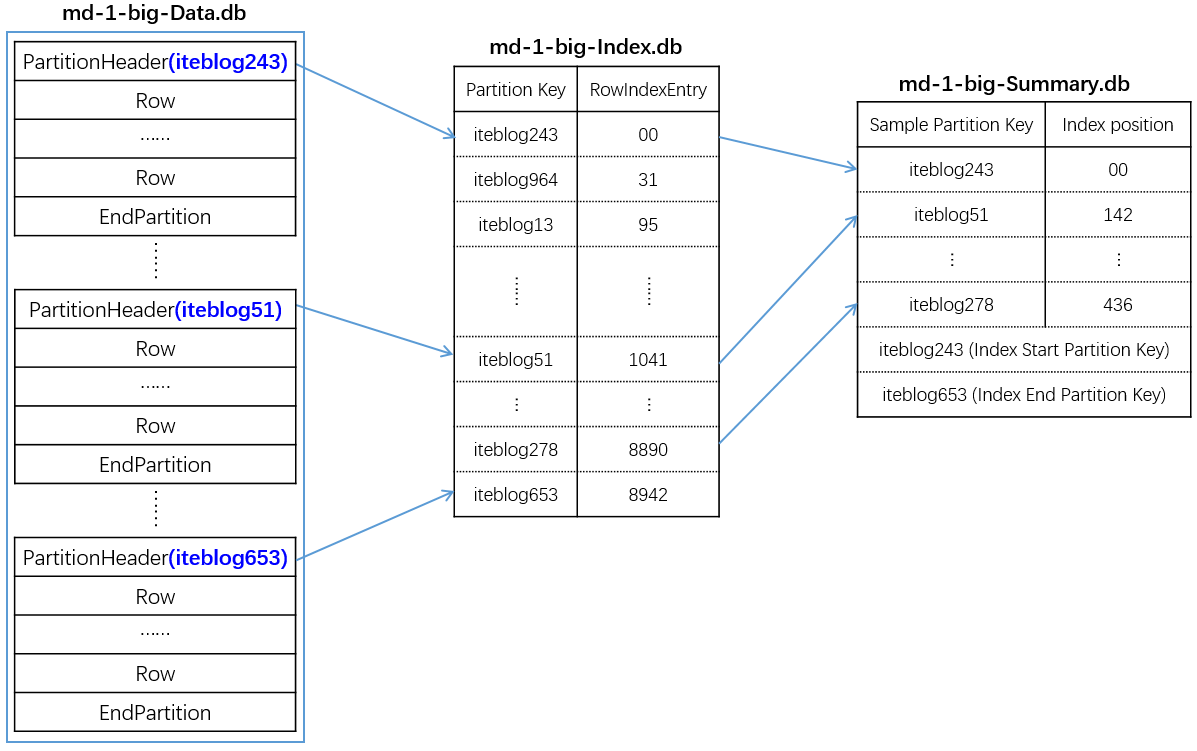
学过大数据的同学应该都知道 Kafka,它是分布式消息订阅系统,有非常好的横向扩展性,可实时存储海量数据,是流数据处理中间件的事实标准。本文将介绍 Kafka 是如何保证数据可靠性和一致性的。数据可靠性Kafka 作为一个商业级消息中间件,消息可靠性的重要性可想而知。本文从 Producter 往 Broker 发送消息、Topic 分区副本以及 6年前 (2019-06-11) 12949℃ 2评论42喜欢
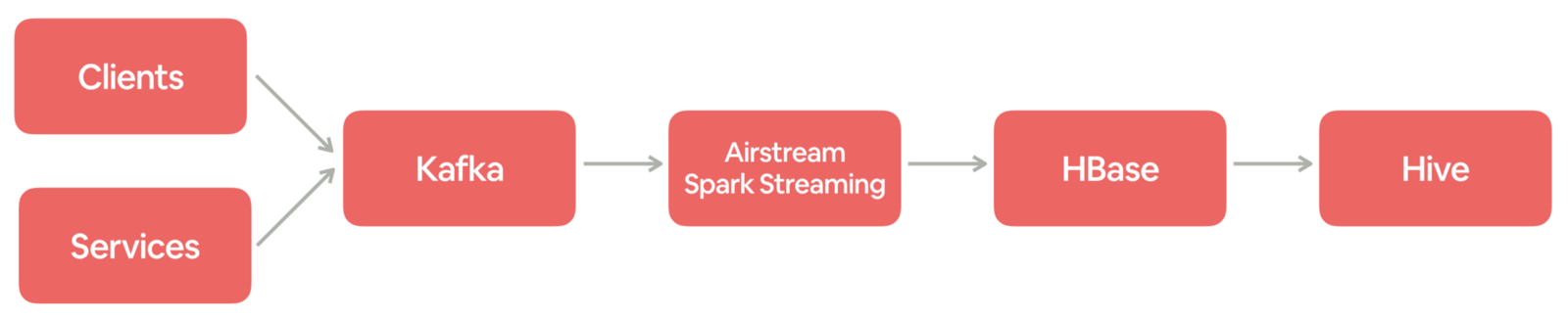
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 6年前 (2019-06-06) 3328℃ 0评论8喜欢
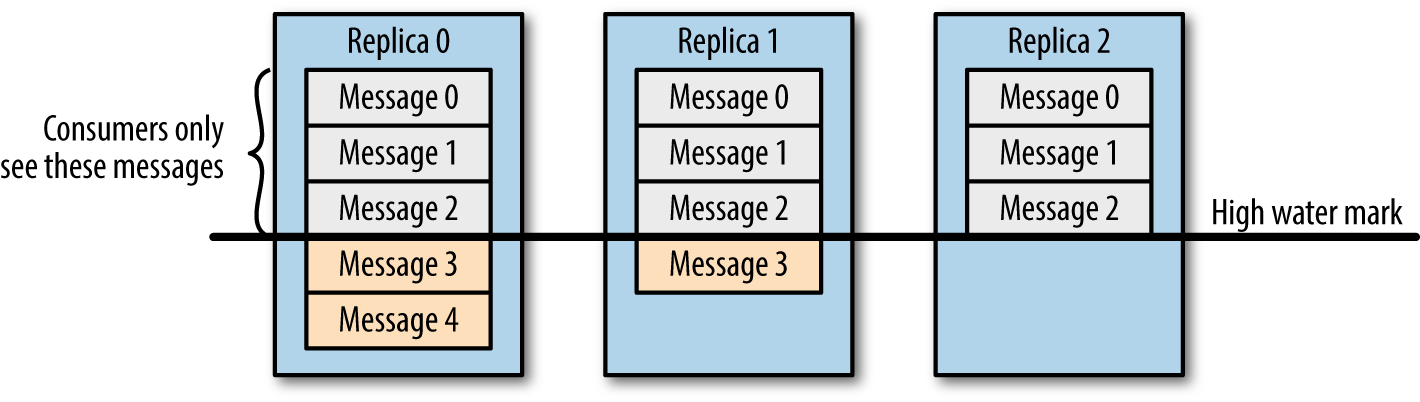
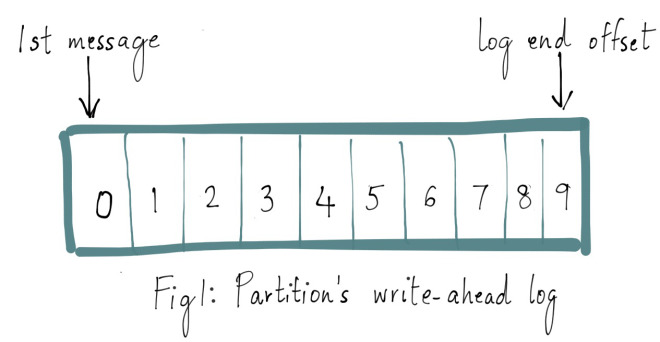
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 6年前 (2019-05-26) 5192℃ 1评论14喜欢
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 6年前 (2019-05-19) 2906℃ 0评论8喜欢
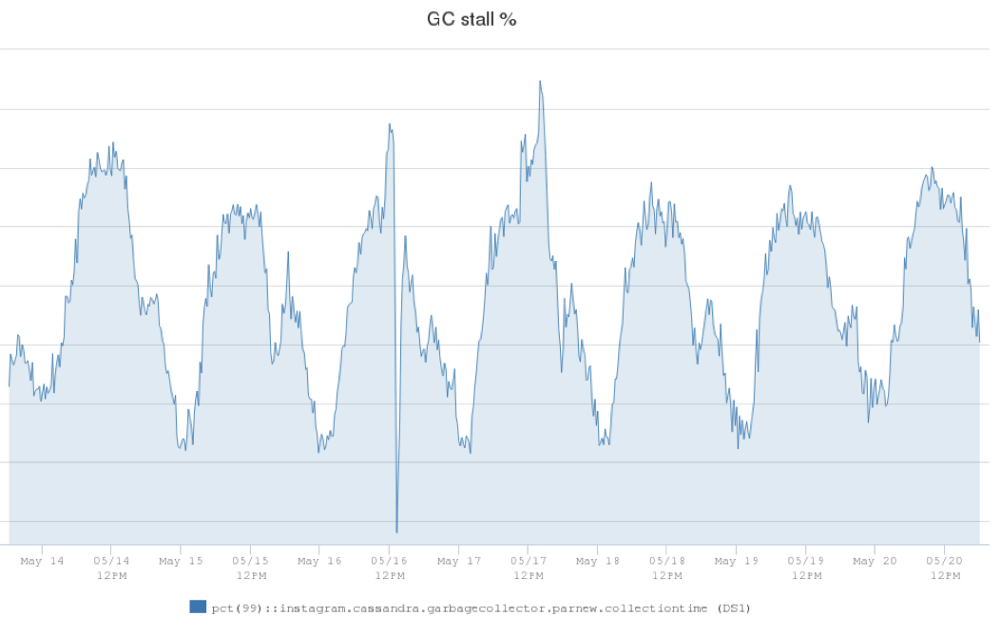
