在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 7年前 (2018-03-28) 5379℃ 3评论24喜欢
我们知道,Zookeeper 会将所有事务操作的数据记录到日志文件中,这个文件的存储路径可以通过 dataLogDir 参数配置。在写数据之前,Zookeeper 会采用磁盘空间预分配策略;磁盘空间预分配策略主要有以下几点好处:可以让文件尽可能的占用连续的磁盘扇区,减少后续写入和读取文件时的磁盘寻道开销;迅速占用磁盘空间,防止使用 7年前 (2018-03-23) 2114℃ 0评论5喜欢
原文名:Paxos Made Simple [PDF下载] Leslie Lamport 2001/11/01翻译:phylipsbmy 原译文链接: http://duanple.blog.163.com/blog/static/709717672011440267333/审校:Jerry Lee oldratlee<at>gmail<dot>com译序“在PODC2001会议上,我总是听到人们在抱怨Paxos算法是那么的难以理解。人们总是被那些古希腊的名称弄得晕头转向,而使得他们觉得论文难以理解 7年前 (2018-03-12) 3763℃ 0评论9喜欢
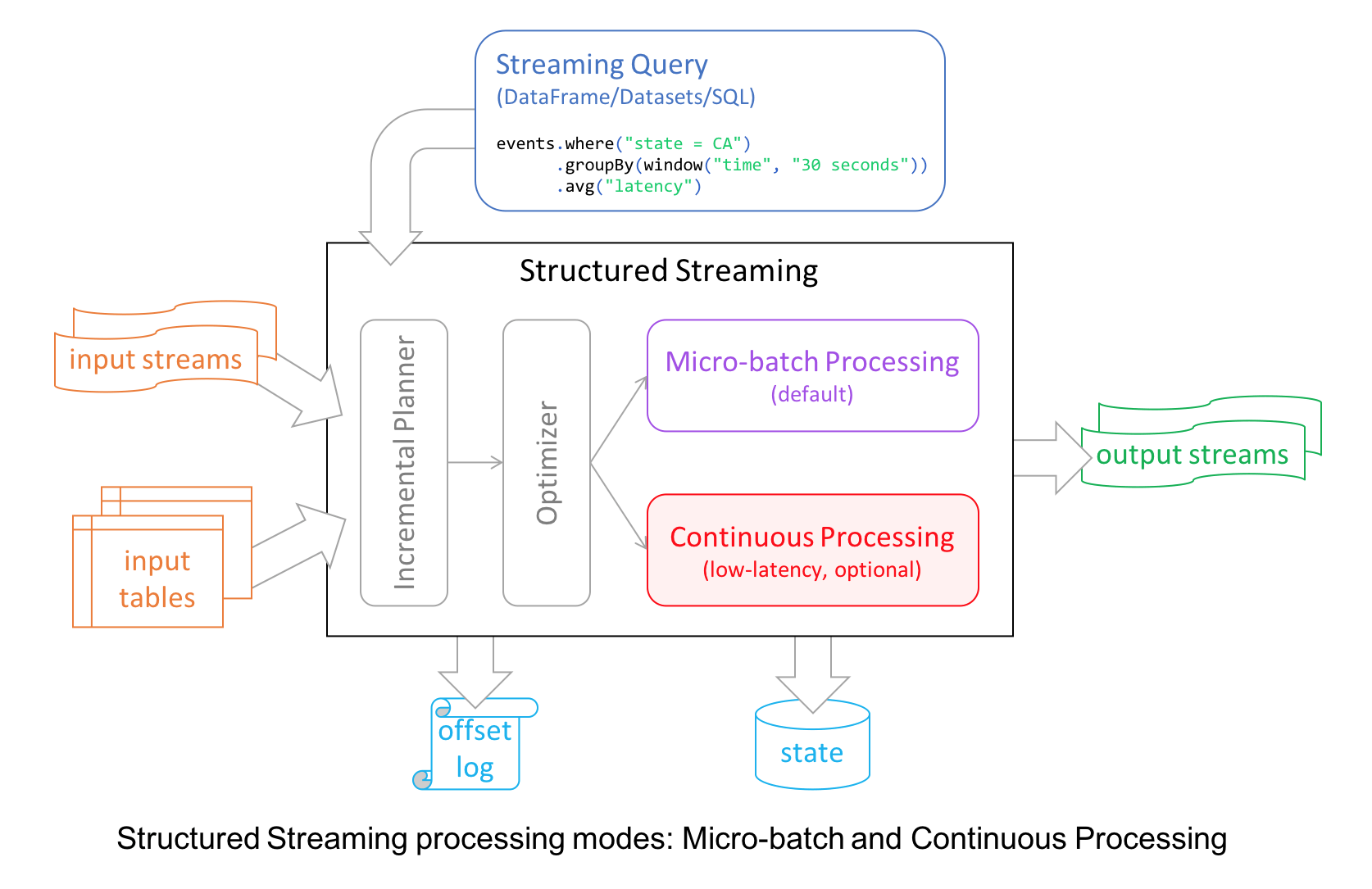
本文翻译自:Introducing Apache Spark 2.3为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas UDFs 的性能来提升 PySpark;支持第四种调度引擎 Kubernetes clusters(其他三种分别是自带的独立模式St 7年前 (2018-03-01) 7346℃ 3评论32喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop一个Spark Streaming读取Kafka 7年前 (2018-02-28) 6758℃ 0评论13喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u 7年前 (2018-02-14) 15078℃ 0评论21喜欢
CarbonData是一种高性能大数据存储方案,支持快速过滤查找和即席OLAP分析,已在20+企业生产环境上部署应用,其中最大的单一集群数据规模达到几万亿。针对当前大数据领域分析场景需求各异而导致的存储冗余问题,业务驱动下的数据分析灵活性要求越来越高,CarbonData提供了一种新的融合数据存储方案,以一份数据同时支持多种应 7年前 (2018-02-09) 1837℃ 0评论13喜欢
数据库事业部承载着阿里巴巴及阿里云的数据库服务,为超过数万家中国企业提供专业的数据库服务。我们提供在线事务处理、缓存文档服务、BigData NoSQL服务 、在线分析处理的全栈数据库产品。本团队提供基于Apache HBase\Phoenix\Spark\Cassandra\Solr\ES等,结合自研技术,打造存储、检索、计算的一站式的BigData NoSQL自主可控的服务,满足客 7年前 (2018-01-30) 6491℃ 1评论28喜欢
经过几个星期的开发,本博客微信小程序(过往记忆大数据技术博客)正式上线了!至此大家可以通过微信公众号、微信小程序等方式访问本博客了。下面来看看本博客微信公众号的一些预览:微信小程序首页在首页可以查看本博客最新的文章,热门文章以及搜索等。文章页文章页可以文章的详情,功 7年前 (2018-01-28) 2039℃ 0评论7喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 7年前 (2018-01-25) 6595℃ 3评论23喜欢