背景随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。现有方法及问题对于数据同步,我们目前 w397090770 5年前 (2020-01-04) 1202℃ 0评论6喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
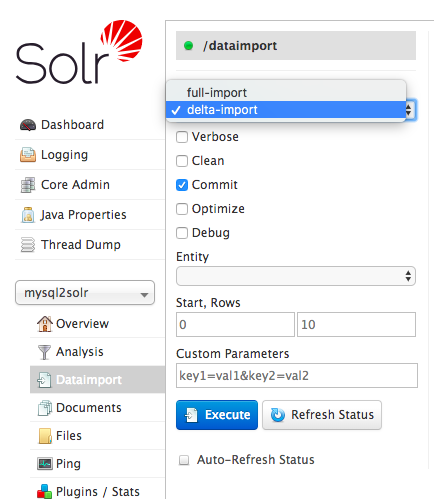
在 这篇 和 这篇 文章中我分别介绍了如何将 MySQL 的全量数据导入到 Apache Solr 中以及如何分页导入等,本篇文章将继续介绍如何将 MySQL 的增量数据导入到 Solr 中。增量导数接口为 deltaimport,对应的页面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop如果我们使用 《将 MySQL 的全量 w397090770 7年前 (2018-08-18) 1650℃ 0评论3喜欢
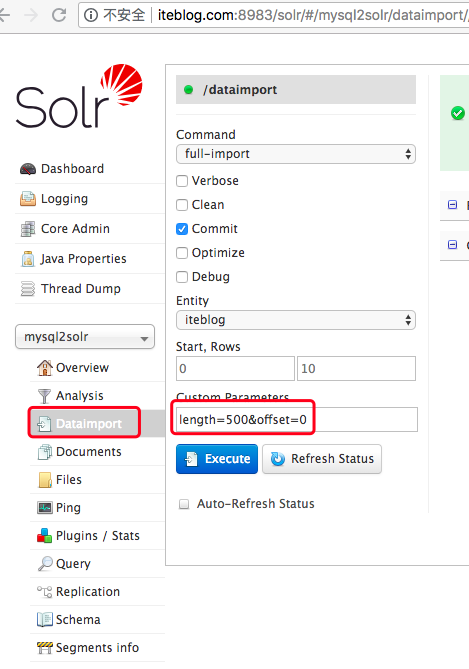
在 《将 MySQL 的全量数据导入到 Apache Solr 中》 文章中介绍了如何将 MySQL 中的全量数据导入到 Solr 中。里面提到一个问题,那就是如果数据量很大的时候,一次性导入数据可能会影响 MySQL ,这种情况下能不能分页导入呢?答案是肯定的,本文将介绍如何通过分页的方式将 MySQL 里面的数据导入到 Solr。分页导数的方法和全量导大部 w397090770 7年前 (2018-08-07) 1493℃ 0评论1喜欢
关于分页方式导入全量数据请参照《将 MySQL 的全量数据以分页的形式导入到 Apache Solr 中》。在前面几篇文章中我们介绍了如何通过 Solr 的 post 命令将各种各样的文件导入到已经创建好的 Core 或 Collection 中。但有时候我们需要的数据并不在文件里面,而是在别的系统中,比如 MySql 里面。不过高兴的是,Solr 针对这些数据也提供了 w397090770 7年前 (2018-08-06) 1989℃ 0评论2喜欢
目前Spark支持四种方式从数据库中读取数据,这里以Mysql为例进行介绍。一、不指定查询条件 这个方式链接MySql的函数原型是:[code lang="scala"]def jdbc(url: String, table: String, properties: Properties): DataFrame[/code] 我们只需要提供Driver的url,需要查询的表名,以及连接表相关属性properties。下面是具体例子:[code lang="scala" w397090770 9年前 (2015-12-28) 37807℃ 1评论61喜欢
这里说明一点:本文提到的解决Spark insertIntoJDBC找不到Mysql驱动的方法是针对单机模式(也就是local模式)。在集群环境下,下面的方法是不行的。这是因为在分布式环境下,加载mysql驱动包存在一个Bug,1.3及以前的版本 --jars 分发的jar在executor端是通过Spark自身特化的classloader加载的。而JDBC driver manager使用的则是系统默认的classloader w397090770 10年前 (2015-04-03) 19173℃ 3评论15喜欢
在本博客的《Spark将计算结果写入到Mysql中》文章介绍了如果将Spark计算后的RDD最终 写入到Mysql等关系型数据库中,但是这些写操作都是自己实现的,弄起来有点麻烦。不过值得高兴的是,前几天发布的Spark 1.3.0已经内置了读写关系型数据库的方法,我们可以直接在代码里面调用。 Spark 1.3.0中对数据库写操作是通过DataFrame类 w397090770 10年前 (2015-03-17) 13568℃ 6评论16喜欢
建议用Spark 1.3.0提供的写关系型数据库的方法,参见《Spark RDD写入RMDB(Mysql)方法二》。 在《Spark与Mysql(JdbcRDD)整合开发》文章中我们介绍了如何通过Spark读取Mysql中的数据,当时写那篇文章的时候,Spark还未提供通过Java来使用JdbcRDD的API,不过目前的Spark提供了Java使用JdbcRDD的API。 今天主要来谈谈如果将Spark计算的结果 w397090770 10年前 (2015-03-10) 36946℃ 5评论33喜欢
如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 11年前 (2014-09-10) 38767℃ 7评论32喜欢