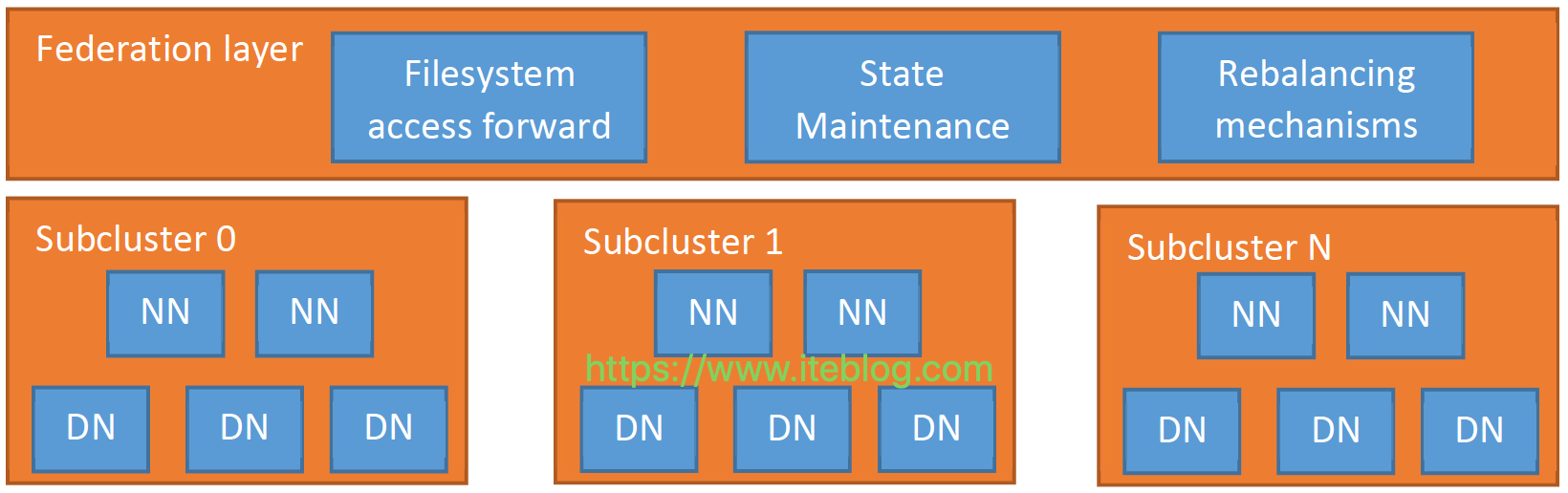
在 《Apache Hadoop 的 HDFS federation 前世今生(上)》 已经介绍了 Hadoop 2.9.0 版本之前 HDFS federation 存在的问题,那么为了解决这个问题,社区采取了什么措施呢?HDFS Router-based FederationViewFs 方案虽然可以很好的解决文件命名空间问题,但是它的实现有以下几个问题:ViewFS 是基于客户端实现的,需要用户在客户端进行相关的配置,那 6年前 (2019-07-26) 2085℃ 0评论2喜欢
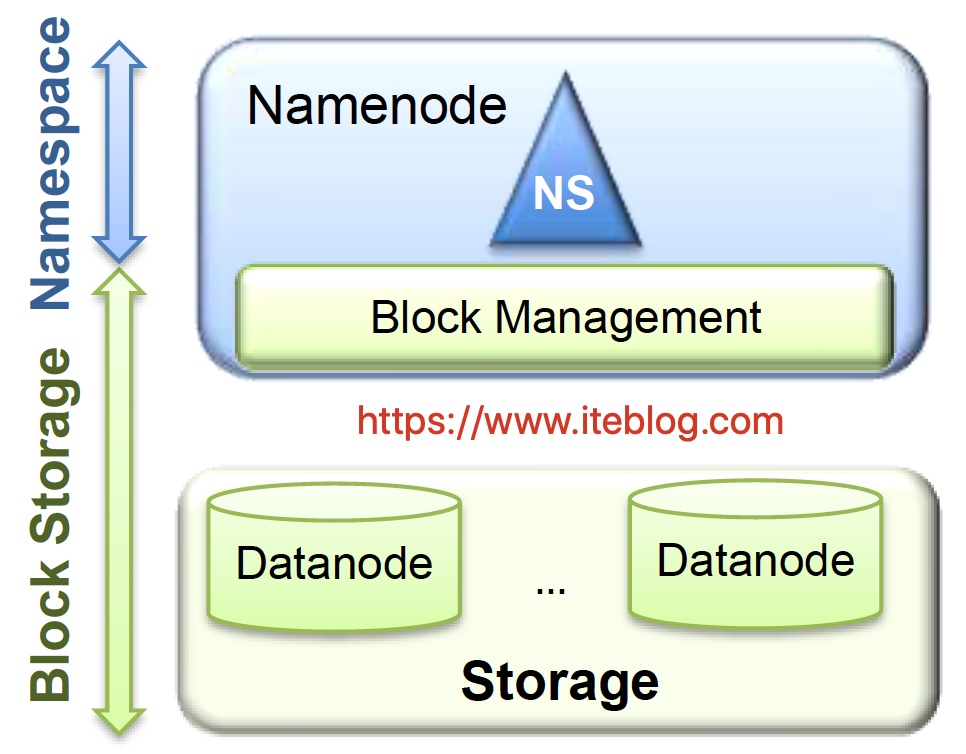
背景熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从 6年前 (2019-07-25) 2285℃ 0评论3喜欢
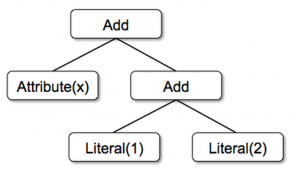
Spark SQL 是 Spark 最新且技术最复杂的组件之一。它同时支持 SQL 查询和新的 DataFrame API。Spark SQL 的核心是 Catalyst 优化器,它以一种全新的方式利用高级语言的特性(例如:Scala 的模式匹配和 Quasiquotes ①)构建一个可扩展的查询优化器。最近我们在 SIGMOD 2015 发表了一篇论文(合作者:Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan 6年前 (2019-07-21) 3336℃ 0评论5喜欢
2019 年 7 月 17 日,Cloudera 官方博客发文开源了一个内部研发使用很久的大数据存储和通用计算平台交叉的新项目 YuniKorn。Yunikorn 是一个新的独立通用资源调度程序,负责为大数据工作负载分配/管理资源,包括批处理作业和长时间运行的服务。介绍YuniKorn 是一种轻量级的通用资源调度程序,适用于容器编排系统(container orchestrator s 6年前 (2019-07-17) 3834℃ 0评论0喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 6年前 (2019-06-27) 3083℃ 0评论6喜欢
