本文是 2021-10-13 日周三下午13:30 举办的议题为《Apache Hudi : The Path Forward》的分享,作者来自Apache Hudi 项目的原始创建者和副总裁 Vinoth Chandar 和 Zendesk 的 Raymond Xu。Raymond Xu leads the Data Lake team at Zendesk. He is also a PMC member and committer for Apache Hudi.Vinoth Chandar is the original creator & VP of the Apache Hudi project, which has changed the face of data lake archi w397090770 3年前 (2021-11-16) 495℃ 0评论1喜欢
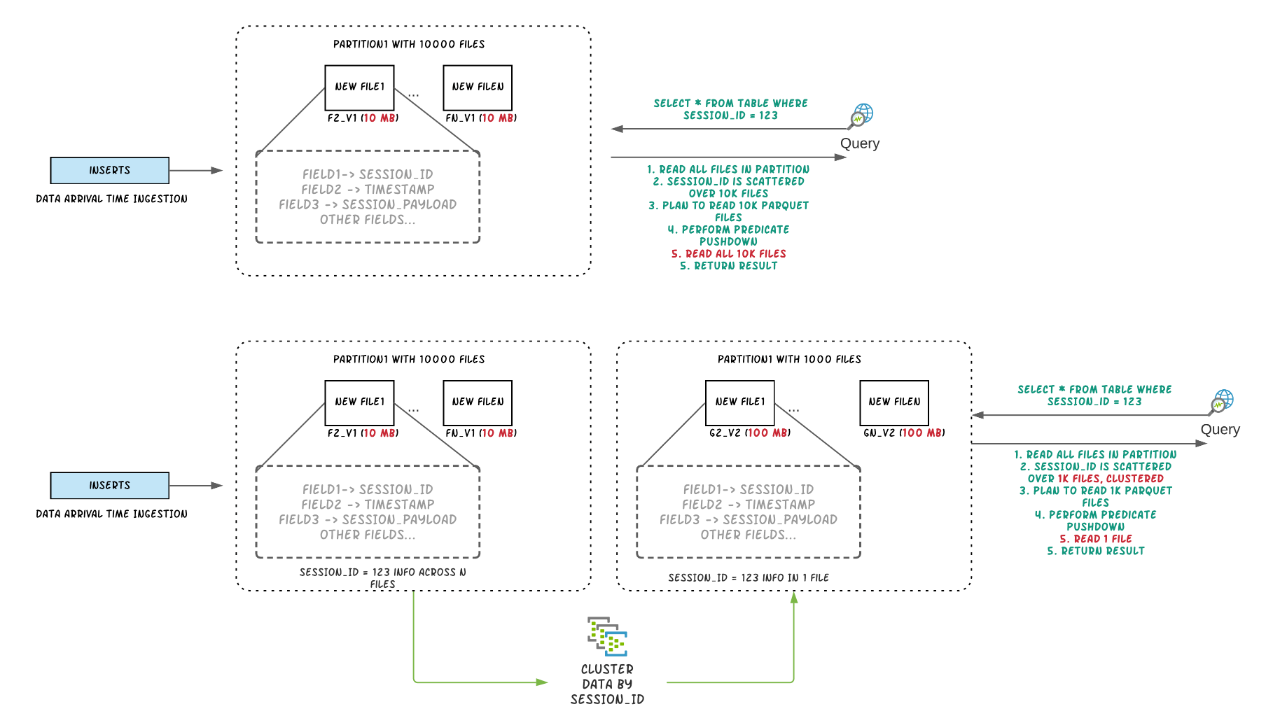
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 4年前 (2021-08-03) 1130℃ 0评论1喜欢
迁移指南如果从 0.5.3 以下版本迁移,请检查这个版本后面的其他版本的升级说明。如果需要升级到 0.8 版本,请参阅 0.6.0 版本的升级指南,因为本版本没有引入新的表版本(table versions)HoodieRecordPayload接口不建议使用现有方法,而推荐使用新方法,该方法还允许我们在运行时传递属性。 鼓励用户从不建议使用的方法中迁移 w397090770 4年前 (2021-04-14) 920℃ 0评论2喜欢
背景Apache Hudi将流处理带到大数据,相比传统批处理效率高一个数量级,提供了更新鲜的数据。在数据湖/仓库中,需要在摄取速度和查询性能之间进行权衡,数据摄取通常更喜欢小文件以改善并行性并使数据尽快可用于查询,但很多小文件会导致查询性能下降。在摄取过程中通常会根据时间在同一位置放置数据,但如果把查询频 w397090770 4年前 (2021-02-24) 1549℃ 0评论4喜欢
本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 337℃ 0评论0喜欢
在过去一年有很多 Apache 孵化项目顺利毕业成顶级项目(Top-Level Project ,简称 TLP ),在这里我将给大家盘点 2020 年晋升为 Apache TLP 的大数据相关项目。在2020年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® ShardingSphere™、Apache® Hudi™、Apache® Iceberg™ 以及 Apache® IoTDB™,这里以毕业的时间顺序依次介绍。关于过 w397090770 4年前 (2021-01-03) 1423℃ 0评论5喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1862℃ 0评论2喜欢
本文英文原文:https://hudi.apache.org/releases.html下载信息源码:Apache Hudi 0.6.0 Source Release (asc, sha512)二进制Jar包:nexus如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2. 迁移指南如果您从0.5.3以前的版本迁移至0.6.0,请仔细核对每个版本的迁移指南;0.6.0版本从基于list的rollback策略变更为 w397090770 4年前 (2020-09-02) 909℃ 0评论0喜欢
2020年6月4日,马萨诸塞州韦克菲尔德(Wakefield, MA)—— Apache 软件基金会(ASF),超过350个开源项目和计划的全志愿者开发人员、管理人员和孵化器,正式宣布 Apache Hudi 成为顶级项目(Top-Level Project 、TLP)。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Hudi (Hadoop Upserts delete and Incrementa w397090770 5年前 (2020-06-04) 1233℃ 0评论5喜欢
美国当地时间2020年05月11日,Apache Hudi 项目的共同创始人、PMC Vinoth Chandar 给社区发了一封标题为 [DISCUSS] Graduate Apache Hudi (Incubating) as a TLP 的邮件,来投票讨论 Apache Hudi 毕业成为 Apache TLP 项目。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop2020年05月19日共40人投票赞成 。不久社区给 Apache 董事 w397090770 5年前 (2020-05-22) 1204℃ 0评论1喜欢