本文来自 IBM 东京研究院的高级技术人员 Kazuaki Ishizaki 博士在 Spark Summit North America 2020 的 《SQL Performance Improvements at a Glance in Apache Spark 3.0》议题的分享,本文视频参见今天的推文第三条。PPT 请关注过往记忆大数据并后台回复 sparksql3 获取。Spark 3.0 正式版在上个月已经发布了,其中更新了很多功能,参见过往记忆大数据的 Ap w397090770 5年前 (2020-07-08) 2555℃ 0评论3喜欢
本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。背景相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 5年前 (2020-07-05) 2207℃ 0评论4喜欢
为期五天的 Spark Summit North America 2020在美国时间 2020-06-22 ~ 06-26 举行。由于今年新冠肺炎的影响,本次会议第一次以线上的形式进行。这次会议虽然是五天,但是前两天是培训,后面三天才是正式会议。本次会议一共有超过210个议题,一如既往,主题也主要是 Spark + AI,在 AI 方面会议还深入讨论一些流行的软件框架,如 Delta Lake、MLflo w397090770 5年前 (2020-07-04) 1906℃ 0评论2喜欢
在 Spark AI Summit 的第一天会议中,数砖重磅发布了 Delta Engine。这个引擎 100% 兼容 Apache Spark 的向量化查询引擎,并且利用了现代化的 CPU 架构,优化了 Spark 3.0 的查询优化器和缓存功能。这些特性显著提高了 Delta Lake 的查询性能。当然,这个引擎目前只能在 Databricks Runtime 7.0 中使用。数砖研发 Delta Engine 的目的过去十年,存储的速 w397090770 5年前 (2020-06-28) 1063℃ 0评论1喜欢
在2020年6月24日的 Spark AI summit Keynote 上,数砖的首席执行官 Ali Ghodsi 宣布其收购了 Redash 开源产品的背后公司 Redash!如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop通过这次收购,Redash 加入了 Apache Spark、Delta Lake 和 MLflow,创建了一个更大、更繁荣的开源系统,为数据团队提供了同类中最好的 w397090770 5年前 (2020-06-26) 1055℃ 0评论3喜欢
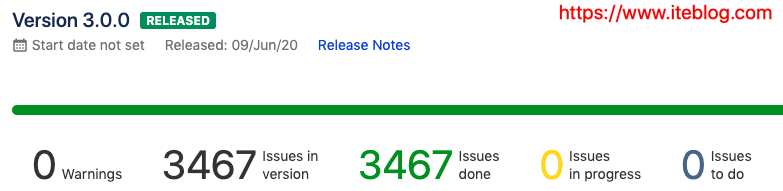
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 5年前 (2020-06-18) 1870℃ 0评论4喜欢
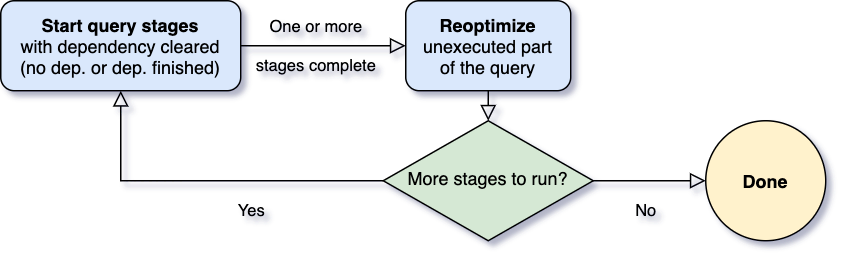
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 5年前 (2020-05-30) 1781℃ 0评论4喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 5年前 (2020-05-30) 989℃ 0评论1喜欢
NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 788℃ 0评论2喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2428℃ 0评论8喜欢