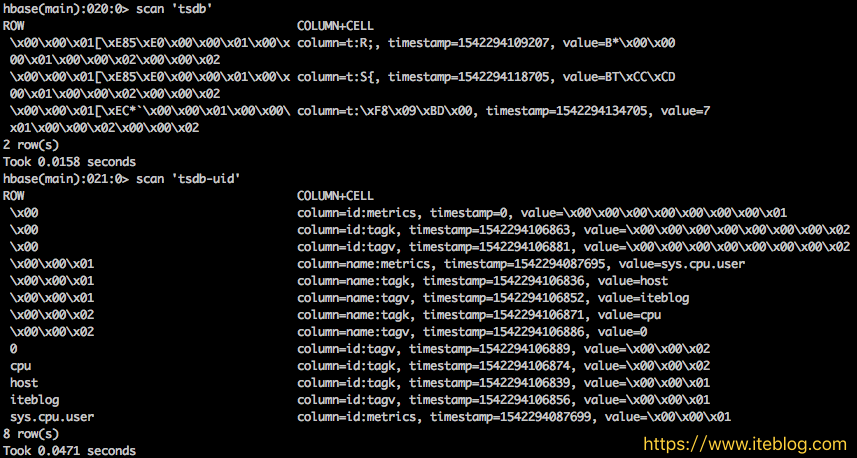
通过《OpenTSDB 底层 HBase 的 Rowkey 是如何设计的》 文章我们已经了解 OpenTSDB 底层的 HBase Rowkey 是如何设计的了。我们现在来测试一下 OpenTSDB 导入的时序数据到底长什么样子。在 OpenTSDB 里面默认存时序数据的表为 tsdb。前面说了,每个指标名称、标签名称以及标签值都有唯一的编码,这些编码数据是存放在 tsdb-uid 表里面。为了更加 7年前 (2018-11-16) 3044℃ 3评论6喜欢
OpenTSDB 是基于 HBase 的可扩展、开源时间序列数据库(Time Series Database),可以用于存储监控数据、物联网传感器、金融K线等带有时间的数据。它的特点是能够提供最高毫秒级精度的时间序列数据存储,能够长久保存原始数据并且不失精度。它拥有很强的数据写入能力,支持大并发的数据写入,并且拥有可无限水平扩展的存储容量。目 7年前 (2018-11-15) 5211℃ 1评论10喜欢
到目前为止,Scala 环境下至少存在6种 Json 解析的类库,这里面不包括 Java 语言实现的 Json 类库。所有这些库都有一个非常相似的抽象语法树(AST)。而 json4s 项目旨在提供一个单一的 AST 树供其他 Scala 类库来使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopjson4s 的使用非常的简单,它可以将 7年前 (2018-11-15) 1144℃ 0评论4喜欢
美国时间 2018年11月08日 正式发布了。一如既往,为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.4 带来了许多新功能,如下:添加一种支持屏障模式(barrier mode)的调度器,以便与基于MPI的程序更好地集成,例如, 分布式深度学习框架;引入了许多内置的高阶函数,以便更容易处理复杂的数据类型(比如数组和 map); 7年前 (2018-11-10) 4574℃ 0评论6喜欢
Apache Spark 2.4 与昨天正式发布,Apache Spark 2.4 版本是 2.x 系列的第五个版本。 如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Spark 2.4 为我们带来了众多的主要功能和增强功能,主要如下:新的调度模型(Barrier Scheduling),使用户能够将分布式深度学习训练恰当地嵌入到 Spark 的 stage 中 7年前 (2018-11-09) 3395℃ 0评论1喜欢
背景随着 Apache HBase 在各个领域的广泛应用,在 HBase 运维或应用的过程中我们可能会遇到这样的问题:同一个 HBase 集群使用的用户越来越多,不同用户之间的读写或者不同表的 compaction、region splits 操作可能对其他用户或表产生了影响。将所有业务的表都存放在一个集群的好处是可以很好的利用整个集群的资源,只需要一套运 7年前 (2018-11-01) 6606℃ 4评论13喜欢
最近突然收到线上服务器发出来的磁盘满了的报警,然后到服务器上发现 Apache Spark 的历史服务器(HistoryServer)日志居然占了近 500GB,如下所示:[code lang="bash"][root@iteblog.com spark]# ll -htotal 328-rw-rw-r-- 1 spark spark 15.4G Jul 11 13:09 spark-spark-org.apache.spark.deploy.history.HistoryServer-1-iteblog.com.out-rw-rw-r-- 1 spark spark 369M May 30 09:07 spark-spark-org.a 7年前 (2018-10-29) 2267℃ 0评论2喜欢
本文来自于2018年10月20日由中国 HBase 技术社区在武汉举办的中国 HBase Meetup 第六次线下交流会。分享者为过往记忆。本文 PPT 下载 请关注 iteblog_hadoop 微信公众号,并回复 HBase 获取。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoop本次分享的内容主要分为以下五点:HBase基本知识;HBase读 7年前 (2018-10-25) 6479℃ 0评论23喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 7年前 (2018-10-17) 1321℃ 0评论1喜欢
为期三天的 Spark+AI Summit Europe 于 2018-10-02 ~ 04 在伦敦举行,一如往前,本次会议包含大量 AI 相关的议题,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark+AI Summit Europe 2018 吸引了全球大量技术大咖参会,本次会议议题超过了140多个。会议的全部日程请参见:https://databricks.com/sparkaisummit/europe/schedule。注意 7年前 (2018-10-13) 3538℃ 1评论8喜欢






![Spark+AI Summit Europe 2018 PPT下载[共95个]](https://www.iteblog.com/pic/spark/Spark_ai_summit_europe_2018-iteblog.png)