本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第一篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 9年前 (2016-08-15) 12556℃ 2评论10喜欢
有一种非常常见的场景那就是使用其他数据库作为主要的数据存储,而Elasticsearch用来检索数据。这也意味着主数据库发生的一切变更都需要将其拷贝到Elasticsearch中。如果这时候有多个进程负责数据的同步,就会遇到《Elasticsearch乐观锁并发控制(optimistic concurrency control)》文章中提到的并发问题。 如果你的主数据库已经有 9年前 (2016-08-12) 1678℃ 0评论0喜欢
Elasticsearch是一个分布式系统。当documents被创建、更新或者删除,其新版本会被复制到集群的其它节点。Elasticsearch既是异步的(asynchronous )也是同步的(concurrent),其含义是复制请求都是并行发送的,但是到达目的地的顺序是无序的。Elasticsearch系统需要一种方法使得老版本的文档永远都无法覆盖新的版本。 每当文档被改变的 9年前 (2016-08-11) 3720℃ 1评论2喜欢
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。 本文并不打算介绍ElasticSearch的概 9年前 (2016-08-10) 36877℃ 2评论73喜欢
在《ElasticSearch系列文章:基本介绍》中主要介绍了ElasticSearch一些使用场景,本文将对Elasticsearch的核心概念进行介绍,这对后期使用ElasticSearch有着重要的影响。 1、NearRealtime(NRT):准实时Elasticsearch是一个准实时的搜索平台,这意味着当你索引一个文档(document )时,在细微的延迟(通常1s)之后,该文件才能被搜索到。 9年前 (2016-08-09) 2446℃ 2评论3喜欢
ElasticSearch是一个基于Lucene构建的开源的分布式搜索和分析引擎,具备高可靠性和扩展性。它允许你快速准实时存储,搜索和分析海量数据。它通常作为底层引擎/计算来驱动企业级复杂搜索特性和需求。 下面列举一些使用ElasticSearch的应用场景: 1、运行一个在线的网店,你允许客户能够去搜索你销售的商品。在这 9年前 (2016-08-09) 2201℃ 0评论3喜欢
在这篇文章里,我将和大家分享一下我用Scala、Akka、Play、Kafka和ElasticSearch等构建大型分布式、容错、可扩展的分析引擎的经验。第一代架构 我的分析引擎主要是用于文本分析的。输入有结构化的、非结构化的和半结构化的数据,我们会用分析引擎对数据进行大量处理。如下图(点击查看大图)所示为第一代架构,分析引 9年前 (2016-08-08) 5267℃ 0评论13喜欢
今天由于某些原因需要卸载掉服务器上的php软件,然后我使用下面命令显示出本机安装的所有和php相关的软件,如下:[code lang="bash"]iteblog$ rpm -qa | grep phpphp-mysqlnd-5.6.25-0.1.RC1.el6.remi.x86_64php-fpm-5.6.25-0.1.RC1.el6.remi.x86_64php-pecl-jsonc-1.3.10-1.el6.remi.5.6.x86_64php-pecl-memcache-3.0.8-3.el6.remi.5.6.x86_64php-pdo-5.6.25-0.1.RC1.el6.remi.x86_64php-mbstrin 9年前 (2016-08-08) 2316℃ 0评论2喜欢
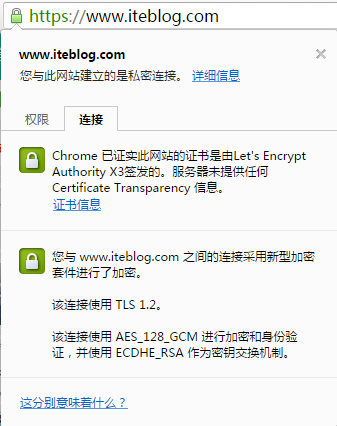
本博客的《如何申请免费好用的HTTPS证书Let's Encrypt》和《在Nginx中使用Let's Encrypt免费证书配置HTTPS》文章分别介绍了如何申请Let's Encrypt的HTTPS证书和如何在nginx里面配置Let's Encrypt的HTTPS证书。但是Let's Encrypt HTTPS证书的有效期只有90天:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop到期之 9年前 (2016-08-07) 1625℃ 0评论4喜欢
我昨天在《如何申请免费好用的HTTPS证书Let's Encrypt》中详细地介绍了申请免费的Let's Encrypt证书步骤,如果大家按照上面的文章介绍一步一步地操作我们可以在/data/web/ssl/文件夹下看到如下的文件列表:[code lang="bash"][iteblog@iteblog.com ssl] $ lltotal 28-rw-r--r-- 1 iteblog iteblog 3243 Aug 5 09:21 account.key-rw-r--r-- 1 iteblog iteblog 9159 Aug 5 09:33 9年前 (2016-08-07) 2044℃ 0评论2喜欢