Flink China社区线下 Meetup·上海站会议于 2018年7月29日 在上海市杨浦区政学路77号INNOSPACE进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动议程14:00-14:10 大沙 出品人开场发言14:10-14:40 阿里 巴真 《阿里在Flink的优化和改进分享》14:40-15:10 唯品会 王新春 《Flink在唯品会的实践》详细 7年前 (2018-08-13) 2340℃ 0评论5喜欢
为期两个月开发的 Apache Flink 1.6.0 于今天(2018-08-09)正式发布了。Flink 社区艰难地解决了 360 个 issues,到这里查看完整版的 changelog 。Flink 1.6.0 是 1.x.y 版本系列上的第七个版本,1.x.y 中所有使用 @Public 标注的 API 都是兼容的。此版本继续使 Flink 用户能够无缝地运行快速数据处理并轻松构建数据驱动和数据密集型应用程序。Apache Fli 7年前 (2018-08-09) 1996℃ 0评论10喜欢
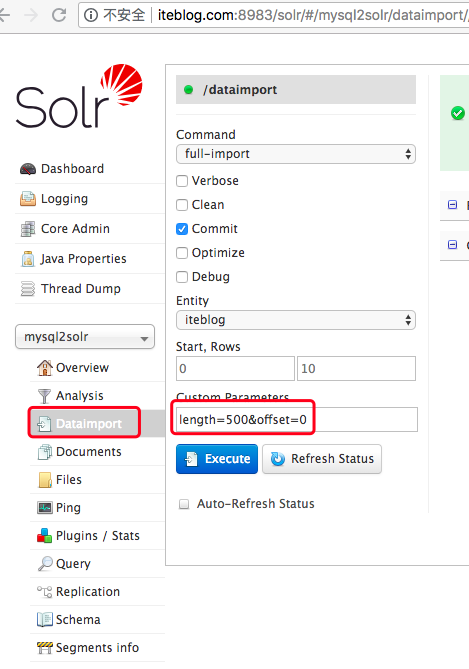
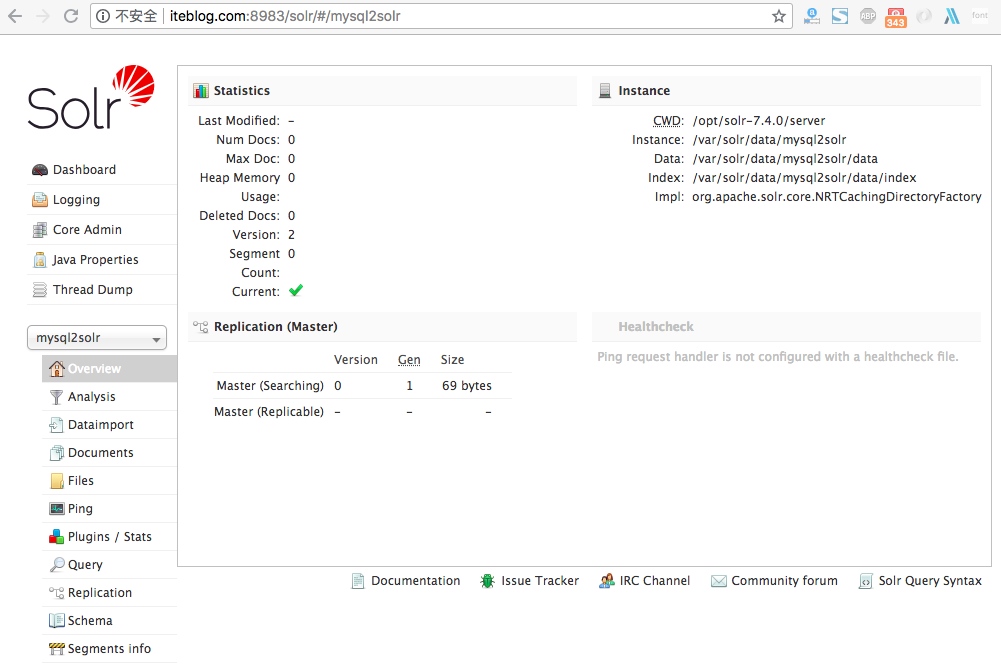
在 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章中介绍了如何将 MySQL 中的全量数据导入到 Solr 中。里面提到一个问题,那就是如果数据量很大的时候,一次性导入数据可能会影响 MySQL ,这种情况下能不能分页导入呢?答案是肯定的,本文将介绍如何通过分页的方式将 MySQL 里面的数据导入到 Solr。分页导数的方法和全量导大部 7年前 (2018-08-07) 1521℃ 0评论1喜欢
如果你正在按照 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章介绍的步骤来将 MySQL 里面的数据导入到 Solr 中,但是在创建 Core/Collection 的时候出现了以下的异常[code lang="bash"]2018-08-02 07:56:17.527 INFO (qtp817348612-15) [ x:mysql2solr] o.a.s.m.r.SolrJmxReporter Closing reporter [org.apache.solr.metrics.reporters.SolrJmxReporter@47d9861c: rootName = null, domain = solr.cor 7年前 (2018-08-07) 1099℃ 0评论2喜欢
关于分页方式导入全量数据请参照《将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中》。在前面几篇文章中我们介绍了如何通过 Solr 的 post 命令将各种各样的文件导入到已经创建好的 Core 或 Collection 中。但有时候我们需要的数据并不在文件里面,而是在别的系统中,比如 MySql 里面。不过高兴的是,Solr 针对这些数据也提供了 7年前 (2018-08-06) 2017℃ 0评论2喜欢
