此次活动参与方式:关注iteblog_hadoop公众号,并在这里评论区留言(认真写评论,增加上榜的机会)。活动截止至3月14日19:00,留言点赞数排名前5名的粉丝,各免费赠送一本《Druid实时大数据分析原理与实践》如果想及时了解Spark、Hadoop、Flink或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书简介Druid 作为一 8年前 (2017-03-08) 1597℃ 0评论5喜欢
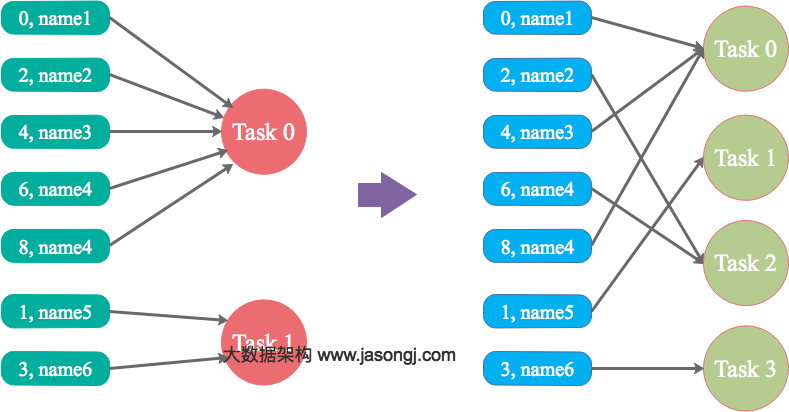
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。为何要处理数据倾斜(Data Skew)什么是数据倾斜对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。何谓数据倾 8年前 (2017-03-07) 13400℃ 2评论27喜欢
在Flink中我们可以很容易的使用内置的API来读取HDFS上的压缩文件,内置支持的压缩格式包括.deflate,.gz, .gzip,.bz2以及.xz等。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是如果我们想使用Flink内置sink API将数据以压缩的格式写入到HDFS上,好像并没有找到有API直接支持(如果不是这样的, 8年前 (2017-03-02) 10420℃ 0评论6喜欢
假设现在的分支名称为 oldName,想要修改为 newName如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本地分支重命名这种情况是你的代码还没有推送到远程,分支只是在本地存在,那直接执行下面的命令即可:[code lang="bash"]git branch -m oldName newName[/code]远程分支重命名 如果你的分支已经推 8年前 (2017-03-02) 754℃ 0评论1喜欢
一直运行的Spark Streaming程序如何关闭呢?是直接使用kill命令强制关闭吗?这种手段是可以达到关闭的目的,但是带来的后果就是可能会导致数据的丢失,因为这时候如果程序正在处理接收到的数据,但是由于接收到kill命令,那它只能停止整个程序,而那些正在处理或者还没有处理的数据可能就会被丢失。那我们咋办?这里有两 8年前 (2017-03-01) 8897℃ 1评论11喜欢
