1.文件大小默认为64M,改为128M有啥影响?2.RPC的原理?3.NameNode与SecondaryNameNode的区别与联系?4.介绍MadpReduce整个过程,比如把WordCount的例子的细节将清楚(重点讲解Shuffle)?5.MapReduce出现单点负载多大,怎么负载平衡?6.MapReduce怎么实现Top10?7.hadoop底层存储设计8.zookeeper有什么优点,用在什么场合9.Hbase中的meta w397090770 9年前 (2016-08-26) 3598℃ 0评论2喜欢
1. 集群多少台, 数据量多大, 吞吐量是多大, 每天处理多少G的数据?2. 我们的日志是不是除了apache的访问日志是不是还有其他的日志?3. 假设我们有其他的日志是不是可以对这个日志有其他的业务分析?这些业务分析都有什么?4. 你们的服务器有多少台?服务器的内存多大?5. 你们的服务器怎么分布的?(这里说地理位置 w397090770 9年前 (2016-08-26) 3455℃ 0评论4喜欢
1.hbase怎么预分区?2.hbase怎么给web前台提供接口来访问?3.htable API有没有线程安全问题,在程序中是单例还是多例?4.hbase有没有并发问题?5.metaq消息队列,zookeeper集群,storm集群,就可以完成对商城推荐系统功能吗?还有没有其他的中间件?6.storm 怎么完成对单词的计数?7.hdfs的client端,复制到第三个副本时宕机, w397090770 9年前 (2016-08-26) 4166℃ 0评论2喜欢
一. 问答题1.请说说hadoop1的HA如何实现?2.列举出hadoop中定义的最常用的InputFormats。那个是默认的?3.TextInputFormat和KeyValueInputFormat类之间的不同之处在于哪里?4.hadoop中的InputSplit是什么?5.hadoop框架中文件拆分是如何被触发的?6.hadoop中的RecordReader的目的是什么?7.如果hadoop中没有定义定制分区,那么如何在输出 w397090770 9年前 (2016-08-26) 5726℃ 0评论5喜欢
一、 问答题1、简单描述如何安装配置一个apache开源版hadoop,只描述即可,无需列出完整步骤,能列出步骤更好。1) 安装JDK并配置环境变量(/etc/profile)2) 关闭防火墙3) 配置hosts文件,方便hadoop通过主机名访问(/etc/hosts)4) 设置ssh免密码登录5) 解压缩hadoop安装包,并配置环境变量6) 修改配置文件($HADOOP_HOME/conf)hadoop-e w397090770 9年前 (2016-08-26) 7987℃ 0评论14喜欢
MapReduce作业可以细分为map task和reduce task,而MRAppMaster又将map task和reduce task分为四种状态: 1、pending:刚启动但尚未向resourcemanager发送资源请求; 2、scheduled:已经向resourceManager发送资源请求,但尚未分配到资源; 3、assigned:已经分配到了资源且正在运行; 4、completed:已经运行完成。 map task的 w397090770 9年前 (2016-08-01) 3496℃ 0评论4喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所以在选择不同当时监控时,我们需要详细了解需要我们的需 w397090770 9年前 (2016-06-23) 21465℃ 0评论34喜欢
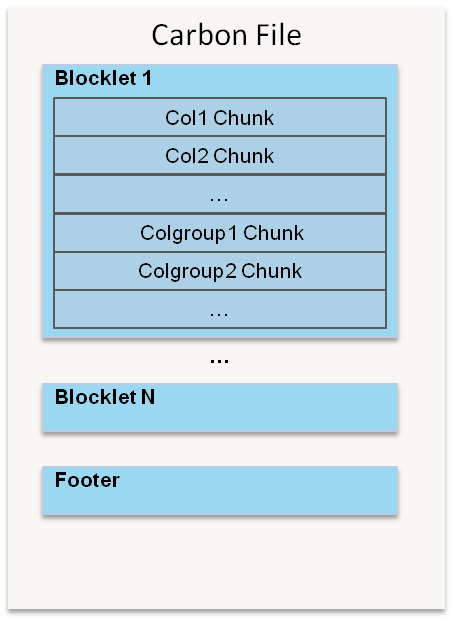
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 9年前 (2016-06-13) 5507℃ 0评论7喜欢
随着大数据技术的发展,HDFS作为Hadoop的核心模块之一得到了广泛的应用。为了系统的可靠性,HDFS通过复制来实现这种机制。但在HDFS中每一份数据都有两个副本,这也使得存储利用率仅为1/3,每TB数据都需要占用3TB的存储空间。随着数据量的增长,复制的代价也变得越来越明显:传统的3份复制相当于增加了200%的存储开销,给存 w397090770 9年前 (2016-05-30) 9376℃ 0评论36喜欢
在Linux文件系统中,我们可以使用下面的Shell脚本判断某个文件是否存在:[code lang="bash"]# 这里的-f参数判断$file是否存在 if [ ! -f "$file" ]; then echo "文件不存在!"fi [/code]但是我们想判断HDFS上某个文件是否存在咋办呢?别急,Hadoop内置提供了判断某个文件是否存在的命令:[code lang="bash"][iteblog@www.it w397090770 9年前 (2016-03-21) 10825℃ 0评论19喜欢