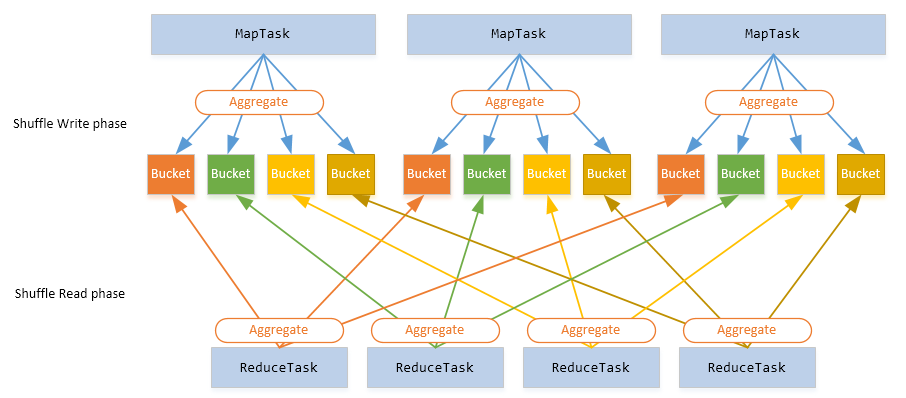
Spark Shuffle 基础在 MapReduce 框架中,Shuffle 是连接 Map 和 Reduce 之间的桥梁,Reduce 要读取到 Map 的输出必须要经过 Shuffle 这个环节;而 Reduce 和 Map 过程通常不在一台节点,这意味着 Shuffle 阶段通常需要跨网络以及一些磁盘的读写操作,因此 Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。与 MapReduce 计算框架一样,Spark 作 8年前 (2017-11-15) 7551℃ 3评论30喜欢
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 8年前 (2017-11-13) 10597℃ 0评论24喜欢
本文总结了几个本人在使用 Carbondata 的时候遇到的几个问题及其解决办法。这里使用的环境是:Spark 2.1.0、Carbondata 1.2.0。必须指定 HDFS nameservices在初始化 CarbonSession 的时候,如果不指定 HDFS nameservices,在数据导入是没啥问题的;但是数据查询会出现相关数据找不到问题:[code lang="scala"]scala> val carbon = SparkSession.builder().temp 8年前 (2017-11-09) 6709℃ 5评论14喜欢
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 8年前 (2017-11-05) 25878℃ 0评论17喜欢
Spark Summit 2017 Europe 于2017-10-24 至 26在柏林进行,本次会议议题超过了70多个,会议的全部日程请参见:https://spark-summit.org/eu-2017/schedule/。本次议题主要包括:开发、研究、机器学习、流计算等领域。从这次会议可以看出,当前 Spark 发展两大方向:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spar 8年前 (2017-11-02) 3592℃ 0评论13喜欢
背景介绍本项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询。原实现基于 Oracle 提供存储查询服务,随着数据量的不断增加,在写入和读取过程中面临性能问题,且历史数据仅供业务查询参考,并不影响实际流程,从系统结构上来说,放在业务链条上游比较重。 8年前 (2017-10-28) 2731℃ 0评论7喜欢
MMLSpark为Apache Spark提供了大量深度学习和数据科学工具,包括将Spark Machine Learning管道与Microsoft Cognitive Toolkit(CNTK)和OpenCV进行无缝集成,使您能够快速创建功能强大,高度可扩展的大型图像和文本数据集分析预测模型。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopMMLSpark需要Scala 2.11,Spark 2 8年前 (2017-10-24) 4257℃ 0评论9喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 8年前 (2017-10-11) 2274℃ 0评论15喜欢
我在《在Kafka中使用Avro编码消息:Producter篇》文章中简单介绍了如何发送 Avro 类型的消息到 Kafka。本文接着上文介绍如何从 Kafka 读取 Avro 格式的消息。关于 Avro 我这就不再介绍了。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从 Kafka 中读取 Avro 格式的消息从 Kafka 中读取 Avro 格式的消 8年前 (2017-09-25) 6517℃ 0评论16喜欢
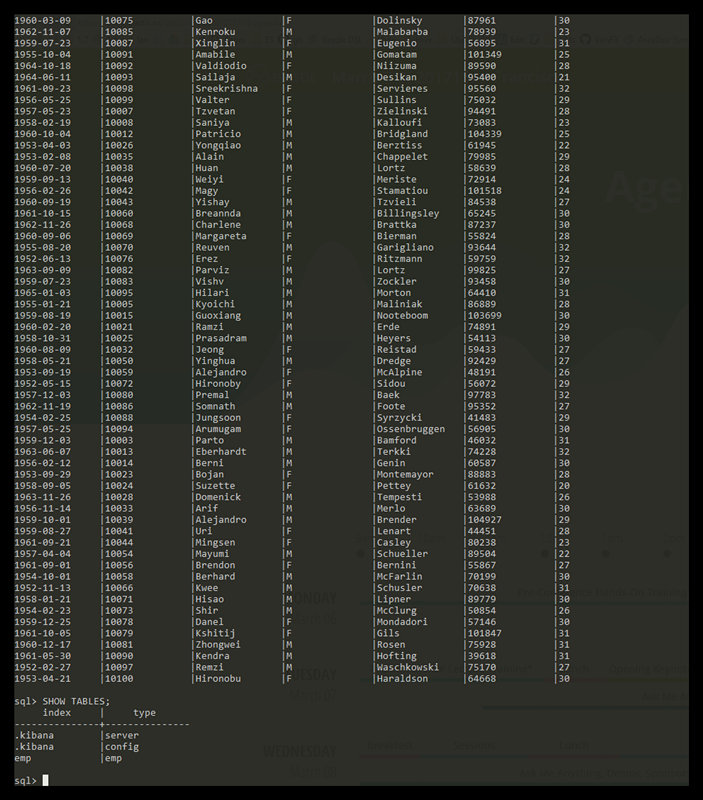
告诉大家一件好消息:ElasticSearch官方正在开发SQL功能模块,也就是说未来版本(不是 6.x 就是 7.x)的Elasticsearch内置就支持SQL特性了!这样我们就不需要安装 NLPchina/elasticsearch-sql 插件。这个SQL模块是属于X-Pack的一部分。首先默认提供了一个 CLI 工具,可以很方便的执行 SQL 查询。如下图如果想及时了解Spark、Hadoop或者Hbase相关的 8年前 (2017-09-06) 3107℃ 0评论14喜欢



![Spark Summit 2017 Europe全部PPT及视频下载[共69个]](https://www.iteblog.com/pic/spark/spark-summit-2017-europe-iteblog.png)