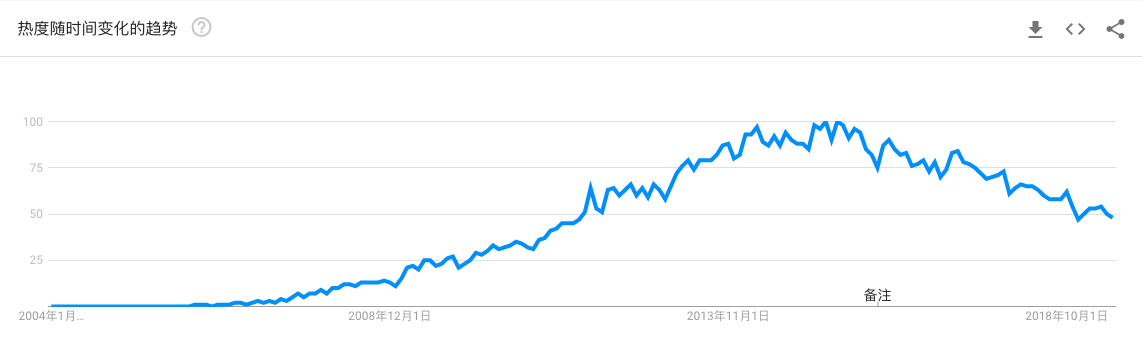
Hadoop我先从一个悲观的观点说起:Hadoop 正在迅速失去市场,我们可以从 Google 趋势走向看出这个现象:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面的炒作生命周期表也上面的趋势很类似:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop看起来 Hadoo 6年前 (2019-06-23) 3695℃ 0评论32喜欢
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。全阶段代码生成阶段 - WholeStageCodegen前面 6年前 (2019-06-19) 9177℃ 0评论17喜欢
在 《一条 SQL 在 Apache Spark 之旅(上)》 文章中我们介绍了一条 SQL 在 Apache Spark 之旅的 Parser 和 Analyzer 两个过程,本文接上文继续介绍。优化逻辑计划阶段 - Optimizer在前文的绑定逻辑计划阶段对 Unresolved LogicalPlan 进行相关 transform 操作得到了 Analyzed Logical Plan,这个 Analyzed Logical Plan 是可以直接转换成 Physical Plan 然后在 Spark 中执 6年前 (2019-06-18) 5775℃ 4评论21喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org 6年前 (2019-06-14) 1000℃ 0评论1喜欢
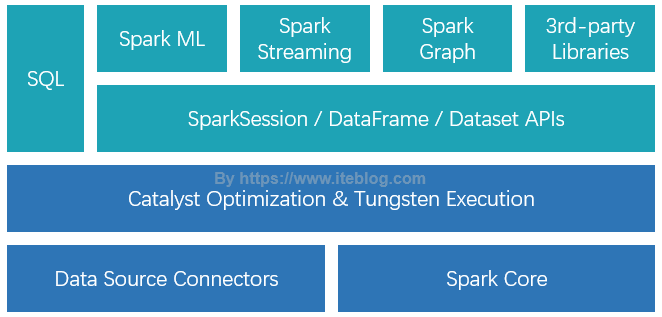
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 6年前 (2019-06-12) 11016℃ 0评论31喜欢