Apache Cassandra 是一个开源的、分布式、无中心、弹性可扩展、高可用、容错、一致性可调、面向行的数据库,它基于 Amazon Dynamo 的分布式设计和 Google Bigtable 的数据模型,由 Facebook 创建,在一些最流行的网站中得到应用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么会诞生 Apache Cassand 6年前 (2019-03-31) 3250℃ 4评论6喜欢
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 6年前 (2019-03-20) 8309℃ 5评论29喜欢
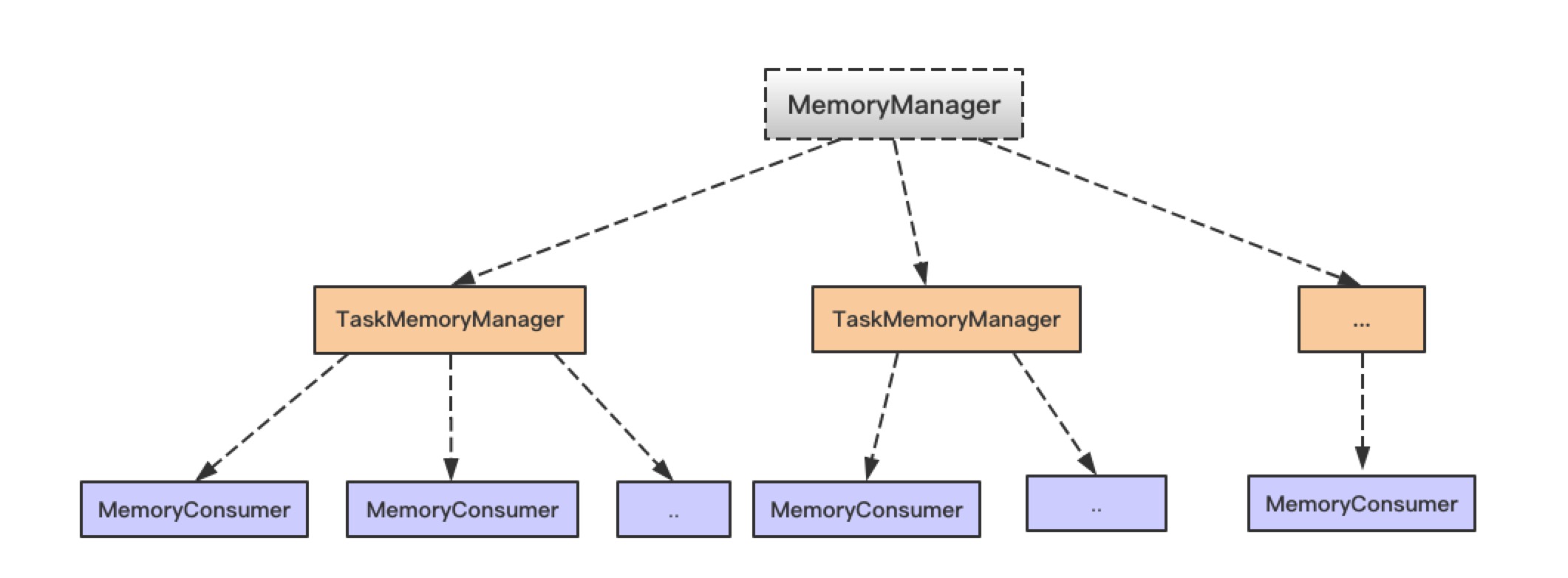
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段。那么在 Spark Shuffle 中具体是哪些地方会使用比较多的内存而有可能导致 OOM 呢? 为此,本文将围绕以上问题梳理 Spark 内存管理和 Shuffle 过程中与内存使用相关的知识;然后,简要分析下在 Spark Shuffle 中有可能导致 OOM 6年前 (2019-03-17) 5438℃ 0评论19喜欢
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 6年前 (2019-03-16) 5266℃ 1评论8喜欢
AWS 于近期发布了自家版本的开源 ElasticSearch :Open Distro for Elasticsearch。我们都知道,Elasticsearch 是一个分布式面向文档的搜索和分析引擎。 它支持结构化和非结构化查询,并且不需要提前定义模式。 Elasticsearch 可用作搜索引擎,通常用于 Web 级日志分析,实时应用程序监控和点击流分析,在国内外有很多用户使用。AWS 通过 AWS Elasticse 6年前 (2019-03-13) 4337℃ 0评论10喜欢
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自 Databricks、NVIDIA、Google 以及阿里巴巴的工程师们正在为 Apache Spark 添加 6年前 (2019-03-10) 6507℃ 0评论9喜欢
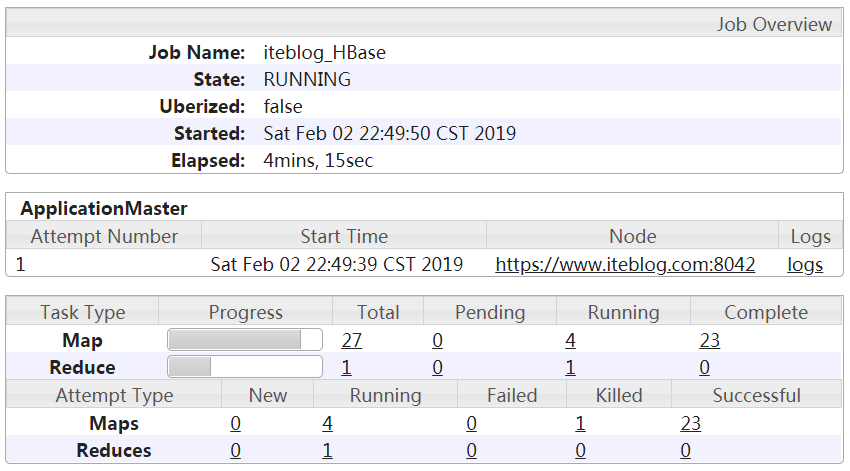
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm 6年前 (2019-02-27) 2963℃ 0评论7喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper 6年前 (2019-02-26) 3913℃ 0评论16喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 6年前 (2019-02-24) 4765℃ 0评论11喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 6年前 (2019-02-20) 3246℃ 0评论8喜欢