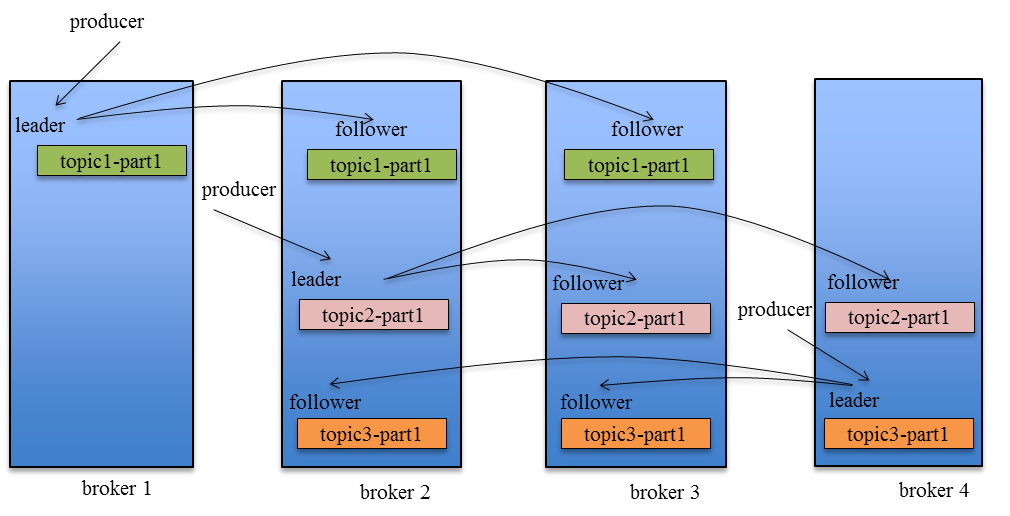
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服 10年前 (2015-05-19) 5440℃ 0评论3喜欢
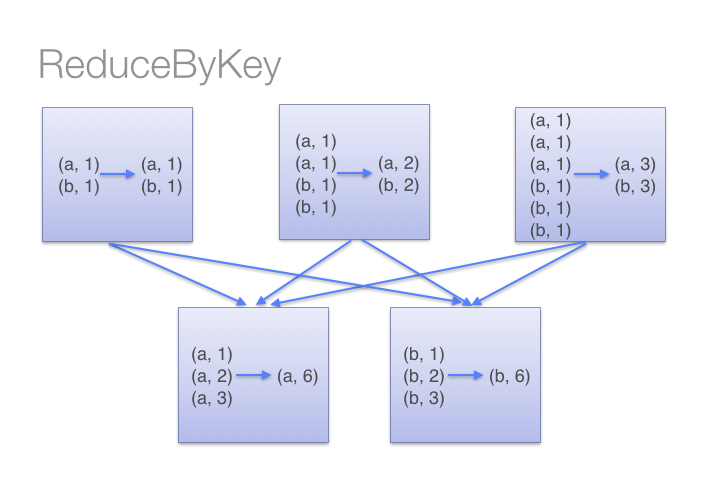
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 10年前 (2015-05-18) 33640℃ 0评论51喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 112.19.121.141 8123 高匿名 HTTP 10年前 (2015-05-15) 23834℃ 0评论6喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 122.246.148.77 8090 高匿名 HTTP 浙 10年前 (2015-05-15) 41167℃ 0评论0喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 10年前 (2015-05-15) 4832℃ 0评论3喜欢
如果你想知道Hadoop作业运行日志,可以查看这里《Hadoop日志存放路径详解》 在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。 Spark日志确切的存放路径和部署模式相关: (1)、如果是Spark Standalone模式,我们可以直接在Master UI界 10年前 (2015-05-14) 39808℃ 6评论16喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP 10年前 (2015-05-13) 46420℃ 0评论0喜欢
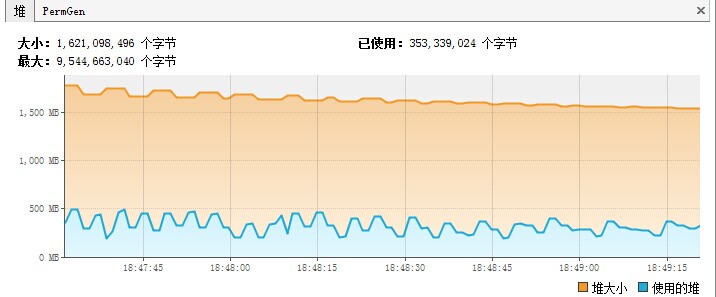
jvisualvm工具JDK自带的一个监控工具,该工具是用来监控java运行程序的cpu、内存、线程等的使用情况,并且使用图表的方式监控java程序、还具有远程监控能力,不失为一个用来监控Java程序的好工具。 同样,我们可以使用jvisualvm来监控Spark应用程序(Application),从而可以看到Spark应用程序堆,线程的使用情况,从而根据这 10年前 (2015-05-13) 10735℃ 0评论9喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 139.226.113.238 8090 高匿名 HTTP 10年前 (2015-05-12) 13713℃ 0评论1喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 117.162.225.199 8123 高匿名 HTTP 江西 10年前 (2015-05-12) 35036℃ 0评论3喜欢