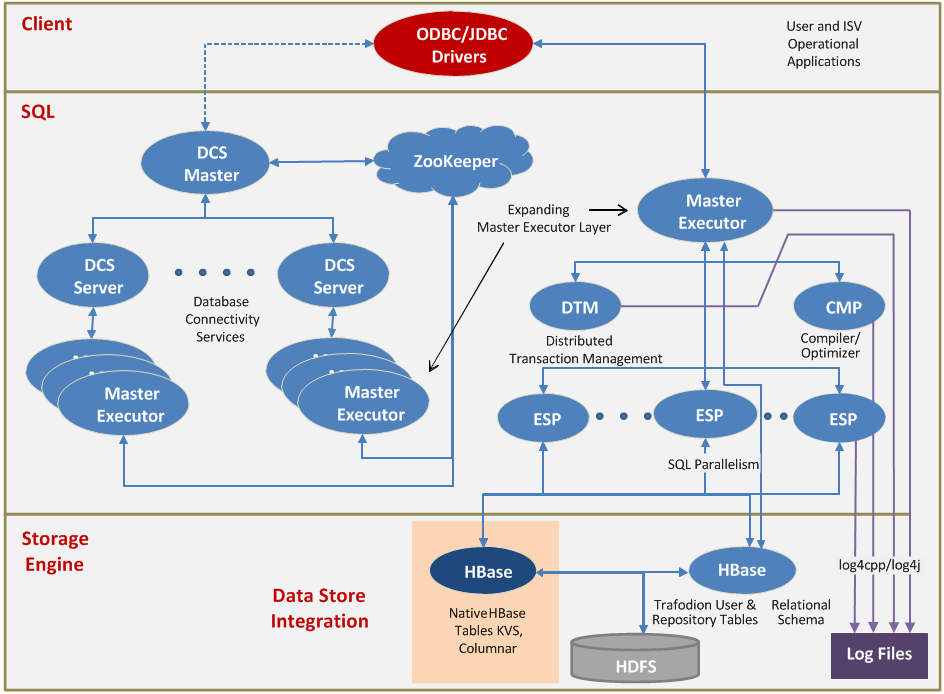
Apache Trafodion 是由惠普开发并开源的基于 Hadoop 平台的事务数据库引擎。提供了一个基于Hadoop平台的交易型SQL引擎。它是一个擅长处理交易型负载的Hadoop大数据解决方案。其主要特性包括:完整的ANSI SQL语言支持完整的ACID事务支持。对于读、写查询,Trafodion支持跨行,跨表和跨语句的事务保护支持多种异构存储引擎的直接访问为应 7年前 (2018-01-07) 2432℃ 0评论5喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的 7年前 (2018-01-01) 3549℃ 0评论10喜欢
有时候我们想对来自不同平台对同一页面的访问进行处理。比如访问 https://www.iteblog.com/test.html 页面,如果是电脑的浏览器访问,直接不处理;但是如果是手机的浏览器访问这个页面我们想跳转到其他页面去。这时候有几种方法可以实现:直接通过 JavaScript 进行处理;通过 Nginx 配置来处理如果想及时了解Spark、Hadoop或者Hbase 7年前 (2017-12-16) 1822℃ 0评论13喜欢
今天凌晨 Apache Hadoop 3.0.0 GA 版本正式发布,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!这个版本是 Apache Hadoop 3.0.0 的第一个稳定版本,有很多重大的改进,比如支持 EC、支持多于2个的NameNodes、Intra-datanode均衡器等等。下面是关于 Apache Hadoop 3.0.0 GA 的正式介绍。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 7年前 (2017-12-15) 3505℃ 1评论38喜欢
Apache Spark 2.2.0 于今年7月份正式发布,这个版本是 Structured Streaming 的一个重要里程碑,因为其可以正式在生产环境中使用,实验标签(experimental tag)已经被移除; CBO (Cost-Based Optimizer)有了进一步的优化;SQL完全支持 SQL-2003 标准;R 中引入了新的分布式机器学习算法;MLlib 和 GraphX 中添加了新的算法更多详情请参见:Apa 7年前 (2017-12-13) 2689℃ 0评论19喜欢
