Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。Apache Beam的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。此项 8年前 (2017-04-14) 2602℃ 0评论6喜欢
最近几年关于Apache Spark框架的声音是越来越多,而且慢慢地成为大数据领域的主流系统。最近几年Apache Spark和Apache Hadoop的Google趋势可以证明这一点:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop上图已经明显展示出最近五年,Apache Spark越来越受开发者们的欢迎,大家通过Google搜索更多关 8年前 (2017-04-12) 6717℃ 0评论46喜欢
时隔两年,Apache Hadoop终于又有大改版,Apache基金会近日发布了Hadoop 2.8版,一次新增了2,919项更新功能或新特色。不过,Hadoop官网建议,2.8.0仍有少数功能在测试,要等到释出2.8.1或是2.8.2版才适合用于正式环境。在2.8.0版众多更新,主要分布于4大套件分别是:共用套件(Common)底层分散式档案系统HDFS套件(HDFS)MapReduce运算 8年前 (2017-03-31) 2849℃ 2评论17喜欢
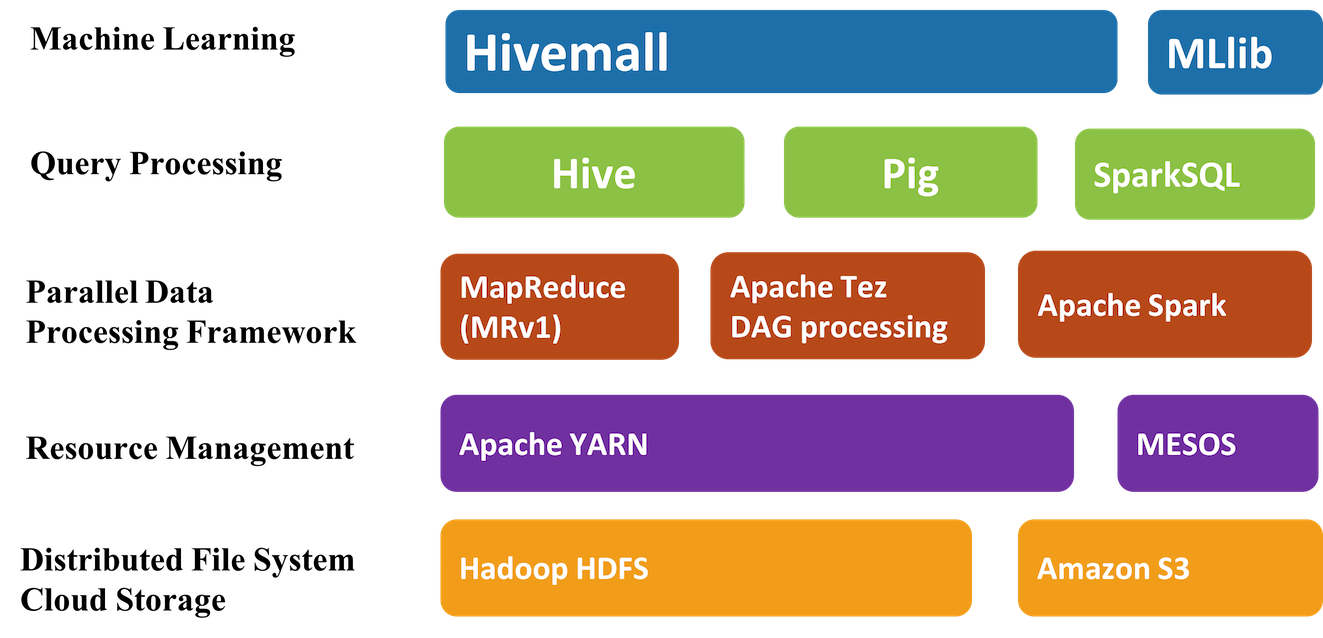
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( 8年前 (2017-03-29) 3522℃ 1评论10喜欢
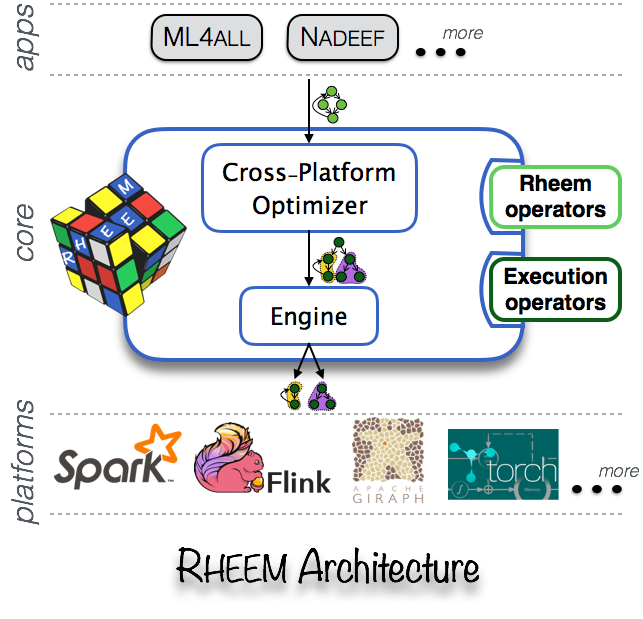
RHEEM是一个可扩展且易于使用的跨平台大数据分析系统,它在现有的数据处理平台之上提供了一个抽象。它允许用户使用易于使用的编程接口轻松地编写数据分析任务,为开发者提供了不同的方式进行性能优化,编写好的程序可以在任意数据处理平台上运行,这其中包括:PostgreSQL, Spark, Hadoop MapReduce或者Flink等;Rheem将选择经典 8年前 (2017-03-23) 1093℃ 0评论3喜欢
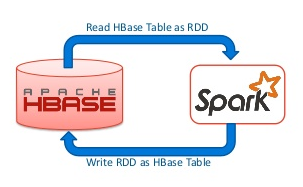
