越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Flink 非常 8年前 (2017-07-20) 3560℃ 0评论16喜欢
Apache Spark 2.2.0 经过了大半年的紧张开发,从RC1到RC6终于在今天正式发布了。由于时间的缘故,我并没有在《Apache Spark 2.2.0正式发布》文章中过多地介绍 Apache Spark 2.2.0 的新特性,本文作为补充将详细介绍Apache Spark 2.2.0 的新特性。这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(ex 8年前 (2017-07-12) 9355℃ 0评论28喜欢
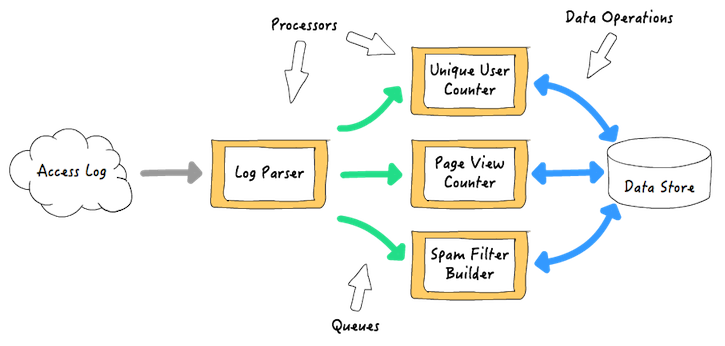
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 8年前 (2017-07-12) 603℃ 0评论0喜欢
关于 Apache Spark 2.2.0 的详细新功能介绍请参见:《Apache Spark 2.2.0新特性详细介绍》Apache Spark 2.2.0 持续了半年的开发,从RC1 到 RC6 终于在今天正式发布了。本版本是 2.x 版本线的第三个版本。在这个版本 Structured Streaming 的实验性标记(experimental tag)已经被移除,这也意味着后面的 2.2.x 之后就可以放心在线上使用了。除此之外,这 8年前 (2017-07-12) 2899℃ 0评论8喜欢
从Apache Zeppelin 0.5.6 版本开始,内置支持 Elasticsearch Interpreter了。我们可以直接在Apache Zeppelin中查询 ElasticSearch 中的数据。但是默认的 Apache Zeppelin 发行版本中可能并没有包含 Elasticsearch Interpreter。这种情况下我们需要自己安装。如果你参照了官方的这篇文档,即使你全部看完这篇文档,也是无法按照上面的说明启用 Elasticsearch Interpre 8年前 (2017-07-05) 1915℃ 0评论5喜欢
大家在使用Spark、MapReduce 或 Flink 的时候很可能遇到这样一种情况:Hadoop 集群使用的 JDK 版本为1.7.x,而我们自己编写的程序由于某些原因必须使用 1.7 以上版本的JDK,这时候如果我们直接使用 JDK 1.8、或 1.9 来编译我们写好的代码,然后直接提交到 YARN 上运行,这时候会遇到以下的异常:[code lang="java"]Exception in thread "main" jav 8年前 (2017-07-04) 5497℃ 1评论16喜欢
问题我们应该知道,Hive中存在两种类型的表:管理表(Managed table,又称Internal tables)和外部表(External tables),详情请参见《Hive表与外部表》。在公司内,特别是部门之间合作,很可能会通过 HDFS 共享一些 Hive 表数据,这时候我们一般都是参见外部表。比如我们有一个共享目录:/user/iteblog_hadoop/order_info,然后我们需要创建一个 8年前 (2017-06-27) 4949℃ 1评论16喜欢
在之前的博文《Scala正则表达式》我简单地介绍了如何在Scala中使用正则表达式来匹配一些我们需要的内容。本篇文章将接着此文继续简单介绍如何使用Scala来匹配出我们需要的字符串,然后使用某种规则来替换匹配出来的字符串。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop简单正则表 8年前 (2017-06-26) 8478℃ 0评论15喜欢
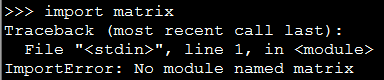
有时候我们会自己编写一些 Python 内置中没有的 module ,比如下面我自定义了一个名为 matrix 的 module ,然后直接在命令行中引入则会出现下面的错误:[code lang="python"][iteblog@www.iteblog.com ~]$ pythonPython 2.7.3 (default, Aug 4 2016, 21:49:57) [GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2Type "help", "copyright", "credits" or "license& 8年前 (2017-06-25) 58112℃ 0评论14喜欢
如果你使用Apache Spark解决了中等规模数据的问题,但是在海量数据使用Spark的时候还是会遇到各种问题。High Performance Spark将会向你展示如何使用Spark的高级功能,所以你可以超越新手级别。本书适合软件工程师、数据工程师、开发者以及Spark系统管理员的使用。本书全名High Performance Spark:Best Practices for Scaling and Optimizing Apache Spark,作 8年前 (2017-06-23) 10716℃ 0评论19喜欢




![[电子书]High Performance Spark完整版PDF下载](https://www.iteblog.com/pic/books/High_Performance_Spark_iteblog.jpg)