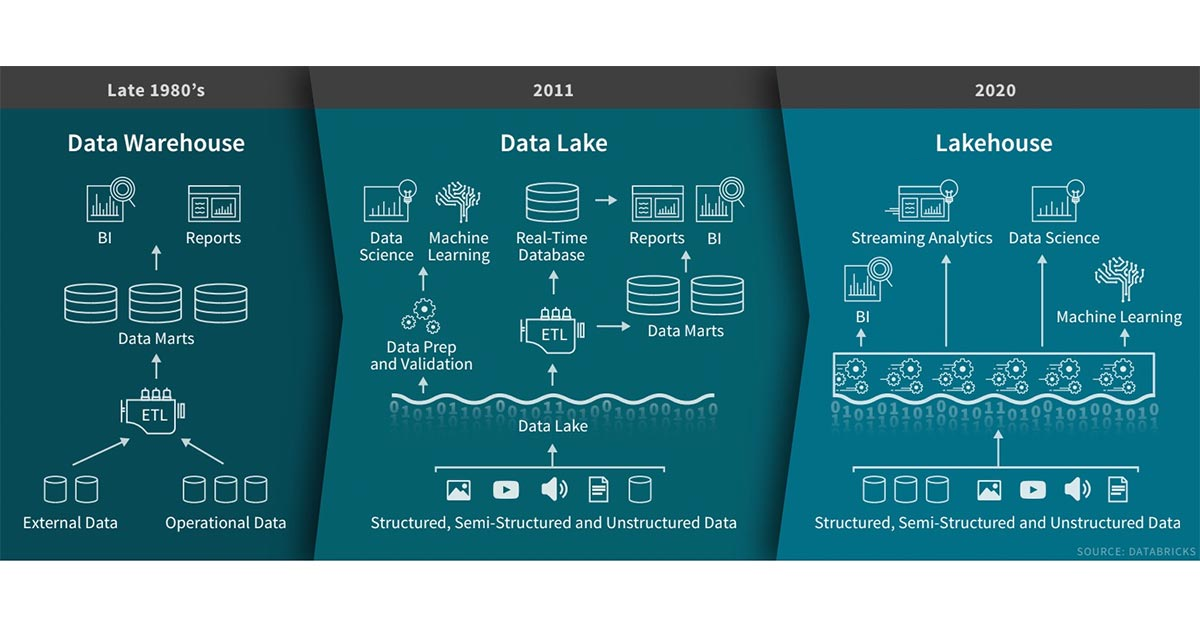
引入在Databricks的过去几年中,我们看到了一种新的数据管理范式,该范式出现在许多客户和案例中:LakeHouse。在这篇文章中,我们将描述这种新范式及其相对于先前方案的优势。数据仓库技术自1980诞生以来一直在发展,其在决策支持和商业智能应用方面拥有悠久的历史,而MPP体系结构使得系统能够处理更大数据量。但是,虽 w397090770 5年前 (2020-02-03) 3036℃ 0评论6喜欢
Delta Lake 是数砖公司在2017年10月推出来的一个项目,并于2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上开源的一个存储层。它是 Databricks Runtime 重要组成部分。为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构 w397090770 5年前 (2019-12-24) 4443℃ 0评论8喜欢
Delta Lake 0.5.0 于2019年12月13日正式发布,正式版本可以到 这里 下载使用。这个版本支持多种查询引擎查询 Delta Lake 的数据,比如常见的 Hive、Presto 查询引擎。并发操作得到改进。当然,这个版本还是不支持直接使用 SQL 去增删改查 Delta Lake 的数据,这个可能得等到明年1月的 Apache Spark 3.0.0 的发布。好了,下面我们来详细介绍这个版本 w397090770 5年前 (2019-12-15) 1793℃ 0评论2喜欢
Apache Spark Delta Lake 的更新(update)和删除都是在 0.3.0 版本发布的,参见这里,对应的 Patch 参见这里。和前面几篇源码分析文章一样,我们也是先来看看在 Delta Lake 里面如何使用更新这个功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopDelta Lake 更新使用Delta Lake 的官方文档为我们提供如何 w397090770 6年前 (2019-10-19) 2137℃ 0评论3喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop一年一度的 Spark + AI Summit Europe 峰会于2019年10月15-17日在欧洲的阿姆斯特丹举行。在10年16日 数砖和 Linux 基金会共同宣布 Delta Lake 和 将成为一个 Linux 基金会项目(参考:The Delta Lake Project Turns to Linux Foundation to Become the Open Standard for Data Lakes)。该项 w397090770 6年前 (2019-10-16) 1243℃ 0评论2喜欢
在这篇我们介绍了 Spark Delta Lake 0.4.0 的发布,并提到这个版本支持 Python API 和部分 SQL。本文我们将详细介绍 Delta Lake 0.4.0 Python API 的使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在本文中,我们将基于 Apache Spark™ 2.4.3,演示一个准时航班情况业务场景中,如何使用全新的 Delta Lake 0.4.0 w397090770 6年前 (2019-10-04) 1055℃ 0评论1喜欢
Apache Spark 发布了 Delta Lake 0.4.0,主要支持 DML 的 Python API、将 Parquet 表转换成 Delta Lake 表 以及部分 SQL 功能。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面详细地介绍这些功能部分功能的 SQL 支持SQL 的支持能够为用户提供极大的便利,如果大家去看数砖的 Delta Lake 产品,你肯定已 w397090770 6年前 (2019-10-01) 1310℃ 0评论4喜欢
本资料来自2019-09-26在杭州举办的云栖大会的大数据 & AI 峰会分会。议题名称《New Developments in the Open Source Ecosystem: Apache Spark 3.0 and Koalas》,分享嘉宾李潇,Databricks Spark 研发总监。下面是本次会议的视频(由于微信公众号的限制,只能发布小于30分钟的视频,完整视频和 PPT 请关注 过往记忆大数据 公众号并回复 spark_yq 获取。) w397090770 6年前 (2019-09-27) 2951℃ 0评论3喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 6年前 (2019-09-27) 1568℃ 0评论2喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 6年前 (2019-09-10) 2220℃ 0评论2喜欢