可以在集群中部署一些具有更高密度、更便宜的存储且提供更低计算能力的节点,并且可以用作集群中的冷数据存储器。根据我们的设置,可以将热数据移到冷存储介质中。通过添加更 5年前 (2020-04-15) 1820℃ 0评论3喜欢
随着我们使用 Docker 的次数越来越多,我们电脑里面可能已经存在很多 Docker 镜像,大量的镜像会占据大量的存储空间,所有很有必要清理一些不需要的镜像。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop镜像的删除在删除镜像之前,我们可以看下系统里面都有哪些镜像:[code lang="bash"][ite 5年前 (2020-04-14) 629℃ 0评论1喜欢
IntelliJ IDEA 2020.1 稳定版来了!这是今年发布的首个重大更新版本,新版本增加了对 Java 14 的支持、为部分 Web 和测试框架添加新功能、为调试器添加数据流分析协助功能(dataflow analysis assistance)、新增 LightEdit 模式,以及支持从 IDE 下载和配置 JDK。下载地址 https://www.jetbrains.com/idea/download,也可以使用 Toolbox App 进行更新 5年前 (2020-04-10) 214℃ 0评论3喜欢
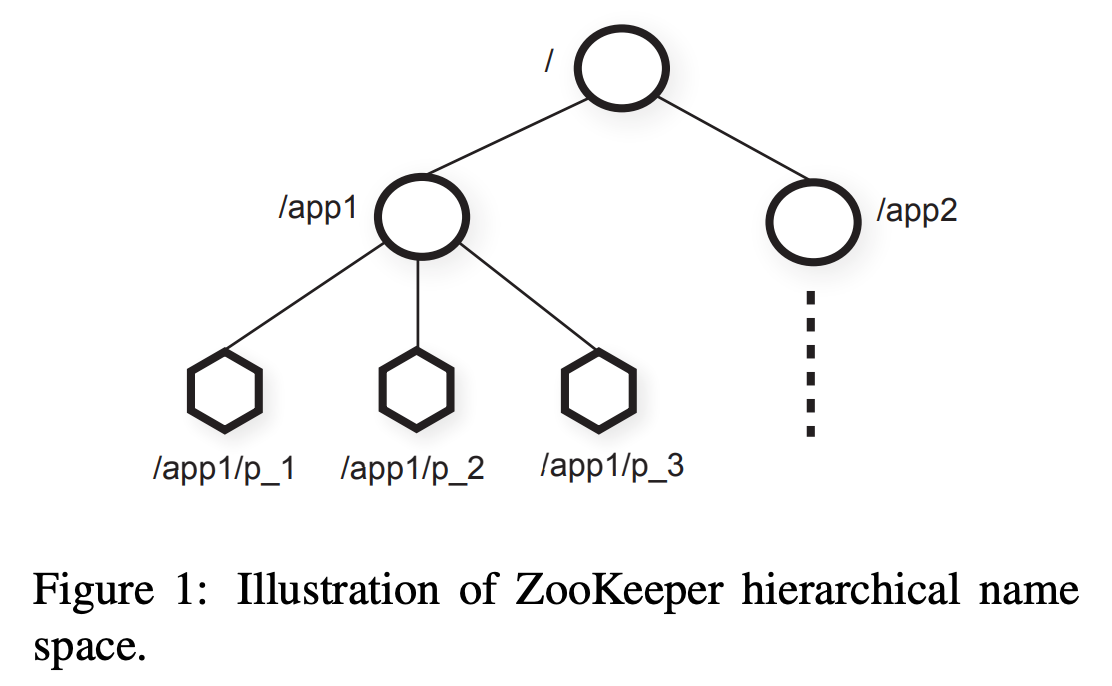
摘要本文描述分布式应用的协调服务:ZooKeeper。ZooKeeper是关键基础设施的一部分,其目标是给客户端提供简洁高性能内核用于构建复杂协调原语。在一个多副本、中心化服务中,结合了消息群发、共享注册和分布式锁等内容。ZooKeeper提供的接口有共享注册无等待的特点,与事件驱动的分布式系统缓存失效类似,还提供了强大的协调 5年前 (2020-03-17) 593℃ 0评论2喜欢
本文主要讲解 Kafka 是什么、Kafka 的架构包括工作流程和存储机制,以及生产者和消费者,最终大家会掌握 Kafka 中最重要的概念,分别是 broker、producer、consumer、consumer group、topic、partition、replica、leader、follower,这是学会和理解 Kafka 的基础和必备内容。1. 定义Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主 5年前 (2020-03-14) 1649℃ 0评论10喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 5年前 (2020-03-09) 2411℃ 0评论8喜欢
Java 14 计划将会在今年的3月17日发布,Java 14 包含的 JEP(Java Enhancement Proposals 的缩写,Java 增强建议)比 Java 12 和 13 两个版本加起来还要多。那么,对于每天编写和维护代码的 Java 开发人员来说,哪个特性值得我们关注呢?如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文我将介绍以下几个重 5年前 (2020-03-07) 949℃ 0评论2喜欢
目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 5年前 (2020-03-05) 4019℃ 0评论2喜欢
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主题覆盖度、性能、易用性、可扩展性及数 5年前 (2020-03-01) 2029℃ 0评论7喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopApache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。如果想及时了解Spark、Hadoop或者HBase 5年前 (2020-02-23) 3051℃ 0评论6喜欢