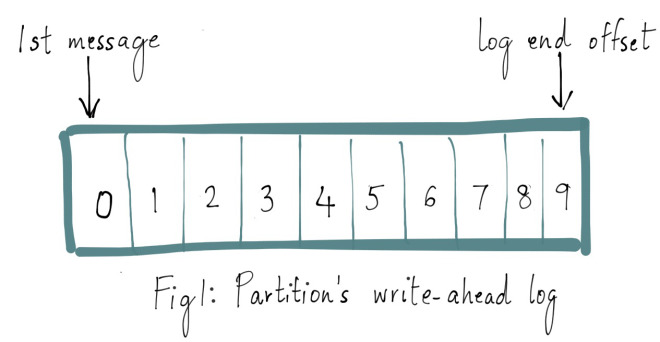
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的。Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性。随着社区添加更多功能,开发者们会回过头来重新思考简化复杂行为的方法。Apache Kafka 中一个更细微的功能是它的复制协议(replication protocol)。对于单个集 w397090770 6年前 (2019-05-26) 5175℃ 1评论14喜欢
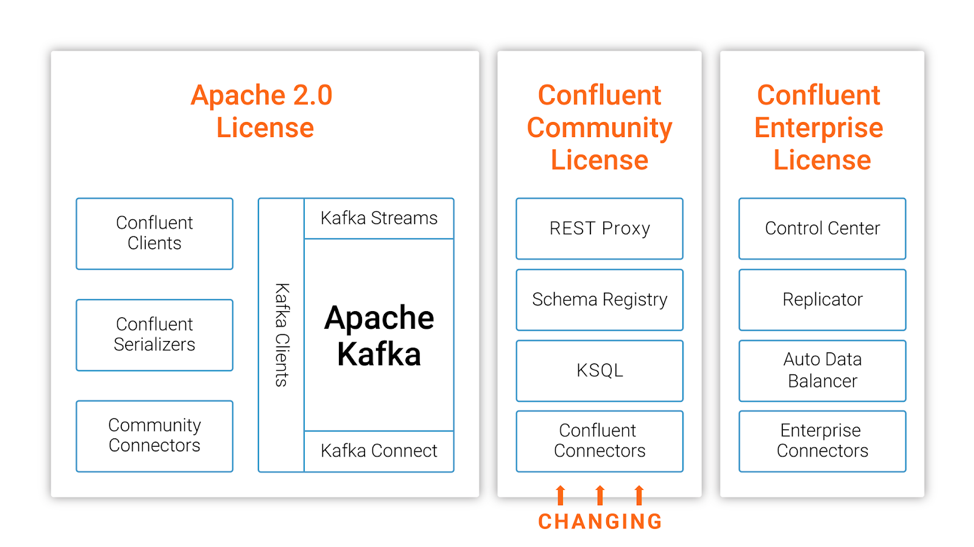
在今年的十月份,MongoDB 宣布其开源许可证从 GNU AGPLv3 切换到 Server Side Public License (SSPL),十一月份,图数据库 Neo4j 也宣布企业版彻底闭源。今天,Confluent 公司的联合创始人兼 CEO Jay Kreps 在 Confluent 官方博客宣布 Confluent 平台部分开源组件从 Apache 2.0 切换到 Confluent Community License,参见这里,下面是这篇文章的全部翻译。我们正在将 w397090770 6年前 (2018-12-15) 2025℃ 0评论3喜欢
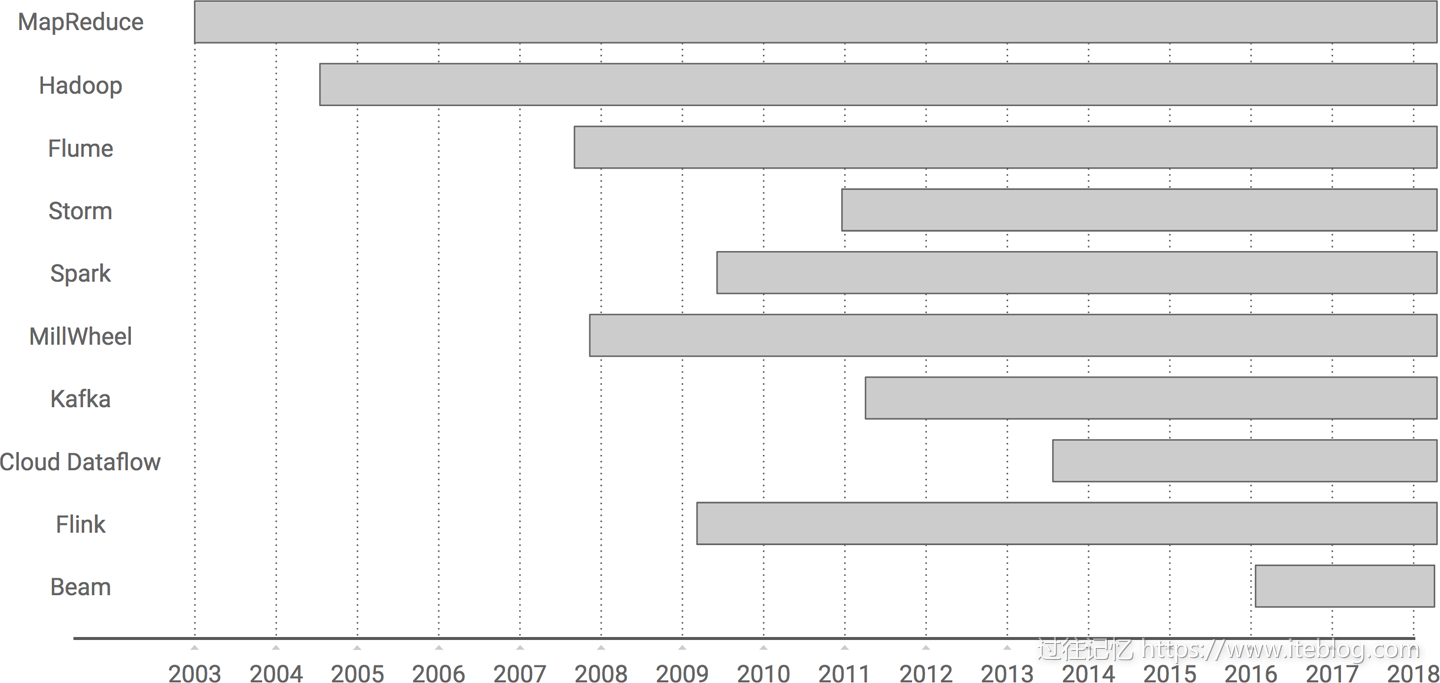
本文翻译自《Streaming System》最后一章《The Evolution of Large-Scale Data Processing》,在探讨流式系统方面本书是市面上难得一见的深度书籍,非常值得学习。大数据如果从 Google 对外发布 MapReduce 论文算起,已经前后跨越十五年,我打算在本文和你蜻蜓点水般一起浏览下大数据的发展史,我们从最开始 MapReduce 计算模型开始,一路走马观 w397090770 7年前 (2018-10-08) 10376℃ 2评论27喜欢
经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取 Kafka 中的数据,这种情况下 Spark RDD 中分区和 Kafka 分区是一一对 w397090770 7年前 (2018-09-08) 6648℃ 0评论25喜欢
Apache Kafka 2.0.0 在昨天正式发布了,其包含了许多重要的特性,这里我列举了一些比较重要的:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop增加了前缀通配符访问控制(ACL)的支持,详见 KIP-290,这样我们可以更加细粒度的进行访问控制;更全面的数据安全支持,KIP-255 里面添加了一个框架, w397090770 7年前 (2018-07-31) 3996℃ 0评论6喜欢
