本资料来自2021年12月09日举办的 PrestoCon 2021,标题为《Presto at Tencent at Scale: Usability Extension, Stability Improvement and Performance Optimization》Presto 在腾讯内部为不同业务部门提供临时查询(ad-hoc queries)和交互式查询( interactive queries)场景。在这次演讲中,我们将分享腾讯在生产中的实践。并且将讨论腾讯在 Presto 上面的工作,以进一步 3年前 (2021-12-08) 386℃ 0评论0喜欢
存储计算分离是整个行业的发展趋势,这种架构的存储和计算可以各自独立发展,它帮助云提供商降低成本。Presto 原生就支持这样的架构,数据可以从 Presto 服务器之外的远程存储节点传输过来。然而,存储计算分解也为查询延迟带来了新的挑战,因为当网络饱和时,通过网络扫描大量数据将受到 IO 限制。 此外,元数据的读取 3年前 (2021-12-05) 825℃ 0评论2喜欢
本文来自 Kyligence 主办的 Data & AI Meetup(第二期),会议时间为 11月16日。本期会议特别邀请了 Spark 社区大佬范文臣带来 Spark 3.2.0 新特性的首发解读。范文臣,Databricks 开源组技术主管,Apache Spark PMC member,Spark 社区最活跃的贡献者之一,目前主要负责 Spark Core/SQL 的设计开发和开源社区管理。Spark 作为目前大数据领域使用最普及的 3年前 (2021-11-30) 693℃ 0评论0喜欢
PrestoDB 官方并没有提供 Docker 镜像,但是其为我们提供了制作 Docker 镜像的方法,步骤很简单。本文主要是用于学习交流,并为大家展示如何制作并运行简单的的 Docker 镜像,Dockerfile 的编写大量参考了 PrestoDB 的文档。因为这里仅仅是测试,所以仅留了 tpch connecter,大家可以根据自己需求去修改。如果想及时了解Spark、Hadoop或者HBase 3年前 (2021-11-19) 635℃ 0评论1喜欢
本文介绍了如何使用 Presto 通过 Alluxio 查询 Iceberg 表。由于这项功能目前处于试验阶段,此处提供的信息可能会发生变化,请及时参考官方文档了解最新功能。关于如何使用 Presto 读取 Iceberg 上的数据请参考这里。我们知道,在 Hive 数据源上,Presto 支持两种形式的 Alluxio 缓存:通过 Alluxio local cache 以及 Alluxio Cluster,截止到本文章 3年前 (2021-11-18) 1273℃ 0评论6喜欢