Flink 是一种非常复杂的框架,它提供了多种调整其执行的方法。本文将介绍四种不同的方法来提升你的 Flink 应用程序的性能。使用 Flink Tuples当你使用类似于 groupBy, join, 或者 keyBy 算子时,Flink 提供了多种用于在你的数据集上选择 key 的方法。你可以使用 key 选择函数,如下:[code lang="java"]// Join movies and ratings datasetsmovies.join 7年前 (2017-12-10) 5366℃ 0评论16喜欢
TPCH(商业智能计算测试) 是美国交易处理效能委员会(TPC,Transaction Processing Performance Council) 组织制定的用来模拟决策支持类应用的一个测试集。目前在学术界和工业界普遍采用它来评价决策支持技术方面应用的性能。这种商业测试可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义, 7年前 (2017-12-10) 687℃ 0评论1喜欢
本文系奇虎360系统部相关工程师投稿。近两年人工智能技术发展迅速,以Google开源的TensorFlow为代表的各种深度学习框架层出不穷。为了方便算法工程师使用各类深度学习技术,减少繁杂的诸如运行环境部署运维等工作,提升GPU等硬件资源利用率,节省硬件投入成本,奇虎360系统部大数据团队与人工智能研究院联合开发了深度学习 7年前 (2017-12-08) 2786℃ 0评论15喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 7年前 (2017-12-05) 3027℃ 0评论18喜欢
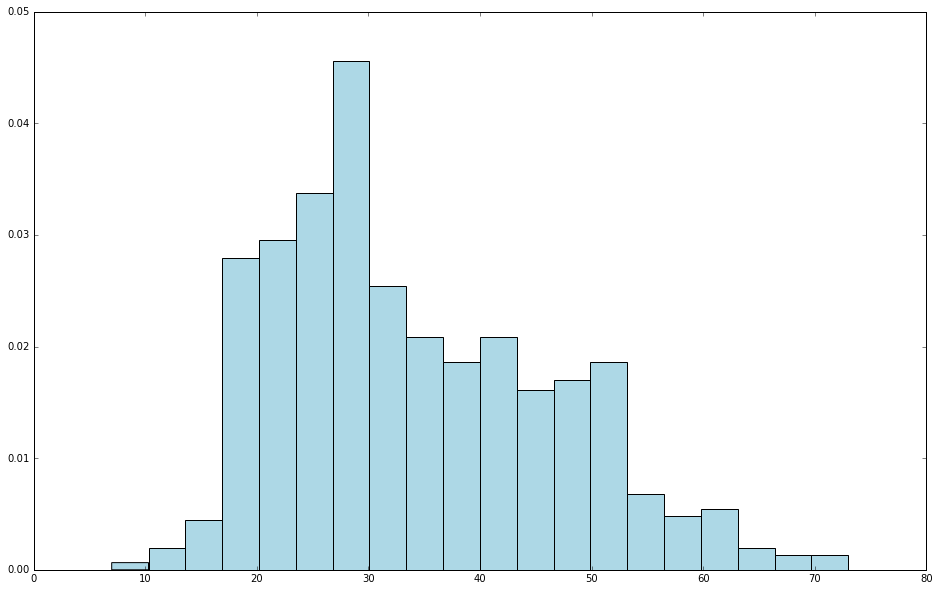
最近在使用 Python 学习 Spark,使用了 jupyter notebook,期间使用到 hist 来绘图,代码很简单如下:[code lang="python"]user_data = sc.textFile("/home/iteblog/ml-100k/u.user")user_fields = user_data.map(lambda line: line.split("|"))ages = user_fields.map(lambda x: int(x[1])).collect()hist(ages, bins=20, color='lightblue', normed=True)fig = matplotlib.pyplot.gcf()fig.set_size_inch 7年前 (2017-12-04) 4698℃ 0评论19喜欢