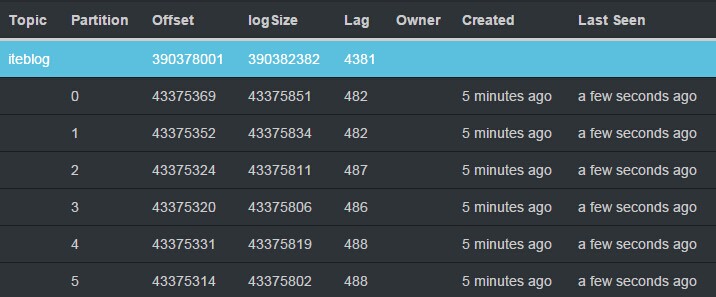
摘要 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka的性能测试报告。性能测试及集群监控工具 Kafka提供了非常多有用的工具,如Kafka设计解析(三)- Kafka High Availability (下)中提到的运维类工具——Partition Reassign Tool,Prefe w397090770 9年前 (2015-12-31) 4511℃ 1评论6喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》High Level Consumer 很多时候,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同 w397090770 10年前 (2015-09-08) 9661℃ 0评论22喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 10年前 (2015-08-26) 7224℃ 1评论42喜欢
下面的大数据学习电子书我会陆续上传,敬请关注。一、Hadoop1、Hadoop Application Architectures2、Hadoop: The Definitive Guide, 4th Edition3、Hadoop Security Protecting Your Big Data Platform4、Field Guide to Hadoop An Introduction to Hadoop, Its Ecosystem, and Aligned Technologies5、Hadoop Operations A Guide for Developers and Administrators6、Hadoop Backup and Recovery Solutions w397090770 10年前 (2015-08-11) 20494℃ 2评论56喜欢
消息队列 消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环 w397090770 10年前 (2015-08-11) 8129℃ 2评论17喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》Topic Tool $KAFKA_HOME/bin/kafka-topics.sh,该工具可用于创建、删除、修改、查看某个Topic,也可用于列出所有Topic。另外,该工具还 w397090770 10年前 (2015-06-05) 13938℃ 4评论7喜欢
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 本文在上篇文章(《Kafka设计解析:Kafka High Availability(上)》)基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种 w397090770 10年前 (2015-06-04) 4548℃ 0评论6喜欢
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 10年前 (2015-06-02) 25741℃ 36评论22喜欢
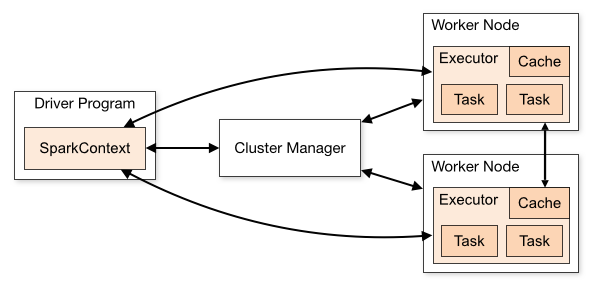
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时 w397090770 10年前 (2015-05-30) 37525℃ 2评论76喜欢
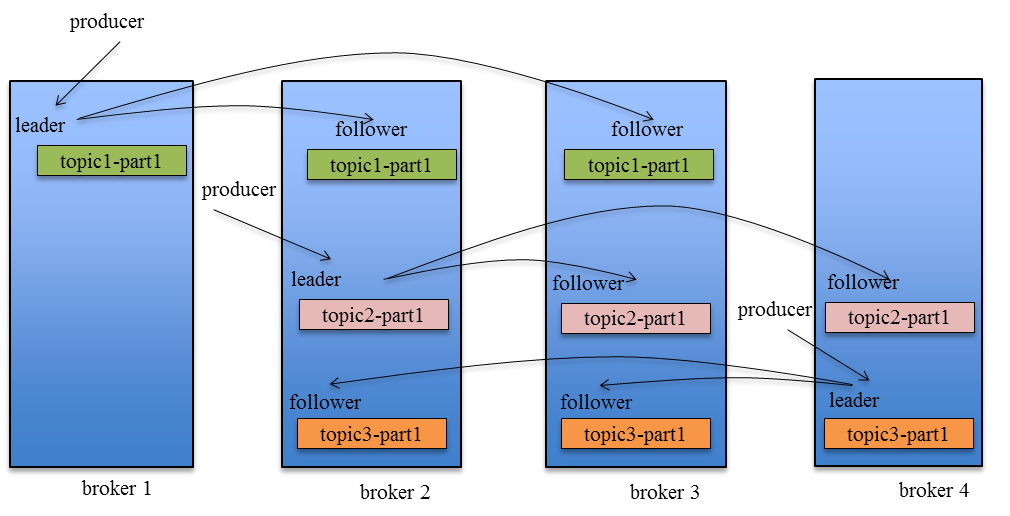
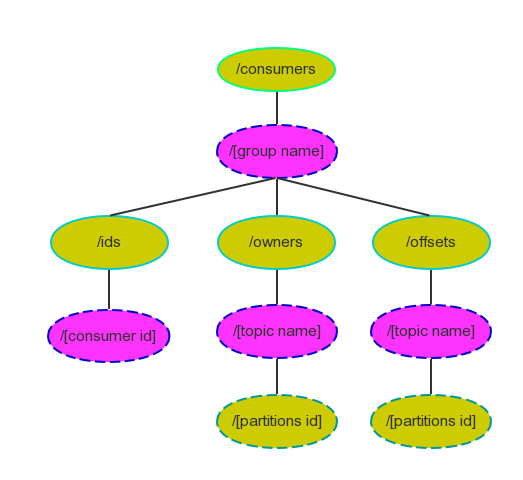
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服 w397090770 10年前 (2015-05-19) 5440℃ 0评论3喜欢


![Hadoop等大数据学习相关电子书[共85本]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/8.jpg)