在 Instagram (Instagram 是 Facebook 公司旗下一款免费提供在线图片及视频分享的社交应用软件,于2010年10月发布。)上,我们拥有世界上最大的 Apache Cassandra 数据库部署。我们在 2012 年开始使用 Cassandra 取代 Redis ,在生产环境中支撑欺诈检测,Feed 和 Direct inbox 等产品。起初我们在 AWS 环境中运行了 Cassandra 集群,但是当 Instagram 架构发生 6年前 (2019-05-08) 1168℃ 0评论0喜欢
Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。更多特点请参见 一篇文章了解 Apache Cassandra 是什么。由于 Cassandra 数据库的众多优点,在国内外多达 1500+ 家公 6年前 (2019-05-08) 1814℃ 0评论5喜欢
为期三天的 SPARK + AI SUMMIT 2019 于 2019年04月23日-25日在旧金山(San Francisco)进行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。作为大数据领域的顶级会议,Spark+AI Summit 2019 吸引了全球大量技术大咖参会,而且 Spark+AI Summit 越做越大,本次会议议题快接近200多个。会议的 6年前 (2019-05-07) 859℃ 0评论0喜欢
在 Cassandra 中,当达到一定条件触发 flush 的时候,表对应的 Memtable 中的数据会被写入到这张表对应的数据目录(通过 data_file_directories 参数配置)中,并生成一个新的 SSTable(Sorted Strings Table,这个概念是从 Google 的 BigTable 借用的)。每个 SSTable 是由一系列的不可修改的文件组成,这些文件在 Cassandra 中被称为 Component。本文是基于 Cas 6年前 (2019-05-05) 2226℃ 1评论4喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 6年前 (2019-04-29) 3401℃ 0评论6喜欢
2019年4月25日,微软的 Rahul Potharaju、Terry Kim 以及 Tyson Condie 在 Spark + AI Summit 2019 会议上为我们带来主题为 《Introducing .NET Bindings for Apache Spark 》的分享,并宣布 .NET for Apache Spark 预览版正式发布。.NET 框架是由微软开发,一个致力于敏捷软件开发、快速应用开发、平台无关性和网络透明化的免费软件框架,用于构建许多不同类型的 6年前 (2019-04-28) 16491℃ 0评论4喜欢


![Spark+AI Summit 2019 PPT 下载[共124个]](https://www.iteblog.com/pic/spark/spark+ai_summit_2019-iteblog.png)