在使用Spark操作Hbase的时候,其返回的数据类型是RDD[ImmutableBytesWritable,Result],我们可能会对这个结果进行其他的操作,比如join等,但是因为org.apache.hadoop.hbase.io.ImmutableBytesWritable 和 org.apache.hadoop.hbase.client.Result 并没有实现 java.io.Serializable 接口,程序在运行的过程中可能发生以下的异常:[code lang="bash"]Serialization stack: - object not ser 8年前 (2017-03-23) 5485℃ 1评论13喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 8年前 (2017-03-21) 10050℃ 0评论15喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer,从而充分利用 Hadoop 并行计算框架的优势和能力,来处理大数据。而我们在官方文档或者是Hadoop权威指南看到的Hadoop Streaming例子都是使用 Ruby 或者 Python 编写的,官方说可以使用任何可执行文件 8年前 (2017-03-14) 2751℃ 0评论2喜欢
在Flink中有许多函数需要我们为其指定key,比如groupBy,Join中的where等。如果我们指定的Key不对,可能会出现一些问题,正如下面的程序:[code lang="scala"]package com.iteblog.flinkimport org.apache.flink.api.scala.{ExecutionEnvironment, _}import org.apache.flink.util.Collector///////////////////////////////////////////////////////////////////// User: 过往记忆 Date: 2017 8年前 (2017-03-13) 16970℃ 9评论15喜欢
第十二次Shanghai Apache Spark Meetup聚会,由Splunk中国大力支持。活动将于2017年03月18日12:30~16:45在上海淞沪路303号901 (大学路智星路路口汇丰银行楼9楼)Splunk 中国进行。 举办地点交通方便,靠近地铁10号线江湾体育场站,座位有限(大约120),先到先得,速速行动啊。大会主题《利用Spark开发高并发,高可靠的分布式大数据采集调 8年前 (2017-03-09) 1463℃ 0评论2喜欢