Monarch 是 Pinterest 的批处理平台,由30多个 Hadoop YARN 集群组成,其中17k+节点完全建立在 AWS EC2 之上。2021年初,Monarch 还在使用五年前的 Hadoop 2.7.1。由于同步社区分支(特性和bug修复)的复杂性不断增加,我们决定是时候进行版本升级了。我们最终选择了Hadoop 2.10.0,这是当时 Hadoop 2 的最新版本。本文分享 Pinterest 将 Monarch 升级到 Ha w397090770 2年前 (2022-08-12) 639℃ 0评论4喜欢
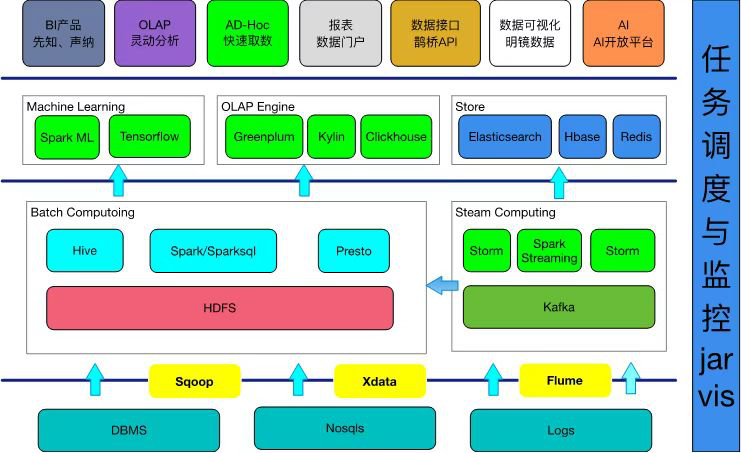
HDFS 架构介绍 HDFS离线存储平台是Hadoop大数据计算的底层架构,在B站应用已经超过5年的时间。经过多年的发展,HDFS存储平台目前已经发展成为总存储数据量近EB级,元数据总量近百亿级,NameSpace 数量近20组,节点数量近万台,日均吞吐几十PB数据量的大型分布式文件存储系统。 首先我们来介绍一下B站的HDFS离线存储平台的总体架 w397090770 3年前 (2022-04-01) 1175℃ 0评论4喜欢
背景随着同程旅行业务和数据规模越来越大,原有的机房不足以支撑未来几年的扩容需求,同时老机房的保障优先级也低于新机房。为了不受限于机房的压力,公司决定进行机房迁移。为了尽快完成迁移,需要1个月内完成上百PB数据量的集群迁移,迁移过程不允许停止服务。目前HADOOP集群主要有多个2.X版本,2019年升级到联 zz~~ 3年前 (2021-11-16) 663℃ 0评论1喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 469℃ 0评论3喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 565℃ 0评论4喜欢
本次的分享内容分成四个部分: 1.汽车之家离线计算平台现状2.平台构建过程中遇到的问题3.基于构建过程中问题的解决方案4.离线计算平台未来规划 汽车之家离线计算平台现状 1. 汽车之家离线计算平台发展历程如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 2013年的时候汽 w397090770 3年前 (2021-08-30) 612℃ 0评论4喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据过往记忆大数据备注:以下的我们均代表 Uber 的 Hadoop 运维团队。介绍随着 Uber 业务的增长,Uber 公司在 5 年内将 Apache Hadoop(本文简称为“Hadoop”)部署扩展到 21000 台以上的节点,以支持各种分析和机器学习用例。我们组建了一支拥有各 w397090770 3年前 (2021-08-22) 771℃ 0评论4喜欢
背景 现状 HDFS 全称是 Hadoop Distributed File System,其本身是 Apache Hadoop 项目的一个模块,作为大数据存储的基石提供高吞吐的海量数据存储能力。自从 2006 年 4 月份发布以来,HDFS 目前依然有着非常广泛的应用,以字节跳动为例,随着公司业务的高速发展,目前 HDFS 服务的规模已经到达“双 10”的级别: 单集群节点 10 万台级别单 w397090770 4年前 (2021-07-29) 569℃ 0评论2喜欢
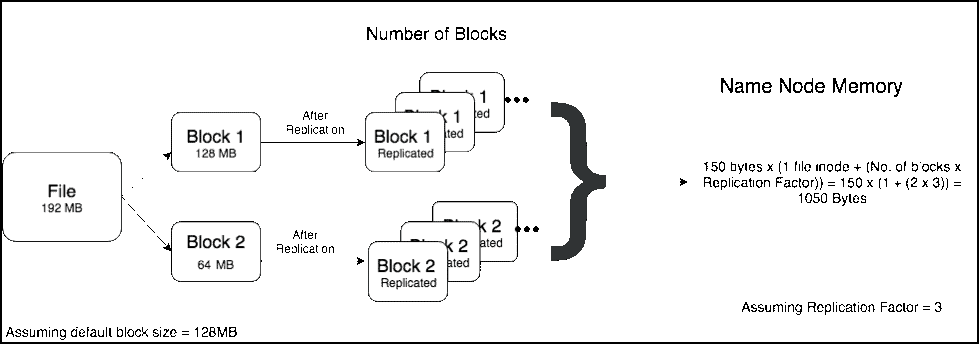
背景随着集群规模的不断扩张,文件数快速增长,目前集群的文件数已高达2.7亿,这带来了许多问题与挑战。首先是文件目录树的扩大导致的NameNode的堆内存持续上涨,其次是Full GC时间越来越长,导致NameNode宕机越发频繁。此外,受堆内存的影响,RPC延时也越来越高。针对上述问题,我们做了一些相关工作:控制文件数增长 w397090770 4年前 (2021-07-02) 1368℃ 0评论4喜欢
在使用Hadoop过程中,小文件是一种比较常见的挑战,如果不小心处理,可能会带来一系列的问题。HDFS是为了存储和处理大数据集(M以上)而开发的,大量小文件会导致Namenode内存利用率和RPC调用效率低下,block扫描吞吐量下降,应用层性能降低。通过本文,我们将定义小文件存储的问题,并探讨如何对小文件进行治理。什么是小 w397090770 4年前 (2021-02-24) 1068℃ 0评论6喜欢