Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 3年前 (2022-07-20) 1380℃ 0评论1喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 3年前 (2022-07-10) 654℃ 0评论3喜欢
Data + AI Summit 2021 于2021年05月24日至28日举行。本次会议是在线举办的,一共为期五天,第一、二天是培训,第三天到第五天是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习 w397090770 4年前 (2021-06-20) 1606℃ 0评论3喜欢
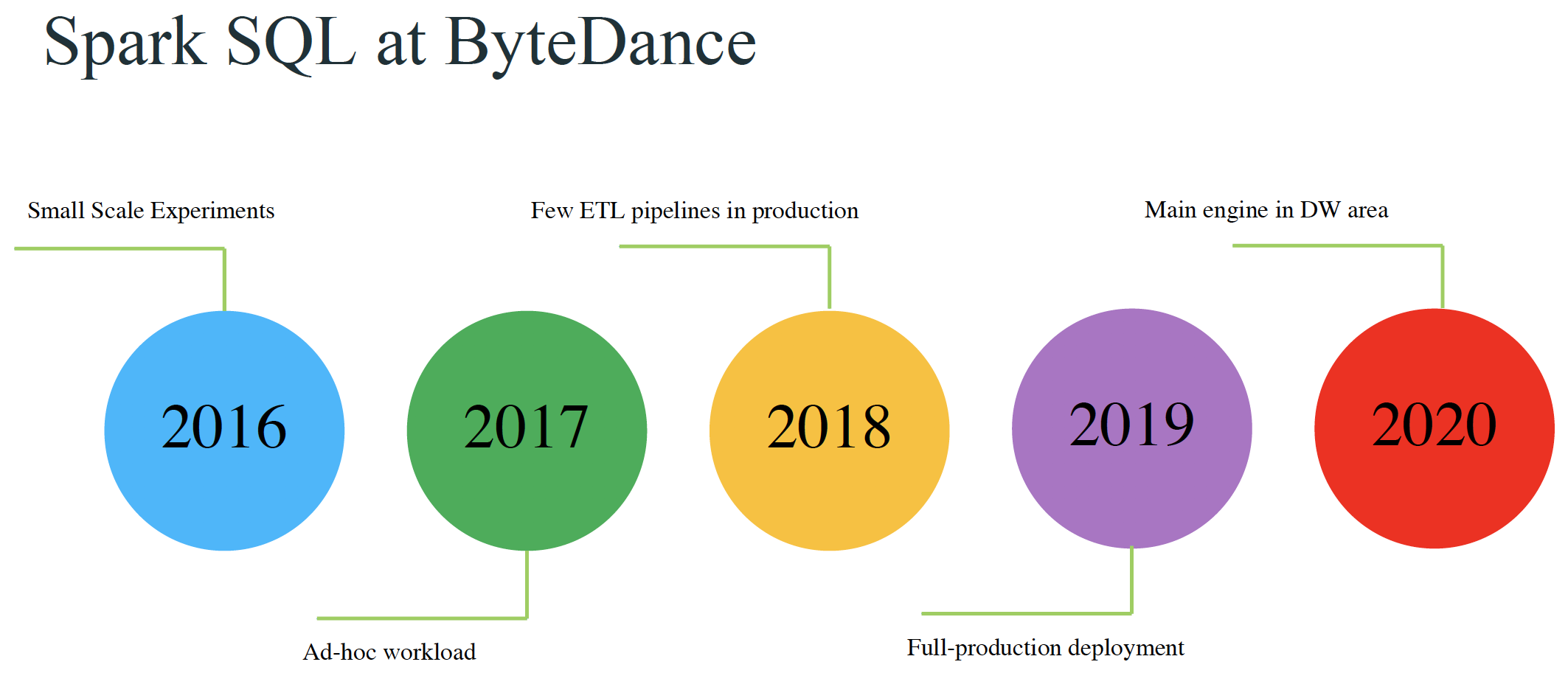
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2533℃ 2评论4喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 903℃ 0评论3喜欢
Data + AI Summit Europe 2020 原 Spark + AI Summit Europe 于2020年11月17日至19日举行。由于新冠疫情影响,本次会议和六月份举办的会议一样在线举办,一共为期三天,第一天是培训,第二天和第三天是正式会议。会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习框架来 w397090770 4年前 (2020-12-06) 1187℃ 0评论2喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 4年前 (2020-11-24) 1182℃ 0评论4喜欢