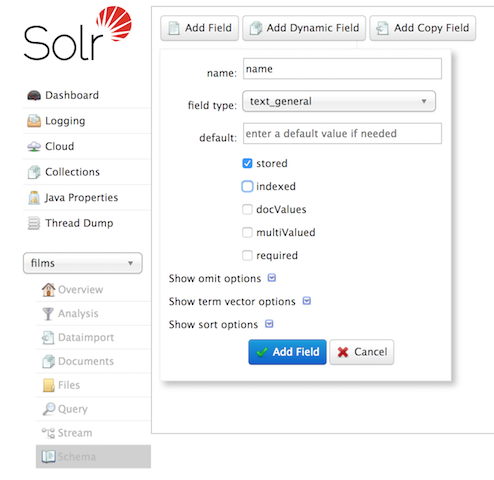
到目前为止,我们往 Solr 里面导数据都没有定义模式,也就是说让 Solr 去猜我们数据的类型以及解析方式,这种方式成为无模式(Schemaless)。Apache Solr 里面的定义为:One reason for this is we’re going to use a feature in Solr called "field guessing", where Solr attempts to guess what type of data is in a field while it’s indexing it. It also automatically creates new fields in th 7年前 (2018-08-01) 1760℃ 0评论4喜欢
Apache Kafka 2.0.0 在昨天正式发布了,其包含了许多重要的特性,这里我列举了一些比较重要的:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop增加了前缀通配符访问控制(ACL)的支持,详见 KIP-290,这样我们可以更加细粒度的进行访问控制;更全面的数据安全支持,KIP-255 里面添加了一个框架, 7年前 (2018-07-31) 3998℃ 0评论6喜欢
在 《Apache Solr 安装部署及索引创建》 文章里面我创建了一个名为 iteblog 的 core,并在里面导入了一些测试数据,然后在 《使用 Apache Solr 检索数据》 里面介绍了 Solr 中一些简单的查询。可能有同学按照上面文章介绍,在使用下面的查询发现啥都查不到:[code lang="bash"][root@iteblog.com /opt/solr-7.4.0]$ curl http://iteblog.com:8983/solr/iteblog/select 7年前 (2018-07-27) 1560℃ 0评论4喜欢
在 《Apache Solr 安装部署及索引创建》 文章中,我们搭建好一个单机版的 Solr 服务,并创建好一个名为 iteblog 的 core,iteblog 的索引数据是存放在 instanceDir 参数的 data 目录下。这会有以下几个问题:如果索引数据很大,可能本地的文件夹无法存储索引数据存放在本地,可能会导致索引数据丢失等幸运的是,Solr 支持将索引和事 7年前 (2018-07-25) 1853℃ 0评论4喜欢
在《Apache Solr 介绍及安装部署》 文章里面我简单地介绍了如何在 Linux 平台搭建单机版的 Solr 服务,而且我们已经创建了一个名为 iteblog 的 core,已经导入了相关的索引数据,接下来让我们来使用 Solr 检索这些数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop查询所有的数据可以使用 *:* 7年前 (2018-07-24) 1504℃ 0评论4喜欢