流处理系统月刊是一份专门收集关于Spark、Flink、Kafka、Apex等流处理系统的技术干货月刊,完全免费,每天更新,欢迎关注。下面资源如无法正常访问,请使用《最新可访问Google的Hosts文件》进行科学上网。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop#iteblog a:link { text-decoration: underline;}#it 9年前 (2016-10-06) 2690℃ 0评论4喜欢
今天凌晨(2016-10-05)Apache Spark 2.0.1稳定版正式发布。Apache Spark 2.0.1是一个维护版本,一共处理了300个Issues,推荐所有使用Spark 2.0.0的用户升级到此版本。Apache Spark 2.0为我们带来了许多新的功能: DataFrame和Dataset统一(可以参见《Spark 2.0技术预览:更容易、更快速、更智能》):https://www.iteblog.com/archives/1668.html SparkSession:一个 9年前 (2016-10-05) 3190℃ 0评论7喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第五篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 9年前 (2016-10-02) 5964℃ 0评论3喜欢
本博客曾经介绍了《如何手动添加依赖的jar文件到本地Maven仓库》这里的方法非常的简单,而且局限性很大:只能提供给本人开发使用,无法共享给其他需要的人。本文将介绍如何把自己开发出来的Java包发布到Maven中央仓库(http://search.maven.org/),这样任何人都可以搜索到这个包并使用它。如果你现在还不了解Maven是啥东西,请你 9年前 (2016-09-27) 9813℃ 2评论23喜欢
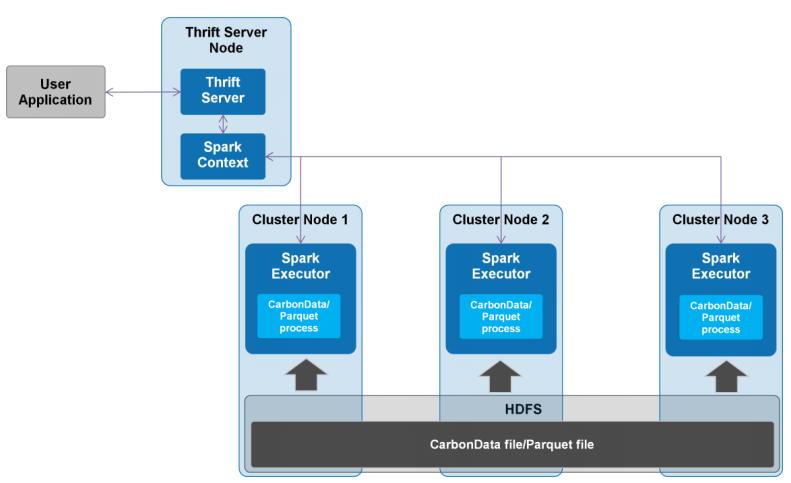
本文相关测试数据由华为陈亮大神提供,特别感谢。 Apache CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询,目前该项目正处于Apache孵化过程中。详细介绍可以参见(《CarbonData:华为开发并支持Hadoop的 9年前 (2016-09-11) 8313℃ 1评论7喜欢
这是许多kafka使用者经常会问到的一个问题。本文的目的是介绍与本问题相关的一些重要决策因素,并提供一些简单的计算公式。越多的分区可以提供更高的吞吐量 首先我们需要明白以下事实:在kafka中,单个patition是kafka并行操作的最小单元。在producer和broker端,向每一个分区写入数据是可以完全并行化的,此时,可 9年前 (2016-09-08) 10354℃ 2评论22喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第四篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 9年前 (2016-09-04) 7518℃ 0评论8喜欢
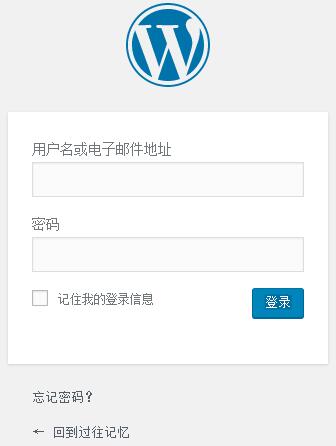
默认情况下,使用WordPress系统的博客登录页面都比较简单,登陆页面显示的logo是WordPress 的logo,链接也是WordPress的链接,如下图所示:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 值得高兴的是,WordPress博客系统为我们提供了很多钩子(hook)来自定义这些信息,比如Logo、链接、提 9年前 (2016-09-03) 1933℃ 0评论6喜欢
使用MapReduce解决任何问题之前,我们需要考虑如何设计。并不是任何时候都需要map和reduce job。MapReduce设计模式(MapReduce Design Pattern)整个MapReduce作业的阶段主要可以分为以下四种: 1、Input-Map-Reduce-Output 2、Input-Map-Output 3、Input-Multiple Maps-Reduce-Output 4、Input-Map-Combiner-Reduce-Output下面我将一一介绍哪种 9年前 (2016-09-01) 5779℃ 0评论16喜欢
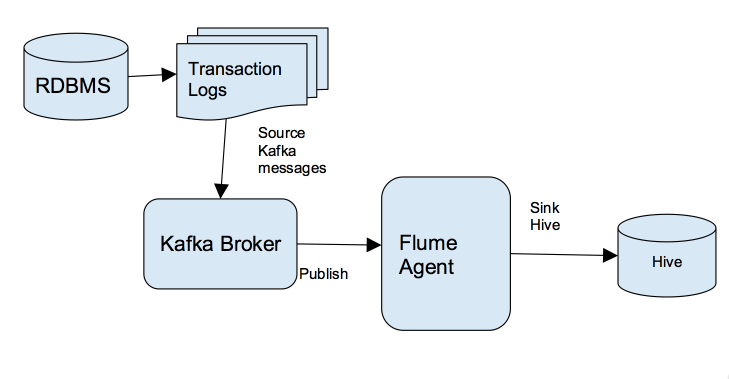
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 9年前 (2016-08-30) 11533℃ 6评论26喜欢