Streaming job 的调度与执行 我们先来看看如下 job 调度执行流程图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop为什么很难保证 exactly once 上面这张流程图最主要想说明的就是,job 的提交执行是异步的,与 checkpoint 操作并不是原子操作。这样的机制会引起数据重复消费问题: zz~~ 9年前 (2016-09-08) 8926℃ 5评论12喜欢
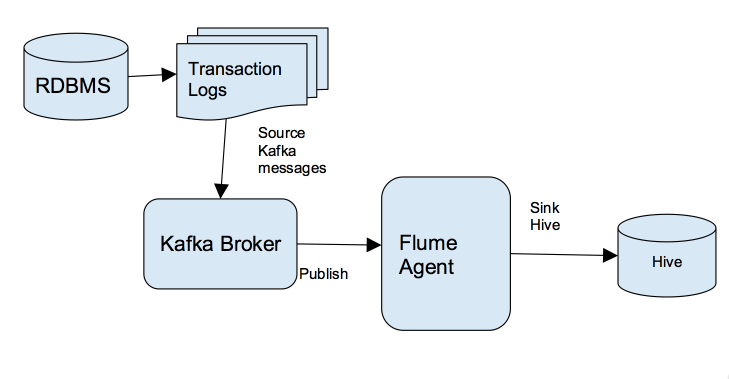
对那些想快速把数据传输到其Hadoop集群的企业来说,Kafka是一个非常合适的选择。关于什么是Kafka我就不介绍了,大家可以参见我之前的博客:《Apache kafka入门篇:工作原理简介》 本文是面向技术人员编写的。阅读本文你将了解到我是如何通过Kafka把关系数据库管理系统(RDBMS)中的数据实时写入到Hive中,这将使得实时分析的 w397090770 9年前 (2016-08-30) 11531℃ 6评论26喜欢
在这篇文章里,我将和大家分享一下我用Scala、Akka、Play、Kafka和ElasticSearch等构建大型分布式、容错、可扩展的分析引擎的经验。第一代架构 我的分析引擎主要是用于文本分析的。输入有结构化的、非结构化的和半结构化的数据,我们会用分析引擎对数据进行大量处理。如下图(点击查看大图)所示为第一代架构,分析引 w397090770 9年前 (2016-08-08) 5260℃ 0评论13喜欢
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 9年前 (2016-07-26) 10949℃ 3评论17喜欢
Apache Kafka在LinkedIn和其他公司中是作为各种数据管道和异步消息的后端。Netflix和Microsoft公司作为Kafka的重量级使用者(Four Comma Club,每天万亿级别的消息量),他们在Kafka Summit的分享也让人受益良多。 虽然Kafka有着极其稳定的架构,但是在每天万亿级别消息量的大规模下也会偶尔出现有趣的bug。在本篇文章以及以后的几篇 w397090770 9年前 (2016-07-20) 5352℃ 1评论6喜欢
Apache Kafka 0.10.0.0于美国时间2016年5月24日正式发布。Apache Kafka 0.10.0.0是Apache Kafka的主要版本,此版本带来了一系列的新特性和功能加强。本文将对此版本的重要点进行说明。Kafka StreamsKafka Streams在几个月前由Confluent Platform首先在其平台的技术预览中行提出,目前已经在Apache Kafka 0.10.0.0上可用了。Kafka Streams其实是一套类库,它使 w397090770 9年前 (2016-05-25) 12433℃ 0评论25喜欢
如果我们需要通过编程的方式来获取到Kafka中某个Topic的所有分区、副本、每个分区的Leader(所在机器及其端口等信息),所有分区副本所在机器的信息和ISR机器的信息等(特别是在使用Kafka的Simple API来编写SimpleConsumer的情况)。这一切可以通过发送TopicMetadataRequest请求到Kafka Server中获取。代码片段如下所示:[code lang="scala"]de w397090770 9年前 (2016-05-09) 8354℃ 0评论4喜欢
本文将介绍如何通过Flink读取Kafka中Topic的数据。 和Spark一样,Flink内置提供了读/写Kafka Topic的Kafka连接器(Kafka Connectors)。Flink Kafka Consumer和Flink的Checkpint机制进行了整合,以此提供了exactly-once处理语义。为了实现这个语义,Flink不仅仅依赖于追踪Kafka的消费者group偏移量,而且将这些偏移量存储在其内部用于追踪。 和Sp w397090770 9年前 (2016-05-03) 23983℃ 1评论23喜欢
本文将介绍如何手动更新Kafka存在Zookeeper中的偏移量。我们有时候需要手动将某个主题的偏移量设置成某个值,这时候我们就需要更新Zookeeper中的数据了。Kafka内置为我们提供了修改偏移量的类:kafka.tools.UpdateOffsetsInZK,我们可以通过它修改Zookeeper中某个主题的偏移量,具体操作如下:[code lang="bash"][iteblog@www.iteblog.com ~]$ bin/ka w397090770 9年前 (2016-04-19) 15218℃ 0评论12喜欢
在前面的文章《Kafka集群扩展以及重新分布分区》中,我们将介绍如何通过Kafka自带的工具来增加Topic的分区数量。本文将简单地介绍如何通过Kafka自带的工具来动态增加Tpoic的副本数。首先来看看我们操作的Topic相关的信息[iteblog@www.iteblog.com ~]$ kafka-topics.sh --topic iteblog --describe --zookeeper www.iteblog.com:2181Topic:iteblog PartitionCount:2 w397090770 9年前 (2016-04-18) 11482℃ 0评论14喜欢