本文基于 A Guide To The Kafka Protocol 2017-06-14 的版本 v114 进行翻译的。简介本文档涵盖了 Kafka 0.8 及更高版本的通信协议实现。它旨在提供一个可读的,涵盖可请求的协议及其二进制格式,以及如何正确使用他们来实现一个客户端的协议指南。本文假设您已经了解了 Kafka 的基本设计以及术语。0.7 及更早的版本所使用的协议与此 w397090770 7年前 (2018-07-11) 4271℃ 1评论12喜欢
今天 Apache Kafka 项目的 2.0.0 版本正式发布了!距离 1.0 版本的发布,相距还不到一年。这一年不论是社区还是 Confluent 内部对于到底 Kafka 要向哪里发展都有很多讨论:从最初的标准消息系统,到现如今成为一个完整的包括导入导出和处理的流数据平台,从 0.8.2 一直到 1.0 版本,很多新特性和新部件被不断添加。但同时更重要的,关于 w397090770 7年前 (2018-06-28) 5296℃ 0评论6喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 7年前 (2018-05-13) 4882℃ 0评论0喜欢
本书于2017-08由 Packt 出版,作者 Manish Kumar, Chanchal Singh,全书269页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Learn the basics of Apache Kafka from scratchUse the basic building blocks of a streaming applicationDesign effective streaming applications with Kafka using Spark, Storm &, and HeronUnderstand the i zz~~ 7年前 (2017-11-08) 6670℃ 0评论31喜欢
Kafka 从首次发布之日起,已经走过了七个年头。从最开始的大规模消息系统,发展成为功能完善的分布式流式处理平台,用于发布和订阅、存储及实时地处理大规模流数据。来自世界各地的数千家公司在使用 Kafka,包括三分之一的 500 强公司。Kafka 以稳健的步伐向前迈进,首先加入了复制功能和无边界的键值数据存储,接着推出了用 w397090770 7年前 (2017-11-05) 25851℃ 0评论17喜欢




![[电子书]Building Data Streaming Applications with Apache Kafka PDF下载](https://www.iteblog.com/pic/books/building-data-streaming-applications-apache-kafka-iteblog.png)