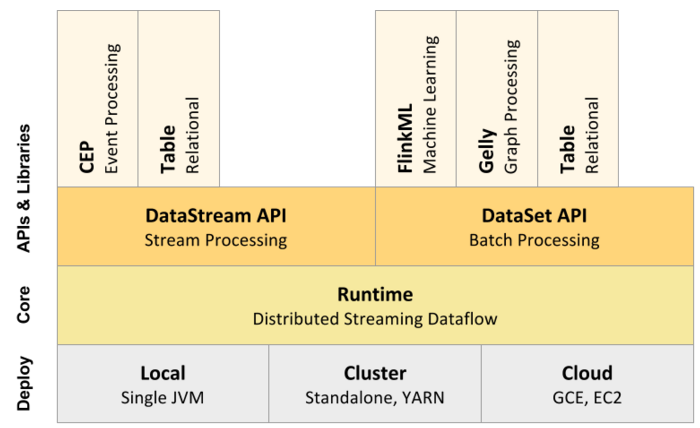
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24345℃ 6评论22喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 10年前 (2015-08-26) 7224℃ 1评论42喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,Ververica(Apache Flink 商业母公司)、腾讯、Google、Airbnb以及 Uber 等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生 w397090770 11年前 (2014-07-21) 44858℃ 55评论28喜欢