Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 8年前 (2017-06-02) 207℃ 0评论0喜欢
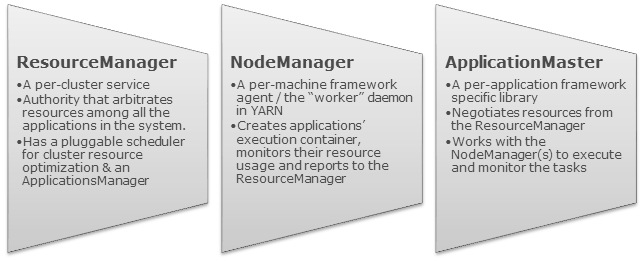
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 8年前 (2017-06-01) 4032℃ 0评论31喜欢
我在前面的文章介绍了MapReduce中两种全排序的方法及其实现。但是上面的两种方法都是有很大的局限性:方法一在数据量很大的时候会出现OOM问题;方法二虽然能够将数据分散到多个Reduce中,但是问题也很明显:我们必须手动地找到各个Reduce的分界点,尽量使得分散到每个Reduce的数据量均衡。而且每次修改Reduce的个数时,都得 w397090770 8年前 (2017-05-12) 7306℃ 14评论20喜欢
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序。但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序。基于此,本文提供三种方法来对MapReduce的输出进行全局排序。生成测试数据在介绍如何实现之前,我们先来生成一些测试数据,实现如下:[code lang="bash"]#! w397090770 8年前 (2017-05-10) 14569℃ 0评论29喜欢
Spark 的 shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式来学习 API。它可以使用 Scala(在 Java 虚拟机上运行现有的 Java 库的一个很好方式) 或 Python。我们很可能会在Spark Shell模式下运行下面的测试代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> imp w397090770 8年前 (2017-04-26) 2888℃ 0评论9喜欢
我们都知道,HDFS设计是用来存储海量数据的,特别适合存储TB、PB量级别的数据。但是随着时间的推移,HDFS上可能会存在大量的小文件,这里说的小文件指的是文件大小远远小于一个HDFS块(128MB)的大小;HDFS上存在大量的小文件至少会产生以下影响:消耗NameNode大量的内存延长MapReduce作业的总运行时间如果想及时了解Spar w397090770 8年前 (2017-04-25) 6862℃ 1评论18喜欢
我们在使用Hadoop、Spark或者是Hbase,最常遇到的问题就是进行相关系统的配置,比如集群的URL地址,MapReduce临时目录、最终输出路径等。这些属性需要有一个系统(类)进行管理。然而,Hadoop没有使用 Java.util.Properties 管理配置文件,也没有使用Apache Jakarta Commons Configuration管理配置文件,而是单独开发了一个配置文件管理类,这个类就 w397090770 8年前 (2017-04-21) 7752℃ 0评论18喜欢
大家在提交MapReduce作业的时候肯定看过如下的输出:[code lang="bash"]17/04/17 14:00:38 INFO mapreduce.Job: Running job: job_1472052053889_000117/04/17 14:00:48 INFO mapreduce.Job: Job job_1472052053889_0001 running in uber mode : false17/04/17 14:00:48 INFO mapreduce.Job: map 0% reduce 0%17/04/17 14:00:58 INFO mapreduce.Job: map 100% reduce 0%17/04/17 14:01:04 INFO mapreduce.Job: map 100% reduce 100%[/ w397090770 8年前 (2017-04-18) 3687℃ 2评论11喜欢
时隔两年,Apache Hadoop终于又有大改版,Apache基金会近日发布了Hadoop 2.8版,一次新增了2,919项更新功能或新特色。不过,Hadoop官网建议,2.8.0仍有少数功能在测试,要等到释出2.8.1或是2.8.2版才适合用于正式环境。在2.8.0版众多更新,主要分布于4大套件分别是:共用套件(Common)底层分散式档案系统HDFS套件(HDFS)MapReduce运算 w397090770 8年前 (2017-03-31) 2821℃ 2评论17喜欢
Hadoop Streaming 是 Hadoop 提供的一个 MapReduce 编程工具,它允许用户使用任何可执行文件、脚本语言或其他编程语言来实现 Mapper 和 Reducer 作业。比如下面的例子[code lang="bash"]mapred streaming \ -input myInputDirs \ -output myOutputDir \ -mapper /bin/cat \ -reducer /usr/bin/wc[/code]Hadoop Streaming程序是如何工作的Hadoop Streaming 使用了 Unix 的标准 w397090770 8年前 (2017-03-21) 10032℃ 0评论15喜欢