我们在 《Presto 中支持的七种 Join 类型》 这篇文章中介绍了 Presto 可用的 JOIN 操作的基础知识,以及如何在 SQL 查询中使用它们。有了这些知识,我们现在可以了解 Presto 的内部结构以及它如何在内部执行 JOIN 操作。本文将介绍 Presto 如何执行 JOIN 操作以及用于 JOIN 的算法。JOIN 的实现几乎所有的数据库引擎一次只 JOIN 两个表。即 3年前 (2021-11-17) 870℃ 0评论0喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi 3年前 (2021-11-16) 500℃ 0评论1喜欢
本文是 2021-10-13 日周三下午13:30 举办的议题为《Improve Presto Architectural Decisions with Shadow Cache at Facebook》的分享,作者来自 Facebook 的 Ke Wang 和 普林斯顿CS系的 Zhenyu Song。Ke Wang is a software engineer at Facebook. She is currently developing solutions to help low latency queries in Presto at Facebook.Zhenyu Song is a Ph.D. student at Princeton CS Department. He works on using mach 3年前 (2021-11-16) 292℃ 0评论1喜欢
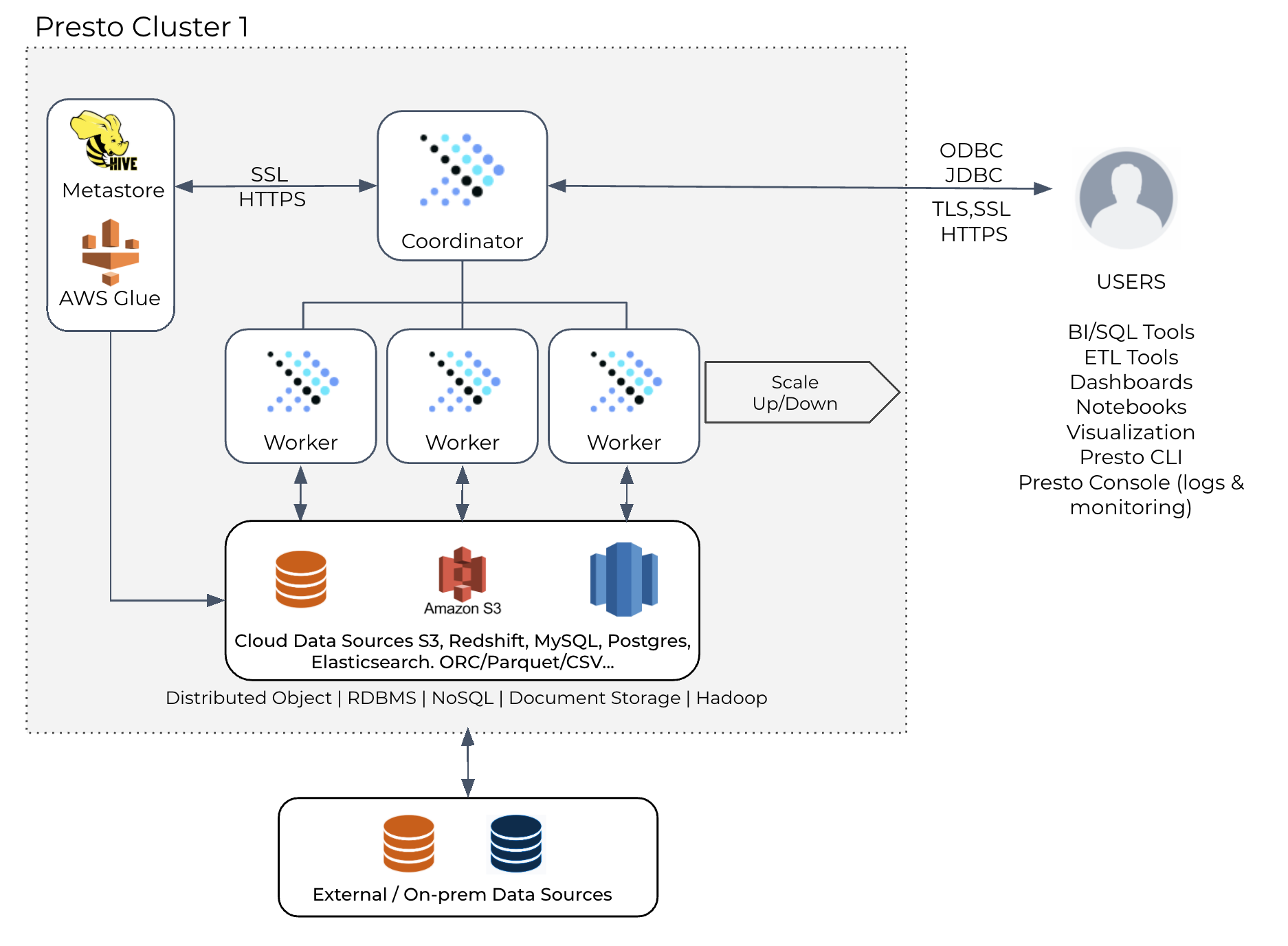
概述Presto 最初设计是对数据仓库中的数据运行交互式查询,但现在它已经发展成为一个位于开放数据湖分析之上的统一 SQL 引擎,用于交互式和批处理工作负载,数据湖上的流行工作负载包括:报告和仪表盘:这包括为内部和外部开发人员提供自定义报告以获取业务洞察力,以及许多使用 Presto 进行交互式 A/B 测试分析的组织 3年前 (2021-11-14) 1462℃ 0评论1喜欢
在使用 Presto 时,我们经常会听说 Query、Stage、Task 等概念,很多人会搞不清楚这些概念,所以会导致一些误解,本文将简单地介绍一下这些基本的概念是指StatementStatement语句。其实就是指我们输入的SQL语句。Presto支持需要ANSI标准的SQL语句。这种语句由子句(Clause)、表达式(Expression)和断言(Predicate)组成。Presto为什么将语句(S 3年前 (2021-11-01) 1998℃ 0评论4喜欢