大多数刚刚使用Apache Flink的人很可能在编译写好的程序时遇到如下的错误:[code lang="bash"]Error:(15, 26) could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.TypeInformation[Int] socketStockStream.map(_.toInt).print() ^[/code]如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteb 8年前 (2017-03-01) 4283℃ 9喜欢
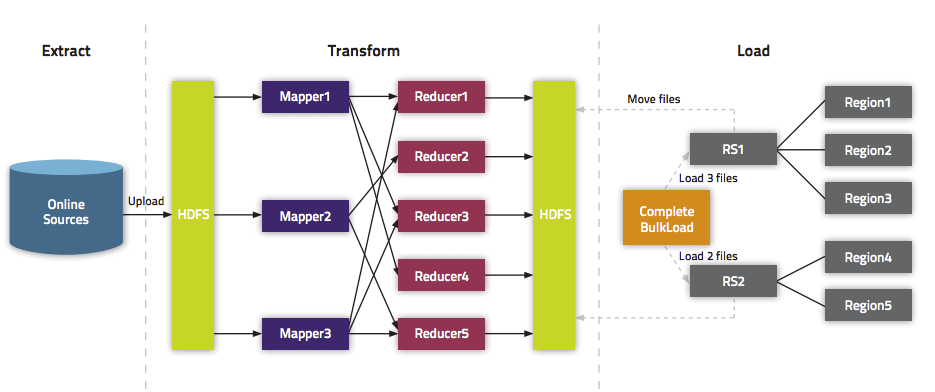
我们在《通过BulkLoad快速将海量数据导入到Hbase[Hadoop篇]》文中介绍了一种快速将海量数据导入Hbase的一种方法,而本文将介绍如何在Spark上使用Scala编写快速导入数据到Hbase中的方法。这里将介绍两种方式:第一种使用Put普通的方法来倒数;第二种使用Bulk Load API。关于为啥需要使用Bulk Load本文就不介绍,更多的请参见《通过BulkLoad快 8年前 (2017-02-28) 15215℃ 1评论40喜欢
Spark SQL从2.0开始已经不再支持ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)这种语法了(下文简称add columns语法)。如果你的Spark项目中用到了SparkSQL+Hive这种模式,从Spark1.x升级到2.x很有可能遇到这个问题。为了解决这个问题,我们一般有3种方案可以选择: 1、启动一个hiveserver2服务,通过jdbc直接调用hive 8年前 (2017-02-27) 3158℃ 0评论5喜欢
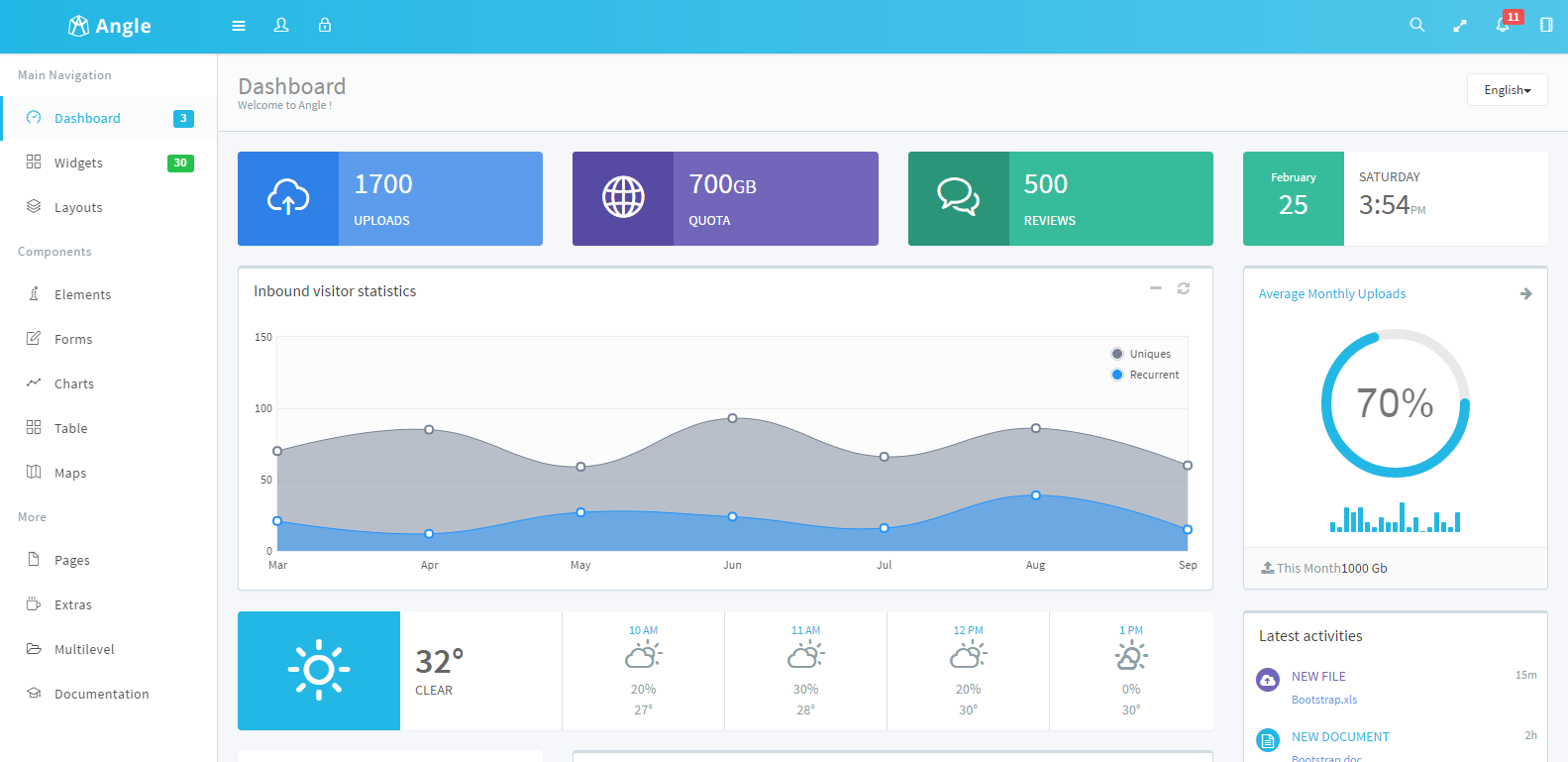
Angle Admin Template是一款后台管理模板,使用Bootstrap3.x作为界面框架,支持响应式布局。Angle包含JQuery和AngularJS两种js框架,方便SPA的使用,并且该模板提供了ASP.NET MVC、Angular、Rails等项目模板以及相应的种子模板,方便使用。点击下载Angle 3.5.4主题 该系列由于界面清爽,插件足够多、代码使用方便,文档齐全(英文), 8年前 (2017-02-25) 3247℃ 0评论16喜欢
在很多场景中我们会使用Shell命令来发送邮件,而且我们还可能在邮件里面添加附件,本文将介绍使用Shell命令发送带附件邮件的几种方式,希望对大家有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop使用mail命令mail命令是mailutils(On Debian)或mailx(On RedHat)包中的一部分,我们可以使 8年前 (2017-02-23) 16545℃ 0评论12喜欢